
View sample Statistical Pattern Recognition Research Paper. Browse other statistics research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
Statistical pattern recognition is concerned with the problem of using statistical techniques to design machines that can classify patterns of measurement data in useful ways. For example, such techniques have been successfully exploited in areas such as object recognition, speech recognition, fingerprint recognition, data analysis, signal processing, cognitive modeling, and artificial intelligence. After identifying key ‘features’ of information in the measurement data, a statistical pattern recognition machine uses its expectations about the ‘likelihood’ of those features and the ‘losses’ of making situation-specific decisions to select a classification action which minimizes an appropriate expected risk function. In many cases, the statistical pattern recognition machine must ‘learn’ through experience the relative likelihood of occurrence of patterns of features in its environment. Although typically viewed as a branch of artificial intelligence statistical pattern recognition methods have been extensively and successfully applied to many behavioral modeling and data analysis problems. The present entry discusses some of the essential features of the generic statistical pattern recognition problem (see Andrews 1972, Duda and Hart 1973, Golden 1996, Patrick 1972).
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
1. Generic Statistical Pattern Recognition Problem
As shown in Fig. 1, the generic statistical pattern recognition problem may be described in terms of four major components: feature selection and feature extraction, probabilistic knowledge representation, Bayes decision rule for classification, and a mechanism for learning.
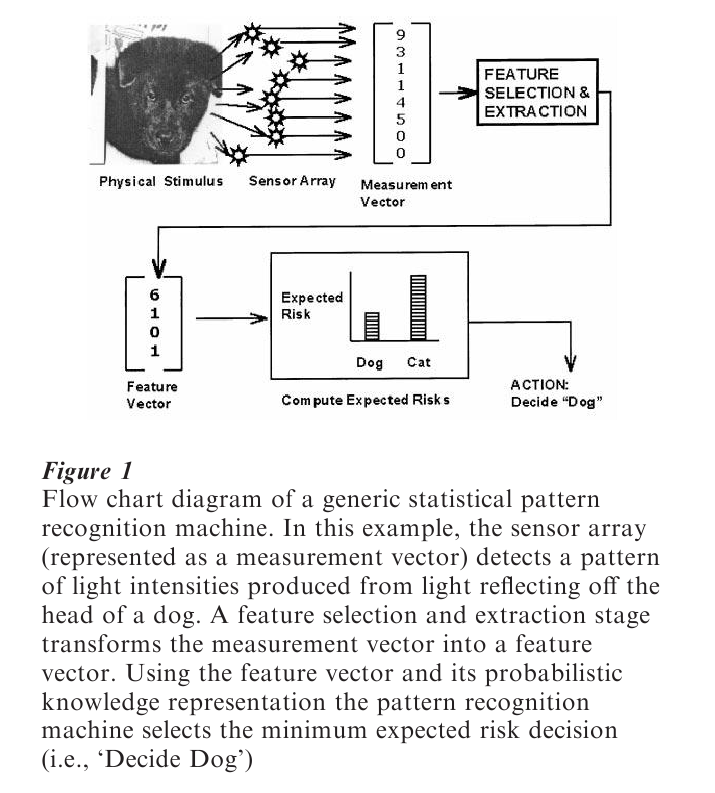
1.1 Feature Selection And Extraction
The pattern of measurement data to be classified is represented as a measurement vector (i.e., a point in ‘measurement space’). The choice of the measurement space is primarily determined by problem-imposed considerations such as the types of transducers which are available and the types of patterns which must be processed. The particular pattern classification methodology embodied in the pattern recognition machine usually has little or no influence over the choice of the measurement space. Each measurement vector is then mapped into a feature vector (i.e., a ‘point’ in feature space) whose dimensions are primarily chosen to facilitate pattern classification by the pattern recognition machine. This process which maps a measurement vector s into a feature vector x is called the feature selection and extraction stage of the pattern recognition process.
1.2 Probabilistic Knowledge Representation
Knowledge is implicitly represented in a statistical pattern recognition machine in several ways. The particular process for mapping points in measurement space into feature space (as well as the dimensions of the feature space) is one important knowledge source. However, the expected likelihood of observing a particular feature vector and the associated losses for making different situation-specific decisions are also critical knowledge sources.
Specifically, let the symbol ω denote the pattern class. Thus, ω refers to the first pattern class (e.g., a set of photographs of ‘dogs’) that might have generated the observed feature vector x, while the symbol ω refers to a second competing pattern class (e.g., a set of photographs of ‘cats’) that might have generated x. The likelihood of observing a feature vector x, corresponding to a particular pattern class is expressed in terms of two types of probability distributions. The a priori class probability distribution p(ωi) indicates the likelihood that a feature vector will be generated from the pattern class ωi before the feature vector x has been observed. The class conditional probability distribution p(x|ωi) indicates the conditional likelihood of observing the feature vector x given that the feature vector x had in fact been generated from pattern class ωi.
Knowledge regarding the expected consequences of taking a particular classification action αj, given the feature vector came from pattern class ωi is also exploited. Typically, the classification action takes the form of a decision indicating which of a finite number of pattern classes generated the feature vector. Formally, it is assumed that a loss λ(αj|ωi) is incurred when classification action αj is taken when the feature vector was in fact generated from pattern class ωi.
1.3 Bayes Decision Rule For Classification
The optimal decision rule for selecting a classification action αj if the pattern class ωi generated the feature vector simply requires that the classification action α* which minimizes the loss for the pattern class ωi be chosen (i.e., λ (α|ωi) ≥ λ(α*|ωi) for all α). In practice, however, the pattern class ωi which actually generated the feature vector is unknown. The statistical pattern recognition machine only has access to the observed feature vector x and its probabilistic knowledge base.
One possible rational inductive decision making strategy is called the Bayes decision rule for classification; it forms the basis for classification decisions in most statistical pattern recognition algorithms. The Bayes decision rule for classification dictates that the pattern recognition machine should select the classification action α* which minimizes the expected loss or conditional risk given feature vector x is observed. Formally, the risk R(α|x) is defined by the formula:
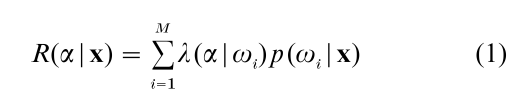
The important minimum probability of error case of Eqn. (1) arises when λ(αk|ωi) = 1 when i ≠ k and λ(αk|ωi) = 0 for I = k. In this case, Eqn. (1) becomes:
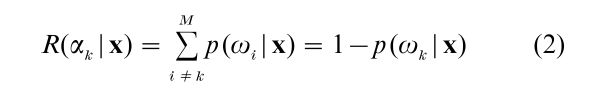
The action αk which minimizes the probability of error case of the risk function in Eqn. (1) is usually called a maximum a posteriori (MAP) estimate since αk maximizes the a posteriori distribution p(ωj |x) (i.e., the distribution obtained after observing the feature vector x).
Now note that the risk R(α|x) in Eqn. (1) can be expressed in terms of the a priori class likelihoods and class conditional likelihoods using the formula:
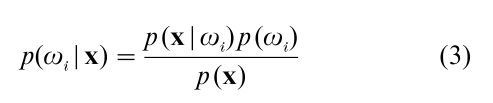
Substituting this expression into Eqn. (1), it follows that the risk, R(α|x), for selecting action α given feature vector x is observed can be expressed as:
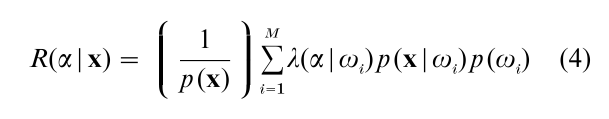
For computational reasons, some monotonically decreasing function of R(αi|x) is usually exploited and referred to as a discriminant function gi(x). For example, a useful discriminant function for Eqn. (4) is:
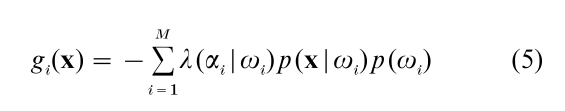
which does not require computation of p(x).
Such discriminant functions define ‘decision boundaries’ in feature space. For example, suppose that there are only two pattern classes with corresponding discriminant functions g and g . In this situation, the feature vector x is classified as a member of pattern class ω1 if g1(x) – g2(x) < 0 and a member of pattern class ω2 if g1(x) – g2(x) > 0. Thus, the ‘decision boundary’ between the two pattern classes in feature space is defined by the set of feature vector which satisfy the equation: g1(x) – g2(x) = 0.
1.4 Learning As Bayes Estimation
Just as the classification problem involves selecting that classification action which minimizes an appropriate expected classification loss function, the learning problem can also be formulated within a minimum expected loss framework as well. Typically, the measurement vector, feature vector mapping from measurement space into feature space, a priori class distributions, and loss functions are known. Also the family of class conditional distributions or the ‘class conditional probability model’ is typically indexed by the values of some model parameter β. Given this latter assumption, a model is a set such that each element is a class conditional probability distribution p(x|ω; β). The goal of the learning problem is then reduced to the problem of selecting a particular value of the parameter β.
1.4.1 A Bayes Risk Function For Learning. Assume the measurement vector to feature vector mapping, classification decision loss function λ, and a priori class probabilities {p(ω1), …, p(ωM)} have been specified. In addition, assume a class conditional probability model defined by a set of class conditional distributions of the form p(x|ω; β). The learning problem then reduces to the problem of estimating a value of the parameter β given a set of training data.
Let Xn = [x(1), …, x(n)] denote a set of n feature vectors which define a set of training data. For expository reasons, simply assume x(1), …, x(n) are observed values (realizations) of independent and identically distributed (i.i.d.) random vectors. Let p(β) denote the a priori probability distribution of β (i.e., the distribution of the parameter vector β before the training data Xn has been observed). Let l(β, β*) denote a loss function associated with the action for selecting a particular value of β when the correct choice of the parameter β is in fact β*. A popular and general risk function for selecting parameter β given the training data Xn involves finding a β that minimizes the Bayes risk function for learning (e.g., Patrick 1972 pp. 71–2) given by the formula:
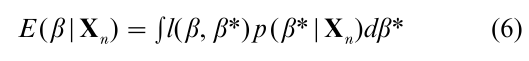
The quantity p(β|Xn) (known as the a posteriori density or a posteriori mass function for parameter vector β) is not explicitly provided since it can be expressed in terms of p(x|ω; β) (the class conditional likelihood function), p(β) (the a priori likelihood of β which is not dependent upon the pattern recognition machine’s experiences), and the ‘training data’ Xn. It then follows from the i.i.d. assumption that:
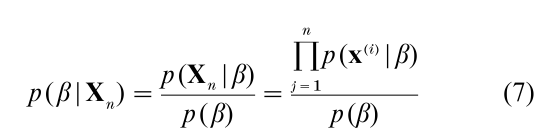
For expository reasons, assume β is quantized so that it can take on only a finite number of values. Then minimizing Eqn. (6) using the loss function l(β, β*) = l if β ≠ β* and l(β, β*) = 0 if β = β* corresponds to maximizing Eqn. (7 ) (i.e., computing the MAP estimate or most probable value of β). It can be shown that for many popular a priori and class conditional distribution functions, p(β|Xn) can be well approximated by the ‘likelihood of the observed data,’ p(Xn|β) for sufficiently large sample size n (e.g., Golden 1996 pp. 299–301). Accordingly, a popular approach to parameter estimation known as maximum likelihood estimation involves maximizing the likelihood function p(Xn|β) by selecting a parameter vector value, βn, such that p(Xn|βn) ≥ p(Xn|β) for all β.
1.4.2 Nonparametric And Parametric Learning Algorithms. Learning algorithms that make minimal assumptions regarding how the data was generated are referred to as nonparametric learning algorithms. For such algorithms, the parametric form of the class conditional distribution is often quite flexible. Nonparametric Parzen-window-type learning algorithms (e.g., Duda and Hart 1973, Patrick 1972) essentially count the observed occurrence of different values of the feature vector x. Learning algorithms that incorporate considerable prior knowledge about the data generating process are referred to as parametric learning algorithms. The classical Bayes classifier which assumes that the class conditional distributions have a Gaussian distribution is a good example of a parametric learning algorithm (e.g., Duda and Hart 1973, Patrick 1972).
Nonparametric learning algorithms have the advantage of being relatively ‘unbiased’ in their analysis of the data but may require relatively large amounts of the right type of training data for effective learning. Parametric learning algorithms are ‘biased’ algorithms but if the right type of prior knowledge is ‘built-in’ to the learning algorithm then a parametric learning algorithm can exhibit superior learning from even poor quality training data. Statistical pattern recognition algorithms which are typically viewed as ‘nonparametric’ can be transformed into parametric learning algorithms if a sufficient number of constraints upon the class conditional distributions are imposed. For example, polynomial discriminant function (e.g., Duda and Hart 1973, Patrick 1972) and the closely related multilayer backpropagation neural network and perceptron type learning algorithms (e.g., Golden 1996; also see Perceptrons) can learn to approximate almost any desired form of the class conditional distribution function (given sufficiently many free parameters). Thus, such learning algorithms are best viewed as nonparametric statistical pattern recognition algorithms. On the other hand, prior knowledge in the form of constraints on the parametric form of the class conditional distributions can usually be introduced resulting in parametric variations of such classical nonparametric learning algorithms (e.g., Golden 1996).
1.4.3 Supervised, Unsupervised, And Reinforcement Learning Algorithms. Supervised, unsupervised, and reinforcement learning algorithms have the common goal of estimating the class conditional distribution from the training data. The essential difference among these different learning algorithms is the availability of information in the feature vector indicating which pattern class generated the feature vector. In supervised learning, each feature vector in the training data set contains explicit information regarding which pattern class generated that feature vector. In unsupervised learning, information regarding which pattern class generated a particular feature vector is not available in either the training data set or the test data set. In reinforcement learning, ‘hints’ about which pattern class generated a particular feature vector are provided either periodically or aperiodically throughout the learning process (Sutton and Barto 1998).
2. Applications
2.1 Artificial Intelligence
Statistical pattern recognition methods have been extensively applied in the field of artificial intelligence. Successful applications of these methods in the field of computer vision include extraction of low-level visual information from visual images, edge detection, extracting shape information from shading information, object segmentation, and object labeling (e.g., Chellapa and Jain 1993, Duda and Hart 1973). Statistical pattern recognition methods such as Hidden Markov models play an important role in speech recognition algorithms and natural language understanding (Charniak 1993). Bavesian networks defined on directed acyclic graphs and the closely related Markov random field methods are being applied to problems in inductive inference (Chellapa and Jain 1993, Golden 1996, Jordan 1999). In the fields of robot control and neurocomputing, the general stochastic dynamical system control problem is naturally viewed within a statistical pattern recognition framework where the control signal corresponds to the pattern recognition machine’s ‘action’ (Golden 1996).
2.2 Behavioral Modeling
In an attempt to develop and refine theories of human behavior, some psychologists have compared the behavior of a class of statistical pattern recognition machines known as ‘connectionist’ algorithms with human behavior (see Golden 1996, and Ellis and Humphreys 1999). Although such algorithms are typically not presented within a statistical pattern recognition context, they can usually be naturally interpreted as statistical pattern recognition machines (Golden 1996).
2.3 Data Analysis
Increasingly sophisticated methods for discovering complex structural regularities in large data sets are required in the social and behavioral sciences. Many classical statistical pattern recognition techniques such as factor analysis, principal component analysis, clustering analysis, and multidimensional scaling techniques have been successfully used. More sophisticated statistical pattern recognition methods such as artificial neural networks and graphical statistical models will form the basis of increasingly more important tools for detecting structural regularities in data collected by social and behavioral scientists.
Bibliography:
- Andrews H C 1972 Introduction to Mathematical Techniques in Pattern Recognition. Wiley, New York
- Charniak E 1993 Statistical Language Learning. MIT Press, Cambridge, MA
- Chellappa R, Jain A 1993 Marko Random Fields: Theory and Application. Academic Press, New York
- Chen C H, Pau L F, Wang P S P 1993 Handbook of Pattern Recognition & Computer Vision. World Scientific, River Edge, NJ
- Duda R O, Hart P E 1973 Pattern Classification and Scene Analysis. Wiley, New York
- Ellis R, Humphreys G 1999 Connectionist Psychology: A Text with Readings. Psychology Press, East Sussex, UK
- Golden R M 1996 Mathematical Methods for Neural Network Analysis and Design. MIT Press, Cambridge, MA
- Jordan M I 1999 Learning in Graphical Models. MIT Press, Cambridge, MA
- Nilsson N J 1965 Learning Machines. McGraw-Hill, New York
- Patrick E A 1972 Fundamentals of Pattern Recognition. Prentice Hall, Englewood Cliffs, NJ
- Schervish M J 1995 Theory of Statistics. Springer-Verlag, New York
- Sutton R S, Barto A G 1998 Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality