
Sample Object Recognition Theories Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
The goal of object recognition is to determine the identity or category of an object in a visual scene from the retinal input. In naturalistic scenes, object recognition is a computational challenge because the object may appear in various poses and contexts—i.e., in arbitrary positions, orientations, and distances with respect to the viewer and to other objects. The visual information that lands on the retina is a two-dimensional projection of a three-dimensional world. Object recognition is a challenge because many different three-dimensional objects may yield the same two-dimensional projection, and a three-dimensional object in different poses and contexts may produce grossly different two-dimensional projections. Consequently, theories of object recognition must overcome the effect of viewpoint on the appearance of an object. Object constancy, also known as viewpoint-invariant recognition, is achieved when an object is identified as being the same regardless of its pose and other objects in the scene.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
Object recognition involves matching representations of objects stored in memory to representations extracted from the visual image. The debate in the literature concerns the nature of the representation extracted from the image. Broadly, theories of object recognition might be contrasted along five logically independent dimensions (aggregated from Hummel 1994, Hummel and Stankiewicz 1998, Tarr and Bulthoff, 1998, Tarr 1999):
(a) What are the primitive features or parts extracted from the visual image that form the basis of the representation? Features proposed include conjunctions of edge segments, two-dimensional contours, wavelets, local surface patches (with a specified orientation, color, and texture), generalized cylinders (cylindrical shapes whose principal axis and/or cross- sections may be stretched or otherwise distorted), or geons (primitive three-dimensional shapes, described further below).
(b) How stable is the set of features extracted across transformations of the image? The processing that underlies feature extraction might—at one extreme— produce a set of features that depends strongly on the relationship of the viewer to the object, or—at the other extreme—a set of features that is the same for nearly any two views of an object.
(c) How is the configuration of the features encoded? The pose of each feature might be represented with respect to a single point of reference, or the pose of one feature might be specified relative to the poses of other features, possibly in a hierarchy of features of features.
(d) How stable is the representation of a configuration of features across transformations of the image? The representation of the configuration might—at one extreme—depend strongly on the relationship of the viewer to the object, or—at the other extreme—be the same for nearly any two views of an object.
(e) What relationships are used to describe the possible configurations? The relationships might range from qualitative (e.g., abo e) to quantitative (e.g., 1.5 units along the z axis), with intermediate possibilities (e.g., between 2 and 5 units along the z axis).
Although theories of object recognition differ in many other regards, these five dimensions have been the primary focus of theoretical debates and behavioral studies. By situating various theories of object recognition in a space characterized by these five dimensions, contrasts among theories can be made explicit. Because the five dimensions are fairly independent of one another, experiments can be designed to efficiently explore the space of possibilities by considering one dimension at a time.
1. Frames Of Reference
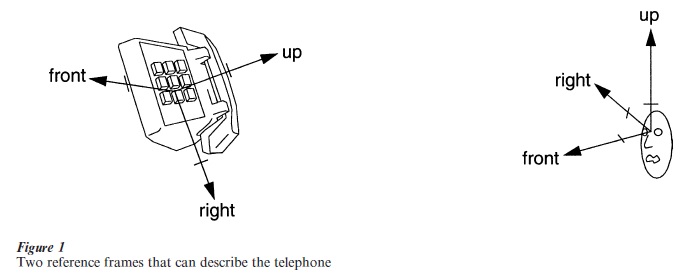
To understand better these five dimensions, it is necessary to introduce the concept of a frame of reference with respect to which visual features and their configurations are encoded. The reference frame specifies the center location, the up-down, left-right, and front-back directions, and the relative scale of axes used to form a description. Figure 1 shows two different reference frames. In terms of the reference frame centered on the telephone, the buttons would be described as being on top of the base and in front of the handle, whereas in terms of the reference frame centered on the viewer, the buttons would be described as being in the back of the base and to the left of the handle. A reference frame prescribed by the gaze, head orientation, and/or torso position of the viewer is known as viewer-based or egocentric. A reference frame prescribed by intrinsic characteristics of an object, such as axes of symmetry or elongation, or knowledge of the object’s standard orientation, is known as object-based or allocentric. A frame of reference makes certain information in the stimulus explicit and therefore readily available for utilization in information processing, and hides other information, making it less available. The stability of a set of features and their configuration across transformations of the image (dimensions a and d above) depend directly on the frame of reference. If an allocentric frame is used to encode features and their configurations, the representation should be stable across transformations of the image, and object constancy should be readily achieved. If an egocentric frame is used, representations of two different views of an object may have little overlap, and object constancy is not a given. It is possible to imagine a frame of reference that is allocentric in some respects (e.g., center position and principal axis) but egocentric in other respects (e.g., left–right and up–down directions), allowing for an intermediate degree of stability.
2. Two Influential Classes Of Theories
Traditionally, theories of object recognition have often been divided into two broad classes, view-based theories and structural-description theories (Hummel and Stankiewicz 1998, Tarr 1999). The key assumption of view-based theories is that the features extracted from the image are viewpoint dependent (dimension b) and that configurations of features encoded are also viewpoint dependent (dimension d). The key assumption of structural-description theories is that the pose of each feature is represented with respect to the reference frames of other features, not to a global reference frame (dimension c). Because the central assumptions of the two classes focus on different dimensions, the classes are not necessarily incompatible. Historically, however, they have been viewed as antagonistic, due in part to the comparison of specific theories of each class, which make particular assumptions along all five dimensions. Several influential theories of each class are described in the following section.
2.1 Structural-Description Theories
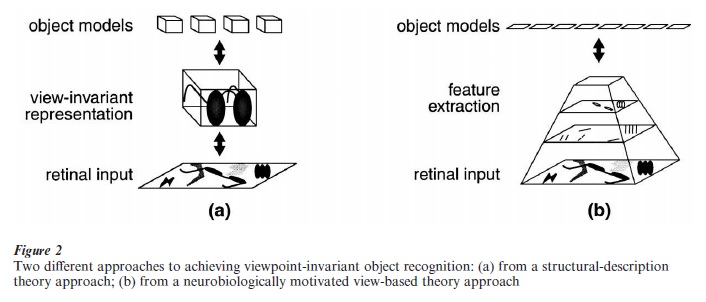
An early structural-description theory of object recognition was outlined by Marr and Nishihara (1978, see also Marr 1982, Pinker 1984). According to this theory, an internal description of an object’s structure is constructed from observed visual features, essentially by transforming the viewer-based retinal input to an object-based representation (Fig. 2a)—a representation of the relationship of object parts to one another, independent of the viewer, using allocentric frames of reference for both the parts and configurations. This transformation solves the problem of viewpoint-invariant recognition, because every view of an object maps to the same object-based representation (ignoring the issue of occluded features).
Since Marr and Nishihara’s seminal work, a variety of structural-description theories have been proposed. Some focus on rigid and two-dimensional objects— either implicitly or explicitly—in which case the object-based representation can be constructed using only image-plane transformations and recognition can be achieved in a straightforward manner by matching the object-based representation to stored templates of familiar objects (Hinton 1981, Humphreys and Heinke 1998, Olshausen et al. 1993, Zemel et al. 1988).
Other structural-description theories in psychology tackle the task of recognizing the sorts of objects encountered in the real world—complex, articulated objects with three-dimensional structure (Biederman 1987, Hummel and Biederman 1992, Hummel and Stankiewicz 1996, 1998). In the style of Marr and Nishihara, these theories operate on structural descriptions that decompose an object into its parts. Structural descriptions can be hierarchical, decomposing parts into parts of parts. The parts are described in terms of a relatively small catalog of primitives. Parts are linked by a small vocabulary of spatial relation- ships that describe how one part is situated with respect to another.
For example, the influential recognition-by-components (RBC) theory of Biederman (1987) invokes 36 primitives, called geons. Geons are detected by non- accidental properties in an image. The attributes of a geon include whether its edges are straight or curved, whether its size is constant, expanded, or contracted, and whether it is symmetric about one or more axes. The relationships among geons are captured by qualitative properties such as whether one geon is larger than another, whether one geon is above, below or to the side of another, and whether the geons are joined end-to-end or end-to-side. Because in principle any shape can be described by the finite set of primitives and relationships, the Biederman theory allows for the representation of novel shapes. Geons and their relationships can be represented by a graph structure, and recognition of an unknown shape can be performed by matching the structure of the un- known shape to the structure of a stored model. A particularly elegant aspect of this theory is that only one stored model is needed to achieve object constancy.
Hummel and Biederman (1992), Hummel (1994), and Hummel and Stankiewicz (1996, 1998) have proposed structural-description theories that differ from the Biederman theory along certain dimensions. All claim that frames of reference for describing features and their configurations are at least partially egocentric. Additionally, the model of Hummel and Stankiewicz (1998) can accommodate quantitative as well as qualitative spatial relationships.
2.2 View-Based Theories
Turning now to view-based theories, consider a naive scheme in which two-dimensional images of viewed objects are stored during learning, and these stored templates are matched pixel-by-pixel to an image containing an object to be recognized. Although this scheme seems hopelessly simplistic, minor variants of the scheme achieve a surprising degree of generalization to novel poses of three-dimensional objects by interpolation between stored poses (Poggio and Edelman 1990, Poggio and Shelton 1999, Siebert and Waxman 1990, Ullman 1989, Weinshall et al. 1990).
View-based theories that focus on explaining human vision go beyond the simple two-dimensional template matching idea by taking into account the coarse-scale anatomy of visual cortex (Fukushima and Miyake 1982, Hubel and Wiesel 1979, Le Cun et al. 1989, Mozer 1991, Perrett and Oram 1998, Reisenhuber and Poggio 1999, Sandon and Uhr 1988, Wallis and Rolls 1997). Specifically, two properties of visual cortex are generally deemed relevant. First, visual cortex is hierarchically organized, with simple, low-order, viewspecific feature detectors at the earliest stage of vision, and increasingly complex, higher-order, and viewinvariant detectors at subsequent stages (depicted in Fig. 2b by the pyramid structure). Second, information is processed from many locations in the visual field simultaneously and at many scales and orientations. Rather than being forced to choose a single reference frame, parallelism of the visual system allows multiple transformations of detectors at each stage in the hierarchy. In this framework, the focus of processing is on extracting features that reliably indicate the presence on an object, not on constructing a viewinvariant representation. Nonetheless, a partially view-invariant representation may come to dominate later stages of processing in the service of recognition. A view-based theory may require multiple characteristic stored views to achieve object constancy.
2.3 Contrasting And Unifying The Theories
In recent years, a heated debate has ensued between proponents of view-based and structural-description theories (Biederman and Gerhardstein 1995, Biederman and Kalocsai 1997, Edelman 1997, Edelman and Duvdevani-Bar 1997, Perrett et al. 1999, Tarr 1999, Tarr and Bulthoff 1995). The debate is not between the two classes in terms of their essential claims, because the two classes address orthogonal dimensions in the space of possible theories. Rather, the debate is between a particular family of view-based theories and a particular family of structural-description the-
ories—a view-based theory in which features are coded with respect to a single egocentric reference frame, and a structural-description theory in which structural information about features is explicitly encoded and in an allocentric reference frame. It is in principle possible to develop view-based theories that encode explicit structural information about features (Tarr and Bulthoff 1998), and structural-description theories based on egocentric frames of reference (Hummel and Stankiewicz 1998).
Each class of theories has its strengths. View-based theories are more consistent with the neurobiology of visual cortex and with evidence suggesting the neurobiological and psychological reality of view-tuned representations. Structural-description theories are more flexible in that they can represent novel and complex shapes, they can generalize from single examples, and have the ability to categorize objects as well as recognize individual members of a category. Given the growing understanding that the two classes of theories have complementary strengths and are not fundamentally incompatible, the next few years should see the development of accounts that integrate view-based and structural-description theories.
Bibliography:
- Biederman I 1987 Recognition-by-components: A theory of human image understanding. Psychological Review 94: 115–47
- Biederman I, Gerhardstein P C 1995 Viewpoint-dependent mechanisms in visual object recognition: Reply to Tarr and Bulthoff (1995). Journal of Experimental Psychology: Human Perception and Performance 21: 1506– 14
- Biederman I, Kalocsai P 1997 Neurocomputational bases of object and face recognition. Philosophical Transactions of the Royal Society of London, Series B (Biological Sciences) 352: 1203–20
- Edelman S 1997 Computational theories of object recognition. Trends in Cognitive Science 1: 296–304
- Edelman S, Duvdevani-Bar S 1997 A model of visual recognition and categorization. Philosophical Transactions of the Royal Society of London, Series B (Biological Sciences) 352: 1191– 1202
- Fukushima K, Miyake S 1982 Neocognitron: A new algorithm for pattern recognition tolerant of deformations and shifts in position. Pattern Recognition 15: 455–69
- Hinton G E 1981 A parallel computation that assigns canonical object-based frames of reference. Proceedings of the Seventh International Joint Conference on Artificial Intelligence Morgan Kaufmann, Los Altos, CA, pp. 683–5
- Hubel D H, Wiesel T N 1979 Brain mechanisms of vision. Scientific American 241: 150– 62
- Hummel J E 1994 Reference frames and relations in computational models of object recognition. Current Directions in Psychological Science 3: 111– 6
- Hummel J E, Biederman I 1992 Dynamic binding in a neural network for shape recognition. Psychological Review 99: 480– 517
- Hummel J E, Stankiewicz B J 1996 An architecture for rapid, hierarchical structural description. In: Inui T, McClelland J (eds.) Attention and performance XVI: Information Integration in Perception and Communication. MIT Press, Cambridge, MA, pp. 93–121
- Hummel J E, Stankiewicz B J 1998 Two roles for attention in shape perception: A structural description model of visual scrutiny. Visual Cognition 5: 49–79
- Humphreys G W, Heinke D 1998 Spatial representation and selection in the brain: Neurophychological and computational constraints. Visual Cognition 5: 9– 47
- Le Cun Y, Boser B, Denker J S, Hendersen D, Howard R E, Hubbard W, Jackel L D 1989 Backpropagation applied to handwritten zip code recognition. Neutral Computation 1: 541–51
- Marr D 1982 Vision. Freeman, San Francisco
- Marr D, Nishihara H K 1978 Representation and recognition of the spatial organization of three shapes dimensional. Proceedings of the Royal Society of London, Series B (Biological Sciences) 200: 269–94
- Mozer M C 1991 The Perception of Multiple Objects: A Connectionist Approach. MIT Press Bradford Books, Cambridge, MA
- Olshausen B A, Anderson C H, van Essen D C 1993 A neurobiological model of visual attention and invariant pattern recognition based on dynamic routing of information. Journal of Neuroscience 13: 4700 –19
- Perrett D I, Oram M W 1998 Visual recognition based on temporal cortex cells: Viewer-centred processing of pattern configuration. Zeitschrift fuer Naturforschung (C) 5: 518–41
- Perrett D I, Oram M W, Hietanen J K, Benson P J 1999 Issues of representation in object vision. In: Farah , Ratcliff G (eds.) The Neuropsychology of High-level Vision: Collected Tutorial Essays. Erlbaum, Hillsdale, NJ, pp. 33–61
- Pinker S 1984 Visual cognition: A introduction. Cognition 18: 1–63
- Poggio T, Edelman S 1990 A network that learns to recognize 3D objects. Nature 343: 263–6
- Poggio T, Shelton C R 1999 Machine learning, machine vision, and the brain. AI Magazine 20: 37–55
- Reisenhuber M, Poggio T 1999 Hierarchal models of object recognition in cortex. Nature Neuroscience 2: 1019–25
- Sandon P A, Uhr L M 1988 An adaptive model for viewpoint invariant object recognition. In: Proceedings of the Tenth Annual Conference of the Cognitive Science Society. Erlbaum, Hillsdale, NJ, pp. 209–15
- Seibert M, Waxman A M 1990 Learning aspect graph representations from view sequences. In: Touretzky D S (ed.) Advances in Neural Information Processing Systems. Morgan Kaufmann, San Mateo, CA, Vol. 2, pp. 258–65
- Tarr M J 1999 News on views: Pandemonium revisited. Nature Neuroscience 2: 932–5
- Tarr M J, Bulthoff H H 1995 Is human object recognition better described by geon structural descriptions or by multiple views?
- Comment on Biederman and Gerhardstein (1993). Journal of Experimental Psychology: Human Perception and Performance 21: 494–1505
- Tarr M J, Bulthoff H H 1998 Image-based object recognition in man, monkey, and machine. Cognition 69: 1–20
- Ullman S 1989 Aligning pictorial descriptions: An approach to object recognition. Cognition 32: 193–254
- Wallis G, Rolls E T 1997 Invariant face and object recognition in the visual system. Progress in Neurobiology 51: 167–94
- Weinshall D, Edelman S, Bulthoff H H 1990 A self-organizing multiple-view representation of 3D objects. In: Touretzky D S (ed.) Advances in Neural Information Processing Systems. Morgan Kaufmann, San Mateo, CA, Vol. 2, pp. 274–81
- Zelmel R S, Mozer M C, Hinton G E 1988 TRAFFIC: Object recognition using hierarchical reference frame transformations. In: Touretzky D (ed.) Advances in Neural Information Processing Systems. Morgan Kaufmann, San Mateo, CA, Vol. 2, pp. 266 –73
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality