
Sample Perceptrons Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
Perceptrons was the generic name given by the psychologist Frank Rosenblatt to a family of theoretical and experimental artificial neural net models which he proposed in the period 1957–1962. Rosenblatt’s work created much excitement, controversy, and interest in neural net models for pattern classification in that period and led to important models abstracted from his work in later years. Currently the names (single-layer) Perceptron and Multilayer Perceptron are used to refer to specific artificial neural network structures based on Rosenblatt’s perceptrons. This research paper references the intellectual context preceding Rosenblatt’s work and summarizes the basic operations of a simple version of Rosenblatt’s perceptrons. It also comments briefly on the developments in this topic since Rosenblatt.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
Rosenblatt’s first (partial) report in January 1957 was titled The Perceptron: A Perceiving and Recognizing Automaton. A subsequent report, in January 1958, titled The Perceptron: A Theory of Statistical Separability in Cognitive Systems was adapted for publication (Rosenblatt 1958). A compendium of research on perceptrons by Rosenblatt and his group is Principles of Neurodynamics (Rosenblatt 1962).
Rosenblatt’s research was done in the context of: the neobehaviorism of Hull (1952), the general principles of neuromodeling of behavior proposed by Hebb (1949), the Threshold Logic Unit (TLU) neuron model of McCulloch and Pitts (1943), proposals for brain modeling based on neurophysiology (Eccles 1953) and symbolic logic, switching theory and digital computers (Shannon and McCarthy 1956), the stimJEulus sampling models of Estes and Burke (1953), the linear operator probabilistic learning models of Bush and Mosteller (1955), and statistical classification procedures (e.g., Rao 1955).
The basic building block of a perceptron is an element that accepts a number of inputs xi, i = 1 … N, and computes a weighted sum of these inputs where, for each input, its fixed weights β can be only + 1 or – 1. The sum is then compared with a threshold θ, and an output y is produced that is either 0 or 1, depending on whether or not the sum exceeds the threshold. Thus
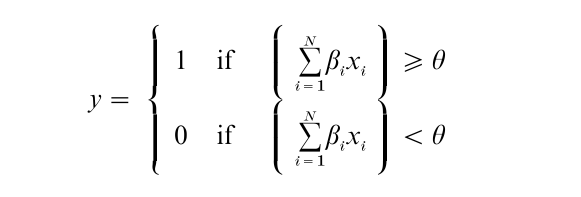
A perceptron is a signal transmission network consisting of sensory units (S units), association units (A units), and output or response units (R units). The ‘retina’ of the perceptron is an array of sensory elements (photocells). An S-unit produces a binary output depending on whether or not it is excited. A randomly selected set of retinal cells is connected to the next level of the network, the A units. As originally proposed there were extensive connections among the A units, the R units, and feedback between the R units and the A units. A simpler version omitting the lateral and feed-back connections is shown in Fig. 1 This simplification is the perceptron considered here.
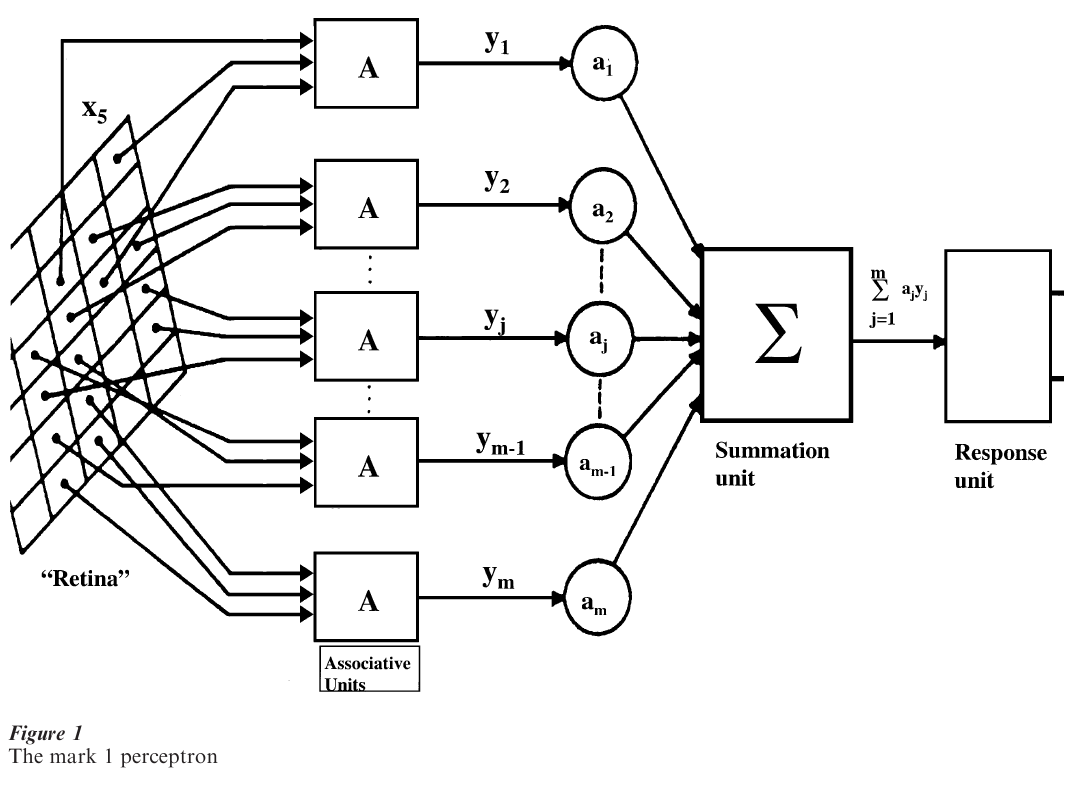
Each A unit behaves like the basic building block discussed above, where the + 1, – 1 weights for the inputs to each A unit are assigned randomly. The threshold θ for all A units is the same. The binary output of the kth A unit (k = 1, …, m ) is multiplied by a weight ak, and a sum of all m weighted outputs is formed in a summation unit that is the same as the basic building blocks with all weights equal to + 1. Each weight ak is allowed to be positive, zero, or negative, and may change independently of other weights. The output of this block is again binary, depending on a threshold, t, that is normally set at 0. The binary values of the output are used to distinguish two classes of patterns that may be presented to the retina of a perceptron. The design of this perceptron to distinguish between two given sets of patterns involves adjusting the weights ak, k = 1, …, m, and setting the threshold θ.
Rosenblatt (1962) proposed a number of variations of the following procedure for ‘training’ perceptrons. The set of ‘training’ patterns, that is, patterns of known classification, are presented sequentially to the retina, with the complete set being repeated as often as needed. The output of the perceptron is monitored to determine whether a pattern is correctly classified. If not, the weights are adjusted according to the following ‘error correction’ procedure: If the n-th pattern was misclassified, the new value ak(n +1) for the k-th weight is set to
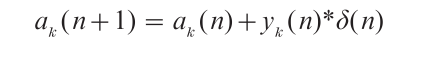
where δ( n) is 1 if the n-th pattern is from class 1 and δ(n) is – 1 if the n-th pattern is from class 2. No adjustment to the weight is made if a pattern is classified correctly.
Rosenblatt conjectured that, when the pattern classes are ‘linearly separable’ the error correction ‘learning’ procedure will converge to a set of weights defining the separating hyperplane that correctly classifies all the patterns. The shortest proof of this perceptron convergence theorem was given by A. J. Novikoff. Subsequent contributions related the simple perceptron to statistical linear discriminant functions and related the error-correction learning algorithm to gradient-descent procedures and to stochastic approximation methods that originally were developed for finding the zeros and extremes of unknown regression functions (e.g., Kanal 1962).
The simple perceptron described is a series-coupled perceptron with feed-forward connections only from S units to A units and A units to the single R unit. The weights ak, the only adaptive elements in this network, are evaluated directly in terms of the output error.
Minsky and Papert (1969) further reduced the simple perceptron to a structure with sampled connections from the ‘retina’ directly to the adjustable weights. This reduced structure is referred to as a single-layer perceptron. There is no layer of ‘hidden’ elements, that is, additional adjustable elements for which the adjustment is only indirectly related to the output error. A feed-forward perceptron with one or more layers of hidden elements is termed a multilayer perceptron. Rosenblatt investigated cross-coupled perceptrons in which connections join units of the same type, and also investigated multilayer back-coupled perceptrons, which have feedback paths from units located near the output. For series-coupled perceptrons with multiple R units, Rosenblatt proposed a ‘back-propagating error correction’ procedure that used error from the R units to propagate correction back to the sensory end. But neither he nor others at that time were able to demonstrate a convergent procedure for training multilayer perceptrons.
Minsky and Papert (1969) proved various theorems about single-layer perceptrons, some of which indicated their limited pattern-classification and function approximating capabilities. For example, they proved that the single-layer perceptron could not implement the Exclusive OR logical function and several other such predicates. Later, many writing on Artificial Neural Networks (ANN) blamed this book for greatly dampening interest and leading to a demise of funding in the USA for research on ANN’s. The section on ‘Alternate Realities’ in Kanal (1992) details why the blame is misplaced. As noted there, by 1962 (see, e.g., Kanal 1962) many researchers had moved on from perceptron type learning machines to statistical and syntactic procedures for pattern recognition.
Minsky and Papert’s results did not apply to multilayer perceptrons. Research on ANN’s, biologically motivated automata, and adaptive systems continued in the 1970s in Europe, Japan, the Soviet Union, and the USA, but without the frenzied excitement of previous years, which also came back starting in the early 1980s. In a 1974 Harvard University dissertation Paul Werbos presented a general convergent procedure for adaptively adjusting the weights of a differentiable nonlinear system so as to learn a functional relationship between the inputs and outputs of the system. The procedure calculates the derivatives of some function of the outputs, with respect to all inputs and weights or parameters of the system, working backwards from outputs to inputs. However, this work, published later later in a book by Werbos (1994), went essentially unnoticed, until a few years after Rumelhart et al. (1986), independently popularized a special case of the general method. This algorithm, known as error backpropagation or just backpropagation, adaptively adjusts the weights to perform correct pattern classification using gradient descent and training samples. It propagates derivatives from the output layer through each intermediate layer of the multilayer perceptron network. The resurgence of work on multilayer perceptrons and their applications in the decades of the 1980s and 1990s is directly attributable to this convergent backpropagation algorithm.
It has been shown that multilayer feedforward networks with a sufficient number of intermediate or ‘hidden’ units between the input and output units have a ‘universal approximation’ property: they can approximate ‘virtually any function of interest to any desired degree of accuracy’ (Hornik et al. 1989). Several modifications of the basic perceptron learning procedure that make perceptron learning well behaved with inseparable training data, even when the training data are noisy and not error free, have been proposed in recent years and various ANN learning procedures have been shown to related to known statistical techniques. The reference list includes some recent books with tutorial material covering Perceptrons and related ANN’s.
Bibliography:
- Anderson J A 1995 An Introduction to Neural Networks. MIT Press, Cambridge, MA
- Bush R R, Mosteller F 1955 Stochastic Models for Learning. Wiley, New York
- Chauvin Y, Rumelhart D E (eds.) 1995 Backpropagation: Theory, Architectures, and Applications. Erlbaum, Mahwah, NJ
- Eccles J C 1953 The Neurophysiological Basis of Mind. Clarendon Press, Oxford, UK
- Estes W K, Burke C J 1953 A theory of stimulus variability in learning. Psychological Review 6: 276–86
- Haykin S 1999 Neural Networks. A Comprehensive Foundation, 2nd edn. Prentice Hall, Upper Saddle River, NJ
- Hebb D O 1949 The Organization of Behaviour. Wiley, New York
- Hornik K, Stinchcome M, White H 1989 Multilayer feed-forward networks are universal approximators. Neural Networks 2: 359–66
- Hull C L 1952 A Behaviour System. Yale University Press, New Haven, CT
- Kanal L 1962 Evaluation of a class of pattern-recognition networks. In: Bernard E E, Kare M R (eds.) Biological Prototypes and Synthetic Systems. Plenum Press, New York (reprinted in Sethi I, Jain A 1995 Neural Networks and Pattern Recognition. Elsevier, Amsterdam)
- Kanal L N 1992 On pattern, categories, and alternate realities, 1992 KS Fu award talk at IAPR, The Hague. Pattern Recognition Letters 14: 241–55
- McCulloch W S, Pitts W A 1943 A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics 5: 115–33
- Minsky M, Papert S 1969 Perceptrons. MIT Press, Cambridge, MA
- Rao C R 1955 Advanced Statistical Methods in Biometric Research. Wiley, New York
- Rosenblatt F 1958 The Perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review 65: 386–408
- Rosenblatt F 1962 Principles of Neurodynamics. Spartan, New York
- Rumelhart D E, Hinton G E, Williams R J 1986 Learning internal representations by error propagation. In: Rumelhart D E, McClelland J L et al. (eds.) Parallel Distributed Processing: Explorations in the Microstructure of Cognition. MIT Press, Cambridge, MA, Vol. 1, pp. 318–62
- Shannon C E, McCarthy J M (eds.) 1956 Automata Studies. Princeton University Press, Princeton, NJ
- Werbos P 1994 The Roots of Backpropogation: From Ordered Derivatives to Neural Networks and Political Forecasting. Wiley, New York
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality