
Sample Letter And Character Recognition Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
Letters are basic constructional units in alphabetic scripts that are used to form words; in writing these words are entities which are marked by spaces. How has letter recognition been studied? What are the main results obtained and the major models proposed? These questions are considered in the first part of this research paper. In contrast to those scripts constructed on an alphabetic principle where symbols (i.e., letters) are made to correspond to sounds in speech, other scripts, such as Chinese, have been developed following a logographic principle, in which symbols mainly and directly encode meaning. Characters are distinct orthographic units in Chinese. Although there are notable differences between letters and characters, they share certain crucial properties, among them that both characters and letters have names, are used to form words, and are the first things that users of the corresponding script start to learn when learning how to read and write. The second part of the paper addresses how characters are processed in recognition.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
1. Letter Recognition
Different alphabetic scripts, such as Hebrew and English, make use of different sets of letters. We shall confine the discussion here to the English letters, because a good deal of research is available on them.
1.1 How Has Letter Recognition Been Studied And What Are The Main Results?
Early research on letter recognition aimed at identifying a set of features used in distinguishing among letters. But what is a feature? A feature (e.g., horizontal straight, closed curve, etc.) can be considered as a specific component which can appear in combination with other components to form different letters. One way to find a possible feature set for letters is to observe systematically and analyze patterns of responses when asking people to make matching or same–different judgments on serially or simultaneously presented letters. It is typically found that considerable confusions are made between certain pairs of letters such as N and M, M and W, E and F, P and R, and Q and O, presumably because these pairs of letters share certain features (for an example of the features of capital letters and a review of related research see, e.g., Gibson 1969).
A widely used paradigm in studying letter recognition is to ask people to identify letters that are displayed very rapidly (e.g., for 50 ms or less) on a tachistoscope (i.e., a device that allows researchers to show visual stimuli for a short, fixed amount of time). A common finding in the studies using the tachistoscopic procedure is that people are more likely to confuse letters with similar features, such as E and F, than those with distinctive features, such as E and Q (e.g., Rumelhart 1970). This result suggests that people are possibly engaged in such activities as feature detection and feature analysis in letter recognition and that these perceptual activities play an important role in recognizing a letter.
Letter recognition has also been studied by using a visual search task. In Neisser’s (1963) classic research, for instance, he asked people to search an array of letters for a particular target and found that search performance for the target (e.g., Z) was slower when the array was made up of letters with features similar to the target (e.g., X and V, consisting of straight lines) than when it consisted of letters with features distinctive from the target (e.g., O and G, containing rounded features). This result confirms the idea that features are used in recognizing letters.
Apart from studying how individual letters are recognized, researchers have also investigated the way in which letters are processed in context. This topic has been investigated since Cattell’s study (1886) and has attracted much research interest over several decades for at least three reasons. First, letters are more often seen in a word context than in isolation. Second, there is good evidence to show that different processes are involved in the two situations. Finally, this topic is related to significant theoretical issues, such as the nature of the processes involved in reading and the relationship between the processing of letters and words. Perhaps the most well-known work on investigating letter recognition in context is Reicher’s (1969) study, in which he adopted the tachistoscopic procedure previously mentioned to show three types of stimuli: four-letter words (e.g., WORK), four-letter nonwords (OWRK), or single letters (K). Immediately following the display of a stimulus item, a forced- choice recognition test (e.g., D/K or D/K) was given to the participants to judge which one of the two alternative letters had appeared in the specified position in the original stimulus. Reicher discovered that letters were recognized better in the context of a word than in the context of a nonword letter string or in no context at all (i.e., when presented individually), indicating that (a) letter recognition can be affected by context-dependent processes, and (b) word identification may not need to be based on letter-by-letter recognition. This word superiority effect is well known, for it provides an important, empirical basis in the development of modern models of letter recognition, a topic which will be covered in the next section.
It is worth noting here that the contextual effects in letter perception have also been investigated by researchers using a letter detection paradigm in situations more closely resembling the conventional reading environment. Healy and Drewnowski (1983), for example, asked people to read a prose passage and to detect every instance of a target letter, such as t or T. They found that people made many more letter detection errors on words (e.g., the) than on misspelled, consequently meaningless words (e.g., thd ). This word inferiority effect not only confirms the idea that the basic encoding units in skilled conventional reading are not likely to be individual letters, it also indicates, in conjunction with the word superiority effect previously mentioned, that the effect of familiar context on letter recognition depends on task and can either be facilitative or inhibitory.
1.2 Major Models Proposed
A classic model for letter recognition is the one proposed by Selfridge (1959), called ‘pandemonium.’ This model involves four levels of ‘demons,’ which detect and analyze the properties of a visual input. The stimulus is first scanned and encoded by image demons to produce the mental representation of the stimulus (i.e., an image). The image is then processed by feature demons, each of which searches for a specific feature. Once a feature demon finds the searched-for feature, it calls out to cognitive demons at the next level of the system. Each of these cognitive demons corresponds to one single letter in English, and it pays special attention to a particular set of feature demons. Cognitive demons call out when they hear the yelling from the corresponding features demons. Finally, a decision demon listens to the noises produced by the cognitive demons and makes the final decision regarding the identity of the stimulus based on which cognitive demon is making the loudest noise, indicating that all necessary component features of the cognitive demon have been detected.
Feature-analysis models of letter perception, such as the pandemonium model proposed by Selfridge, were popular in the early days of studying letter recognition. This type of model emphasizes the role of features in recognition but de-emphasizes the processing roles played by certain factors, such as context, expectations, and perceptual experience. The recognition and correction of this problem has stimulated the development of contemporary models of letter recognition that incorporate both bottom-up processes, such as feature detection and analysis, and top down processes, such as expectations and context. A well-known example of such models is the interactive activation model of McClelland and Rumelhart (1981).
The interactive activation model has the following major assumptions. First, there are processing units at three levels: feature, letter, and word. Second, recognition processing occurs simultaneously at different levels (i.e., parallel processing). Third, there can be bidirectional information processing between two neighboring levels (i.e., interactive processing). For instance, top-down influences can be passed along the word level down to the letter level. Fourth, there are both excitatory and inhibitory connections between levels, whereas only inhibitory connections exist within a level.
This type of interactive activation model can easily account for the word superiority effect previously mentioned by allowing interactive activation between levels. In other words, word units that have been activated can increase activation for their constituent letters at the letter level. Consequently, under the tachistoscopic task of Reicher (1969) where only a single letter string or a letter is shown at one time, letters embedded in words can in principle receive feedback from the activated words at the word level and have a better chance to be activated than those in nonword strings or in isolation.
The word inferiority effect aforementioned can also be understood with the multilevel, parallel processing mechanism proposed in the interactive activation model. The word inferiority effect is typically demonstrated in conventional reading situations where many words are shown at once. In order to read for comprehension, readers not only need to identify each individual word in a text, they also need to integrate the meanings of those words to form a coherent understanding. Thus, a good strategy is to start to process the next word in the text as soon as possible once a given word has been recognized even if some of its constituent letters have not been processed to the level of identification. Consequently, letter detection can be disrupted by word context in conventional reading, as demonstrated by Healy and Drewnowski (1983).
2. Character Recognition
Thus far we have examined what has been done over the past decades in understanding the processes involved in letter recognition. An interesting question one might ask at this point concerns whether (or the extent to which) we can apply what we have learned about the processing of sub-word units to other nonalphabetic scripts, such as Chinese. In this section, we will consider how distinctive orthographic units in Chinese (i.e., characters) are processed in recognition.
2.1 Main Properties Of Chinese Characters
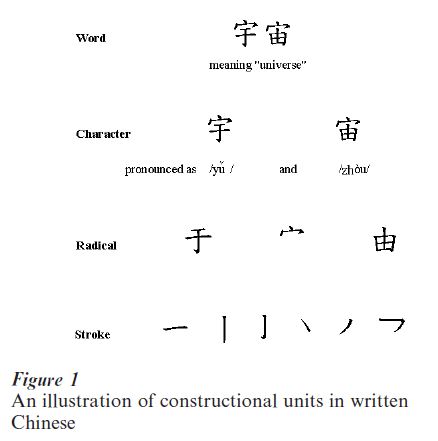
Each Chinese character is made up of strokes, radicals (i.e., certain combinations of strokes), simple characters (i.e., characters that cannot be further segmented into radicals), or a combination of these components in a constant, square-shaped region (see Fig. 1 for an illustration of constructional units in written Chinese). Hence, different characters can differ in number of strokes (e.g., some characters, such as and , have only one or two strokes, but others, such as and , are formed by more than two dozen strokes), in number of radicals (e.g., , meaning moon, and , friend ), or in manner of construction (e.g., , tangerine, is made up of two simple characters and along a horizontal dimension, while , unspecified, is formed by the same components but in a vertical manner).
Chinese characters are typically monosyllabic. Since there are far fewer syllables (about 1,300 in Mandarin Chinese) than there are characters that are commonly used (about 5,000), the degree of homophony in the language is very high. Moreover, about 80 percent of Chinese characters consist of compound characters made up of two components, one of which (the signific) provides a categorical cue to the meaning of the character; and the other component (the phonetic) may cue in an all-or-none fashion the pronunciation of the character. However, the phonetic parts in these compound characters are themselves characters, having their own pronunciation (thus providing phonetic cues) and meanings (typically different from the meanings of the characters in which they are embedded). The cues they provide to pronunciation are neither constant, as some may function as the phonetic part in certain characters and the signific in others, nor reliable, in that less than 30 percent of the phonetic parts provide the correct pronunciation for commonly used characters. In other words, a notable property of the Chinese script is that is has an opaque scriptspeech relationship.
Furthermore, being constructed following the logographic principle, Chinese characters are basically morphemes, and more than 60 percent of Chinese words are comprised of two or more characters. Since the majority of characters can join others to form multiple-character words with drastically different meanings, the meaning of a character can be highly context-dependent (for relevant research and discussion on this issue see, e.g., Chen 1992). For example, the character can be used to form such distinctive words as (health), (peanut), (life), (to grow), (operator), and so on. In fact, we can use about 2,500 characters to form some 16,000 different words which can account for about 99 percent of the material in a Chinese corpus of about one million words (Liu et al. 1975).
2.2 Cognitive Processing Of Characters
Research on character recognition has had a relatively short history compared to the study of letter recognition. In fact, although some progress has been made over the past two decades, what we have learned about the processing of characters is still very limited in comparison with what we know about letter recognition. The research on the cognitive processing of characters has usually been conducted using methods and techniques similar to those used in English research, aiming to understand the processes underpinning character recognition and related language activities.
Since Chinese characters are constructed of strokes and radicals, an important question for character recognition in Chinese is whether these constructional units are the most crucial perceptual bases used in distinguishing among different characters. Interestingly, there is some evidence to indicate that this may not be the case. For instance, Yeh et al. (1997) asked people to sort characters into groups so that those that looked alike were together. These researchers applied multidimensional scaling to the sorting data and discovered that three configurational properties of characters (i.e., arrangement of components: vertical vs. horizontal, closeness of the configuration: open vs. close, and squarishness of the configuration: square vs. nonsquare) were the most powerful dimensions in explaining the results of sorting. Not among these were the basic patterns of strokes (e.g., horizontal, vertical, oblique, or twisty lines, dots, and so forth), Gibson’s (1969) set of critical features, or radicals. In other words, the global configuration of a character seems to play a more salient role in character classification than do local properties of strokes or radicals.
It is worth noting here that although individual radicals may not provide the most effective information in character discrimination, there is evidence to show that they are processed and used in the course of recognition. Indeed, it has been shown that properties of radicals (e.g., their type frequency, their location in a character, and their lexicality—whether they themselves can be used as independent characters) can exert significant effects on performance in such tasks as recognition (deciding whether a stimulus character appeared in a previous display), character decision (deciding whether a stimulus item is indeed a character used in daily life), and naming (for relevant results and/or discussions see, e.g., Li and Chen 1997, Zhou and Marslen-Wilson 1999). Thus, it appears that radicals are segmented from the base characters and their related information is utilized within the other processes resulting in the recognition of the global characters.
Another question that one might ask regarding Chinese characters is the processing role of characters in reading Chinese. There is clear evidence to indicate that individual characters are important encoding and processing units in Chinese. For instance, using Reicher’s (1969) tachistoscopic paradigm, Cheng (1981) demonstrated a character superiority effect whereby a radical component could be better detected when it was embedded in a real character than in a pseudocharacter (i.e., one that was constructed folowing the orthographic rules of the script) or a noncharacter (i.e., one that was formed against the orthographic rules of the script). Moreover, Chen (1984) reported a character inferiority effect in reading Chinese text using a component detection task, by which more detection errors were found when a target component was embedded in genuine characters than in pseudocharacters. These results clearly indicate that characters can be better perceived than radicals and that the fundamental unit in processing written Chinese is the character, and not the radical. This raises another interesting issue concerning the role of the character in reading. Although it is the word, rather than the morpheme, that is commonly considered to be the basic unit of language processing and used as the unit of comprehension analyses, there is evidence to indicate that the character still has a significant role to play even in the case of reading text. For example, using a character detection task, Chen (1987) found that there was a clear word superiority effect in reading Chinese text (i.e., a character was better detected when it was part of a two-character word than when it was part of a two-character nonword). If the word were the most important unit of comprehension analyses, one would expect to find a word inferiority effect rather than a word superiority effect, because the word-level processing should enjoy a higher priority than the character-level processing, and the word context should create an effect disruptive to the character detection task. This word superiority effect in reading Chinese stands in interesting contrast to both the character inferiority effect in Chinese and the word inferiority effect in English (e.g., Healy and Drewnowski 1983) and suggests that (a) characters serve as important encoding and processing units in reading Chinese text, and (b) characters play a more salient role in reading Chinese than letters do in reading English.
Finally, because different writing systems present linguistic information in distinctive forms, whether similar or different processes are activated and used in processing lexical items in the various orthographies has attracted considerable interest over the years. For instance, it has been argued that phonology plays a crucial role in the process of identifying a visually presented lexical item (e.g., Van Orden 1987). However, most research on this topic has been done using materials in alphabetic scripts. Hence, one way to verify the universality of this phonological hypothesis is to investigate whether phonology significantly influences the recognition of logographic characters (for recent research and discussion on this issue see, e.g., Chen and Zhou 1999). It turns out that there is good evidence to indicate that orthography rather than phonology plays a more crucial role in the recognition of Chinese characters, although phonology can also be activated in the course of recognition (e.g., Shen and Forster 1999). On the other hand, orthographic processing seems to play a less important role for alphabetic materials than phonological processing (e.g., Van Orden 1987). Similar evidence has also been shown in a memory research by Chen and Juola (1982) where Chinese and English were directly compared. A therefore conceivable hypothesis is that specific properties of a given script can affect related recognition and memory processes.
2.3 Research Models Proposed
At present, models of Chinese character recognition are quite scarce. Nevertheless, there are a few such models available. The existing models typically have structures similar to those developed from English materials, but with modifications to capture the properties of the Chinese language. Thus, for instance, there is a hierarchical interactive-activation model, in which there are orthographic and phonological representations structured in levels corresponding to multicharacter words, characters, radicals, and strokes (Taft et al. 1999). Similar attempts have been made using parallel-distributed processing models (e.g., Seidenberg and McClelland 1989) where orthographic, phonological, and semantic representations are connected in a triangular form and interact continuously (e.g., Zhou and Marslen-Wilson 1999). However, this type of modeling work is usually not explicit and should only be considered as preliminary for the time being, since the systematic study of Chinese character processing has only just begun.
3. Conclusions
The results obtained from the cognitive studies of character recognition complement the letter recognition studies that have probed the perceptual and cognitive mechanisms that are involved in the processing of written English. Together these studies on distinctively different scripts can provide valuable insights into the formation of a genuinely comprehensive theory of human language processing in general, and the cognitive processing of subword units in particular. Although there has been in recent years an upsurge of interest in conducting cognitive research across different scripts, much work remains to be done. Identifying universal principals and scriptspecific processes associated with the reading of different scripts should continue to be a challenge to researchers who are interested in the psychology of language in the new century and beyond.
Bibliography:
- Cattell J M 1886 The time it takes to see and name objects. Mind 11: 63–5
- Chen H-C 1984 Detecting radical component of Chinese characters in visual reading. Chinese Journal of Psychology 26: 29–34
- Chen H-C 1987 Character detection in reading Chinese: Effects of context and display format. Chinese Journal of Psychology 29: 45–50
- Chen H-C 1992 Reading comprehension in Chinese. In: Chen HC, Tzeng O J L (eds.) Language Processing in Chinese. North Holland, Amsterdam, pp. 175–205
- Chen H-C, Juola J F 1982 Dimensions of lexical coding in Chinese and English. Memory & Cognition 10: 216–24
- Chen H-C, Zhou X (eds.) 1999 Processing East Asian Languages. Psychology Press, London
- Cheng C-M 1981 Perception of Chinese characters. Chinese Journal of Psychology 23: 137–53
- Gibson E J 1969 Principles of Perceptual Learning and Development. Prentice-Hall, New York
- Healy A F, Drewnowski A 1983 Investigating the boundaries of reading units: Letter detection in misspelled words. Journal of Experimental Psychology: Human Perception and Performance 9: 413–26
- Li H, Chen H-C 1997 Processing of radicals in Chinese character recognition. In: Chen H-C (ed.) Cognitive Processing of Chinese and Related Asian Languages. The Chinese University Press, Hong Kong, pp. 141–60
- Liu I-M, Chuang C J, Wang S C 1975 Frequency Count of 40,000 Chinese Words. Liuguo Chubanshe, Taipei, Taiwan
- McClelland J L, Rumelhart D E 1981 An interactive activation model of context effects in letter perception: Part 1. An account of basis findings. Psychological Review 88: 375–407
- Neisser U 1963 Decision-time without reaction-time: Experiments in visual scanning. American Journal of Psychology 76: 376–85
- Reicher G M 1969 Perceptual recognition as a function of meaningfulness of stimulus material. Journal of Experimental Psychology 81: 275–80
- Rumelhart D E 1970 A multicomponent theory of perception of briefly exposed visual displays. Journal of Mathematical Psychology 7: 191–218
- Seidenberg M S, McClelland JL 1989 A distributed, developmental model of visual word recognition and naming. Psychological Review 96: 523–68
- Selfridge O G 1959 Pandemonium: A paradigm for learning. In: (eds.) Mechanisation of Thought Processes: Proceedings of the 10th Symposium of the National Physical Laboratory. HM Stationery Office, London, pp. 511–29
- Shen D, Forster KI 1999 Masked phonological priming in reading Chinese words depends on the task. Language and Cognitive Processes 14: 429–59
- Taft M, Liu Y, Zhu X 1999 Morphemic processing in reading Chinese. In: Wang J, Inhoff AW, Chen H-C (eds.) Reading Chinese Script: A Cognitive Analysis. Lawrence Erlbaum, Mahwah, NJ, pp. 91–113
- Van Orden GC 1987 A ROWS is a ROSE: Spelling, sound and reading. Memory & Cognition 15: 181–98
- Yeh S-L, Li JL, Chen I-P 1997 The perceptual dimensions underlying the classification of the shapes of Chinese characters. Chinese Journal of Psychology 39: 47–74
- Zhou X, Marslen-Wilson W 1999 Sublexical processing in reading Chinese. In: Wang J, Inhoff AW, Chen H-C (eds.) Reading Chinese Script: A Cognitive Analysis. Lawrence Erlbaum, Mahwah, NJ, pp. 37–63
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality