
View sample Suprasegmentals Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our custom writing service for professional assistance. We offer high-quality assignments for reasonable rates.
Suprasegmental features of speech are associated with stretches that are larger than the segment (whether vowel or consonant), in particular pitch, stress, and duration (Lehiste 1970). Respectively, these terms refer to the sensation of higher and lower tone, to the prominence patterns of words, and to durational differences between segments, whether between different segments or between pronunciations of the same segment in different contexts. In general, speech can be analyzed from two points of view: the phonetic reality, most readily accessible as the acoustic speech wave form, but equally present in the articulatory behavior of the speaker and the perceptual analysis of the auditory signal by the listener, and the discrete mental representation which serves as the set of instructions from which the phonetic signal is built by the speaker. One way of structuring a discussion of this topic is to take these three suprasegmental features as a point of departure, consider their somewhat varied manifestations at the different stages of the speech chain, that is, their articulation, acoustics, and perception, and tabulate the ways in which they function in languages. This approach would reveal that the terms pitch, stress, and duration do not refer to concepts at a single stage in the speech chain. Stress is largely a phonological notion (cf. section on the foot). Pitch is a perceptual concept, the articulatory correlate of pitch being rate of vocal cord vibration, and the acoustic correlate, in the usual case, being periodicity in the speech signal, the repetition of nearly the same pattern of vibration. Another approach takes the phonological representation as the starting point, and refer to the phonetic features that are involved in their realization, which is what will be done here.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
Recently, the phonological object of study that corresponds to the traditional suprasegmental features has come to be known as prosody. Prosodic structure has two components. First, there is a hierarchical compartmentalization of the segment string into phonological constituents, like the syllable and the intonational phrase, called the prosodic hierarchy (Selkirk 1978, Nespor and Vogel 1986, Hayes 1989). Second, overlaid on the string of segments, there is a tonal structure, which is synchronized in specific ways with the segmental and prosodic structure (Pierrehumbert and Beckman 1988, Ladd 1996). All languages have both of these structural components.
1. The Prosodic Hierarchy
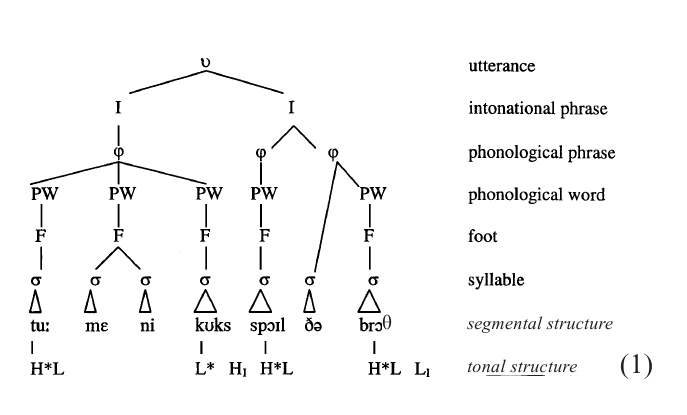
The phonological structure of an English sentence like Too many cooks spoil the broth does not just consist of a linear segment string [tu meni koks spil be brrco]. The segments are grouped in a hierarchical set of constituents, where constituents at each rank include those of the rank below. There are seven syllables and five feet (Too, many, cooks, spoil, and broth), each of which is also a phonological word; next, there are three phonological phrases (Too many cooks, spoil, and the broth), two intonational phrases (Too many cooks and spoil the broth), and one utterance (Too many cooks spoil the broth).
The foot captures the notion stress. It is a constituent which in the unmarked case consists of a stressed (or strong: S) and an unstressed (or weak: W) syllable, with languages choosing between trochees (S–W) and iambs (W–S). Often, there are restrictions on segmental contrasts in weak syllables, as in Russian, which has five vowels in stressed syllables but only three in unstressed syllables, and in English, which, depending on the variety, has between 13 and 17 monophthongs and diphthongs in stressed syllables, but only three in unstressed syllables (cf. the final syllables in villa, folly, and fellow; Bolinger 1986, p. 347ff.). Commonly, feet are disyllabic. English, a trochaic language, also has marked feet: a monosyllabic foot occurs in cooks and manifest, where -fest occurs after the disyllabic foot mani-; a trisyllabic foot occurs in cavity and university, where the foot -versity occurs after the disyllabic foot uni-. One of the feet of a word is selected to bear primary stress or main stress [ ], the others having secondary stress [ ]. In English, the primary stress is on the rightmost branching foot, as shown by mani fest, university, and Apa lachi cola, but there are many exceptions, like sala mander, perso nnel. Other languages will make other choices. For instance, Bengali, Czech, Finnish, Icelandic, and Pintupi (Australia) always have the primary stress on the first trochee, that is, all words have initial stress, and secondary stresses may be found on alternate syllables, as in Pintupi [ juma i ka mara tju aka] ‘because of mother-inlaw.’ Foot structure assignment may take place left-to-right, as in Pintupi, where odd-syllabled polysyllabic words end in trisyllabic feet, or right-to-left, and instead of a trochee, the foot may be an iamb. In quantity-sensitive languages, long vowels, or long vowels and closed syllables, do not tolerate being in a weak position, and will thus interrupt any regular count through the word. Hawaiian is a quantity-sensitive trochaic language which assigns feet right-toleft, so that [ko hola] ‘reef ’ has penultimate stress, but [ koho la ] ‘whale’ has final stress. When a language has extrametricality, the regularities obtain minus an edgemost (usually final) syllable. Finally, within limits imposed by the typology of the language, some words may have exceptional stress, in which case the foot structure is marked in the underlying representation. English is a quantity-sensitive, trochaeic, right-to-left language with extrametricality and exceptions (cf. Hayes 1985).
Stressed positions in phonological representations not only attract more phonological contrasts, as the English and Russian vowel systems show, but also lead to less casual articulation than unstressed positions. The intensity at the higher end of the frequency spectrum tends to fall off less steeply (even spectral balance), spectral targets of vowels are approached more closely (less owel reduction), and their duration is longer; overall intensity measures like RMS intensity appear to be unreliable indicators of stress (e.g., Beckman 1986, Sluijter 1995). Stressed syllables also have different pitch characteristics from unstressed syllables. These are caused by the fact that stressed syllables attract intonational pitch accents, tones, or tone complexes, which (together with boundary tones, see below) make up the tonal structure of the language. The presence of a pitch accent on a stressed syllable makes that syllable accented, as indicated by capitalization. When said in isolation, an English word like theory is pronounced THEory, while there may also be a pitch accent on a secondary stress before the primary stress, so that Japanese will be JapaNESE or JAPaNESE. English has a number of different pitch accents, like H*, L*, L*H, etc., where the starred tone is time-aligned with the stressed syllable. While in isolation, the pronunciation will be THEory, in SET theory the syllable theis unaccented, because in compounds only the first constituent is accented. Other reasons for deaccentuation are stress shift and lack of focus (see below).
A frequently applied diagnostic for the phonological word is syllabification, more specifically the extent to which consonants syllabify as onsets with vowels to their right. The phonological word may be smaller or larger than the morphological word. In many languages, it is smaller in compounds, where each constituent is a separate syllabification domain (e.g., English cat’s eye syllabifies as [´kæts. ai], not as *[´kæt. sai]); it is larger in cases of cliticization (e.g., English What is he [´wct.si] saying? ). The phonological phrase may determine the distribution of accents, favoring first and last accents. Although TOO MAny! will have two accents, TOO many COOKS is likely to lose the pitch accent on many.
The term stress shift is applied to cases where such rhythmic deaccentuation leads to the sole presence of a pitch accent on a foot with secondary stress, as in JAPaNESE, but JAPanese FURniture (Gussenhoven 1991). The intonational phrase typically comes with boundary tones at its edges. For instance, the intonational phrase Too many cooks might end with a H-tone, pronounced after the pitch accent on cooks. Boundaries of this type are often felt to correspond with a comma in writing. The utterance, finally, roughly corresponds with the intuitive notion of spoken sentence. Instead of, or in addition to, the intonational phrase, the phonological phrase and the utterance may also be provided with boundary tones.
In (1), a full prosodic representation is given, together with frequently used symbols; the subscript I in the tonal structure indicates a boundary tone.
The choice of tones is one of many possible combinations, each of which will produce a different intonation contour. At the higher ranks, some optionality also exists in the phrasing, depending on style, constituent length, and sometimes language variety. Thus, spoil the broth may form a single phonological phrase, as shown by varieties like American English which allow stress shift in verb-object combinations, like MAINtain ORder (cf. ORder to mainTAIN). The sentence can also be pronounced as a single intonational phrase.
The constituents in the prosodic hierarchy often define the context of segmental restrictions. For instance, syllable-final obstruents are voiceless in Turkish; voicing of Dutch [s] occurs between a sonorant segment and a vowel if [s] occurs at the end of a prosodic word; in Kimatuumbi, all vowels are shortened except any long vowel that ends up in the last word in the phonological phrase. Higher rank prosodic constituents in particular tend to undergo (phonetic) preboundary lengthening, which is usually confined to the final syllable.
There is no consensus on how many prosodic constituents there are, in part due to apparent differences between languages. For instance, Japanese has an accentual phrase, which seems to lie halfway between PW and .A clitic group has been claimed for Italian and English, for instance, providing a level between PW and φ. A constituent below the syllable is the mora, which captures quantity contrasts. A syllable with a short vowel has one mora, one with a long vowel or diphthong two. A geminate consonant adds one mora, a single consonant none. Disyllabic words in Finnish, which has quantity contrasts in vowels and consonants in stressed syllables, may have two moras (CVCV), three (CVVCV or CVCCV), or four (CVV-CCV). Exhaustive parsing refers to the ideal situation in which each constituent includes all and only the segments included in the constituents of the rank below. For instance, the inclusion of [m] in the syllable [m ] implies that it is also included in the foot [meni] and the phonological word [meni] (which makes the structure distinct from that of Tomb any). A violation occurs in (1) for the syllable the, which lacks the normal properties of F and PW, and is directly included in the .
2. Tonal Structure
The tonal structure can be thought of as a string of tones arranged in parallel to the segmental structure provided by the string of consonant and vowels, that is, as an autosegmental representational tier (Goldsmith 1976). It varies greatly across languages. There are two ways in which a typology can be set up, a morphosyntactic one (‘How do tones signal what words, phrases, or clause types are used?’) and a phonological one (‘Where are tones located and how many contrasting tones are there?). A frequently applied morphosyntactic criterion is whether the tone(s) enter into the specification of (also segmentally specified) words or morphemes. If they do, the language is a tone language, examples of which can readily be found in Asia (Sino-Tibetan languages, Japanese), Africa (Bantu languages, Khoi-San languages, Nilo-Saharan languages), and many languages in the Americas. Examples of tonal distinctions ([´] = low, [´] = high, [–] = mid) of this kind are Japanese [hası] ‘chopsticks,’ [hası] ‘bridge,’ [hası] ‘end,’ Mandarin (Sino-Tibetan) [ma ] ‘mother,’ [ma ] ‘hemp,’ [ma ] ‘horse,’ [ma ] ‘vituperate,’ Mamvu [maaka] ‘type of seasoning’ vs. [maaka] ‘cat.’ Frequently, tone is involved in the morphology in particular in languages spoken in Africa, as shown by Makonde [nındı taleeka] ‘I cooked’ vs. [nında taleeka] ‘I will cook’ and Mamvu [afu] ‘man,’ [afu] ‘men’ (all examples from Kaji 1999). About half of the languages in the world fall in this class (Maddieson 1978). If they do not use tone to determine the identity of morphemes, they are not tone languages; sometimes non-tone languages are referred to as intonation languages, but this term incorrectly suggests that tone languages do not use tone intonationally.
In nontone languages, tones are used to indicate discourse meanings, like ‘interrogativity,’ ‘finality,’ ‘continuation,’ etc. This is illustrated by English There’s no cutlery: when cutlery is spoken with a low-to-high rise, the sentence is meant as a question; with falling-rising pitch it could either be a reminder or again a question, while a high-to-low fall signals a statement of fact. Many tone languages use tone in this intonational way, like Japanese, which distinguishes a L-tone in statements from a H-tone in questions utterance-finally. By contrast, some languages, like the Western Aleut dialect of Unangan, would appear to restrict their tonal structure to the insertion of specific initial and a final boundary tones at the beginning and end of every intonational phrase, and perhaps one more at the end of the utterance. Here, the only function of tone is to mark the phrasing. There are thus widely varying functional claims made by the phonologies of different languages on pitch variation. Not all acoustic variation, however, is due to differences in phonological representation. Speakers of all languages will also use pitch variation to signal universal meanings. Variations in overall pitch range, for example, may signal such general meanings as surprise, interest, emphasis, etc., many of which have an ethological origin (Ohala 1994).
A phonological typology of tone might be based on tonal density: how many locations are specified for tone, that is, have tonal associations? In other words, languages differ in the selection of the tone bearing unit: in the ‘densest’ case they specify every mora for tone, and in the sparsest case they just mark the phrasing. When more than one tone is associated with a syllable, like HL or LH, the combination is known as a contour tone, while a single tone is a le el tone.
After edges of prosodic constituents, stressed syllables rank as a popular location for tone. In (1), all tones are intonational. The Venlo Dutch sentence (2a) also has intonational boundary tones and an intonational pitch accent (H*), but the second H-tone on the word for ‘play’ is a lexical tone, whose presence makes this word distinct from (the segmentally identical) word for ‘rinse,’ given in (2b). The difference comes out in that the syllable [spφ] has high pitch in (2a) but falling pitch in (2b), where the boundary tone spreads to the second mora of the stressed syllable. Thus, although (2a) and (2b) differ in pitch, they have the same intonation.
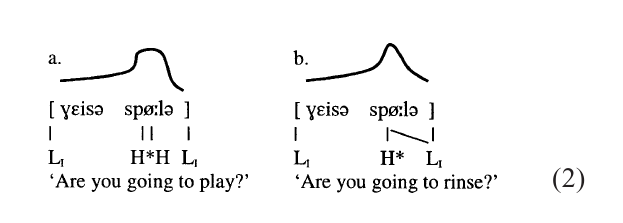
Languages that, like the Dutch dialect of Venlo, restrict the lexical tonal contrasts to one per word are called pitch accent languages. (Observe the different meaning of ‘pitch accent’ from that given earlier.) Most of these use the syllable with word stress for this location (metrical pitch accent languages), but the location may also be arbitrary, as is in Japanese (lexical pitch accent languages), where the HL-tone complex is located on one of the syllables of accented words. (Unaccented words are unaccented because they—again arbitrarily—do not have this tone complex on any of their syllables.) In Japanese, the accented syllable has none of the phonetic characteristics of stressed syllables (Beckman 1986). Metrical pitch accent languages can also be found in Europe (Norwegian, Swedish, Central Franconian dialect of German, Limburgian dialect of Dutch, Serbocroatian dialects, Basque dialects, Lithuanian; cf. van der Hulst 1999).
The number of tonally specified locations is usually greater than the number of tones. For instances, moras may be specified by a spreading tone: when a tone spreads (left or right), it specifies more than one tone bearing unit. Also, suffixes may have a tone with the opposite value from the tone of the stem ( polar rule), etc. Moras, syllables, or words that are unspecified for tone are pronounced with a pitch that results from an interpolation between the two pitches specified at the nearest locations to the right and to the left. If a language just has an initial L- tone and a final H-tone in the intonational phrase, for instance, the pitch in the phrase may begin low, and rise towards the end. In fact, the pitches indicated in the unaccented Japanese word for ‘end’ are due to the interpolation between an initial LH tone complex of the accentual phrase and a final L-tone of the utterance, and both pitches are thus due to intonational tones, the mid pitch on the second syllable being a curtailed interpolation between H and L.
A second typological question concerns the number of contrasting tones. While most languages, and most probably all nontonal languages, contrast H with L, some languages have three or even four contrasting level tones.
Both the prosodic hierarchy and the autosegmental tonal structure are nonlinear forms of representations, differing radically from the linear segment string given at the beginning of Sect. 1.
3. The Expression Of Focus
Languages frequently exploit prosodic structure for the expression of focus, the marking of information status in sentences. Languages appear to vary in the kind of information status which is marked (counter presupposition, counter-assertiveness, topichood), but a common operationalization of focus is the answer to a question. Thus, if Sue doesn’t like cheese is an answer to Who doesn’t like cheese?, the focus is Sue, since it expresses the information the question seeks to elicit, while the rest of the sentence is outside the focus. However, if it is an answer to Why are you changing the menu?, the whole sentence is focus. The latter type is called broad focus, sentences with unfocused constituents having narrow focus (Ladd 1996). Prosodic encoding of focus distribution may take several forms. One is phrasing, in which case the beginning or end of a medium-rank prosodic constituent coincides with, respectively, the beginning or end of the focus constituent (e.g. Japanese, Bengali). Some languages use different types of intonational pitch accent for focused and non-focused parts of sentences (e.g., Italian), while others deaccent non-focused parts (Germanic), or de-accent and use different pitch accents for broad and narrow focus (Bengali) (Hayes and Lahiri 1991). Lastly, accentuation may signal other meanings than focus. If sentence (1) were to lose its accent on spoil, it would lose its implicit conditional status (‘If there are too many cooks …’) and imply that the number of cooks that actually end up spoiling the broth is too large.
Bibliography:
- Beckman M E 1986 Stress and Non-Stress Accent. Foris, Dordrecht, The Netherlands
- Bolinger D 1986 Intonation and Its Parts: Melody in Spoken
- Stanford University Press, Stanford, CA
- Goldsmith J 1976 Autosegmental phonology. Doctoral dissertation, MIT
- Gussenhoven C 1991 The English Rhythm Rule as an accent deletion rule. Phonology 8: 1–35
- Hayes B 1989 The prosodic hierarchy in meter. In: Kiparsky P, Youmas G (eds.) Rhythm and Meter. Academic Press, Orlando, FL, pp. 201–60
- Hayes B 1995 Metrical Stress Theory. University of Chicago Press, Chicago
- Hayes B, Lahiri A 1991 Bengali intonational phonology. Natural Language and Linguistic Theory 9: 47–96
- Hulst H van der 1999 Word Prosodic Systems in the Languages of Europe. Mouton de Gruyter, Berlin
- Hyman L M in press Tone systems. In: Haspelmath M, Konig E, Oesterreicher W, Raible W (eds) Language Typology and Language Universals: An International Handbook. Mouton de Gruyter, Berlin
- Kaji S 1999 (ed.) Proceedings of the Symposium on Cross-linguistic Studies of Tonal Phenomena: Tonogenesis, Typology, and Related Topics. Institute for the Study of Languages and Cultures of Asia and Africa (ILCAA), Tokyo University of Foreign Studies
- Ladd D R 1996 Intonational Phonology. Cambridge University Press, Cambridge, UK
- Lehiste I 1970 Suprasegmentals. MIT Press, Cambridge, MA
- Maddieson I 1978 Universals of tone. In: Greenberg J (ed.) Universals of Human Language, Vol. 2: Phonology. Stanford University Press, Stanford, CA, pp. 335–65
- Nespor M, Vogel I 1986 Prosodic Phonology. Foris, Dordrecht, The Netherlands
- Ohala J J 1994 The frequency code underlies the sound-symbolic use of voice pitch. In: Hinton L, Nichols J, Ohala J J (eds.) Sound Symbolism. Cambridge University Press, Cambridge, UK
- Pierrehumbert J, Beckman M E 1988 Japanese Tone Structure. MIT Press, Cambridge, MA
- Selkirk E O 1978 On prosodic structure in relation to syntactic structure. In: Fretheim T (ed.) Nordic Prosody, Vol. 2. TAPIR, Trondheim, Norway, pp. 111–40
- Sluijter A 1995 Phonetic Correlates of Stress and Accent. Foris, Dordrecht, The Netherlands
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality