
Sample Order Statistics Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
The field of order statistics deals with the properties and applications of ordered random variables and of functions involving them. Simple examples, useful as descriptive statistics, are the sample maximum and minimum, median, range, and trimmed means. Major applications include the estimation of location and scale parameters in complete or censored samples, selection procedures, the treatment of outliers, robust estimation, simultaneous inference, data compression, and probability plotting. Although important in the theory of nonparametric statistics, the subject of order statistics is very largely parametric, that is, its results depend generally on the form of the population(s) sampled.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
1. Introduction
Let the variates X1, …, Xn be arranged in ascending order and written X1:n ≤ Xr:n ≤…≤ =Xn:n. Then Xr:n is the rth order statistic (r = 1, …, n), a term also applied to the corresponding observed value, xr:n. The median is X(n+1)/2:n for n odd and 1/2(Xn/2:n + Xn/2+1:n) for n even. Helped by their simplicity, the median and the range, Xn:n – X1:n, have long been valuable as measures of location and scale, respectively.
Consider the following illustrative data, with i = 1, …, 8
xi: 16 40 23 12 240 33 17 27
xi:8: 12 16 17 23 27 33 40 240
These figures may represent the annual incomes (in multiples of $1,000) at age 30 of eight high-school dropouts. Because of the outlier x5 = 240, the median, 1/2(23 + 27) = 25, clearly gives a better picture of the group than the mean, 51. The median would in fact be unchanged as long as x5 ≥ 27, which shows just how robust the median is.
Next, suppose that the xi are test scores out of a total of 40. If we are unable to correct the impossible score of 240, we eliminate or censor it. The median is then x4:7 = 23, no longer very different from the mean, x = 24. The range is not robust, dropping from 228 to 28, and is therefore useful in detecting outliers, which are seldom as obvious as in the above data (see Sect. 6.3). For ‘well-behaved’ data, the range provides a simple measure of variability or scale.
In time series, X1, X2, …, these descriptive statistics are particularly helpful when based on small moving subsamples Xj, Xj+1, …, Xj+n−1 ( j = 1,2, …). The resulting moving (or running) medians provide a current measure of location that, unlike the moving mean, is not too sensitive to outliers. The sequence of moving medians represents a smoothing of the data, with important applications in signal and image processing. Moving ranges are useful in quality control charts, where their sensitivity to outliers is a desirable feature. If more robust current estimators of dispersion are required, one can turn to the difference of the second largest and the second smallest in each moving sample, etc.
Again, the above xi may represent response times to a stimulus. The extremes, 12 and 240, are then of particular interest (see Sect. 5.2). Of course, we would want more extensive data for which we may also wish to study the upper and lower records, here (16, 40, 240) and (16, 12).
2. Basic Distribution Theory
If X1, …, Xn is a random sample from a population with cumulative distribution function (cdf ) F(x), then the cdf of Xr:n is given by
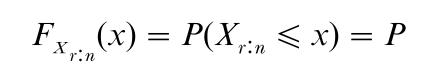
(at least r of X1, …, Xn are less than or equal to x)
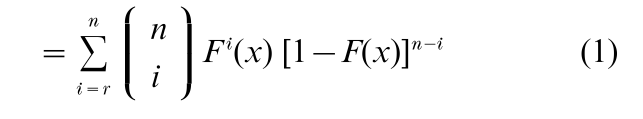
since the term in the summand is the binomial probability that exactly i of X1, …, Xn are less than or equal to x.
In handling order statistics, usually it is assumed that the underlying variate X is continuous. Note that this assumption is not needed in the derivation of Equation (1). Also, if X can take only integral values, then P(Xr:n = x) = FXr:n(x) – FXr:n(x – 1). However, if X is discrete, the probability of ties among the observations is positive, which tends to complicate the distribution theory (see, e.g., David 1981, p. 13, Arnold et al. 1992, p. 41).
If the probability density function (pdf)f (x) exists, as we will assume from here on, then differentiation of Eqn. (1) yields
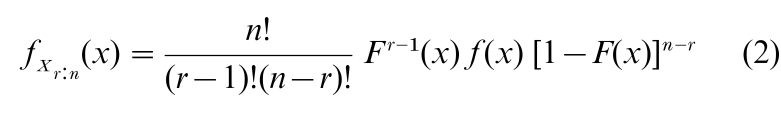
Also, the joint pdf of Xr:n and Xs:n (1 ≤ r < s ≤ n) is, for x ≤ y (e.g., David 1981, p. 10, Arnold et al. 1992, p. 16)
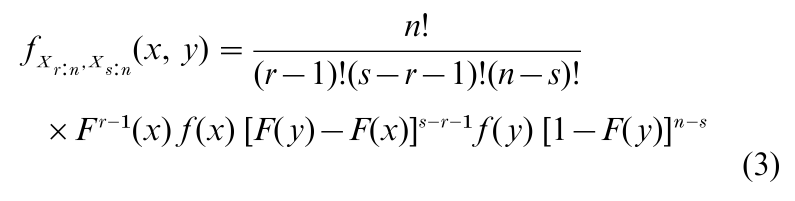
Equations (2) and (3) are fundamental and permit the calculation, usually by numerical integration, of the means, variances, and covariances. Also, Eqn. (3) makes possible the derivation, by standard methods, of the pdf of functions of two order statistics, such as the range Wn = Xn:n – X1:n. To facilitate the use of order statistics, extensive tables have been developed, especially when F(x) = Φ(x), the standard normal cdf (see Pearson and Hartley 1970 1972, Harter and Balakrishnan 1996, 1997).
3. Distribution-Free Inter Al Estimation
Three important types of distribution-free intervals involving order statistics may be distinguished. For simplicity we assume that F(x) is strictly increasing for 0 < F(x) < 1.
3.1 Confidence Intervals For Quantiles
The (population) quantile of order p, ξp, is defined by F(ξp) = p, 0 < p < 1. In particular, ξ1/2 is the median. Since, for r < s P(Xr:n < ξp < Xs:n) = P(Xr:n < ξp) – P(Xs:n < ξp), it follows from Eqn. (1) that the interval (Xr:n, Xs:n) covers ξp with probability
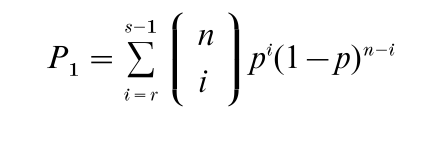
3.2 Tolerance Intervals
The focus here is on the probability, P2, with which (Xr:n, Xs:n) covers a proportion γ of the underlying population. Thus P2 = P{F(Xs:n) – F(Xr:n) ≥ γ} Since F(X ) is a uniform (0,1) variate, U, P2 = P (Us:n – Ur:n ≥ γ) = 1 – Iγ(s – r, n – s + r + 1), with the help of Equation (3), where Iγ (a,b) is the incomplete beta function.
3.3 Prediction Intervals
Let X1, …, Xm, Y1, …, Yn be independent variates with cdf F(x). The Xs may represent current observations and the Ys future observations. What is the probability, P , that Yt:n (t = 1, …, n) falls between Xr:m and Xs:m (1 ≤ r < s ≤ m)? It can be shown that P3 = P(Yt:n > Xr:m) – P(Yt:n > Xs:m), where
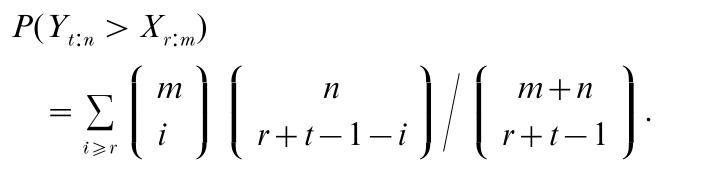
A good account from the user’s point of view of all these intervals is given in Chap. 5 of Hahn and Meeker (1991).
4. Estimation Of Parameters
An important simple example is the use of range in quality control to estimate the standard deviation (sd) σ in a normal sample. If wn;α denotes the upper α significance point of the range in a standard normal population, then from P(wn;1−a/2 < Wn/σ < wn;a/2) = 1 – α it follows that a (1 – α) confidence interval (CI) for σ is
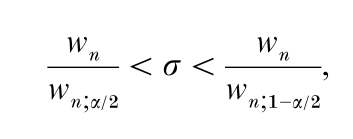
where wn is the observed value of the range.
An unbiased point estimator of σ is σW = Wn /dn, where dn = E(Wn/σ) is widely tabulated. Let σS denote the unbiased root-mean-square estimator of σ. In small samples the efficiency of σW, i.e., var σS/ var σW, is quite high (0.955 for n 5).
More systematically, linear functions of the order statistics (L-statistics) can be used to estimate both location and scale parameters, µ and σ (not necessarily mean and sd), for distributions with pdf of the form
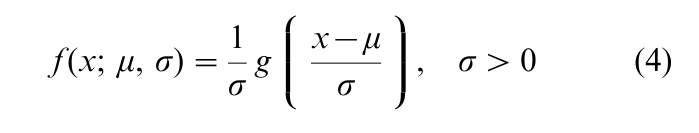
With Y = (X – µ)/σ, let αr:n = E (Yr:n) and βrs:n = cov (Yr:n, Ys:n) (r, s = 1, …, n). It follows that Xr:n = µ + σYr:n, so that
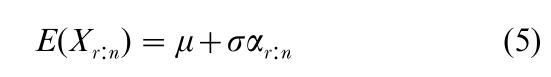
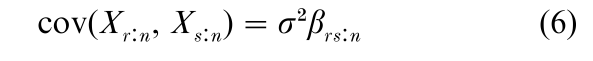
A major advance was made by Lloyd (1952), who recognized that the generalized Gauss–Markov theorem can be applied to the estimation of µ and σ, in view of Eqns. (5) and (6). This yields the best linear unbiased estimators (BLUEs).
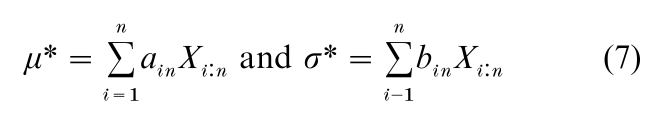
where the ain and bin are functions of the αi:n and βij:n and can be evaluated once and for all. For tables in the normal case, see Sarhan and Greenberg (1962).
The statistics in Eqn. in (7) provide estimators that are unbiased and of minimum variance within the class of linear unbiased estimators. They are particularly convenient for data in which some of the smallest and/or largest observations have been censored, since maximum likelihood (ML) estimation tends to be difficult in this situation. Also, for complete and censored samples, ML estimation may produce biased estimators. However, µ* and σ* may not have the smallest mean squared error, even among L- statistics. Simplified approximate estimation procedures are also possible (see, e.g., David 1981, p. 128 or Arnold et al. 1992, p. 171).
5. Asymptotic Theory
Except for the distribution-free results of Sect. 2, the practical use of order statistics in finite samples depends heavily on the availability of tables or computer programs appropriate for the underlying population. In large samples, asymptotic theory can provide approximate results that are both simpler and more widely applicable.
It is useful to distinguish three situations as n → ∞: (a) Central order statistics X(np):n, where (np) denotes here the largest integer ≤ np + 1, with 0 < p < 1; (b) Extreme order statistics Xr:n, where r = 1, …, m or r = n – m + 1, …n, and m is a fixed positive integer; (c) Intermediate order statistics Xr:n or Xn−r+1:n, where r → ∞ but r/n → 0.
5.1 Central Order Statistics
Corresponding to the population quantile ξp of Sect. 2.1, it is natural to call X(np):n a sample quantile. The following important result then holds (e.g., David 1981, p. 254). Let X1, …, Xn be a random sample from a population with pdf f (x) and put nj = (npj), j = 1, …, k, where k is fixed and 0 < p1 < p2 <…< pk < 1. If 0 < p(ξpj) < ∞, j = 1, …, k, then the asymptotic joint distribution of √n(Xn :n – ξp1), …, √n(Xnk:n -ξpk) is k-dimensional normal, with zero mean vector and covariance matrix (σjj), where
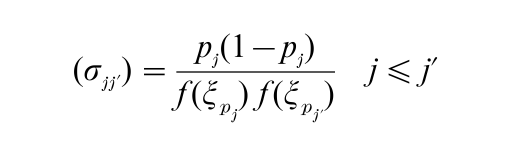
As a very special case, it follows that for the median Mn = X(n+1)/2:n (n odd), as n → ∞, √n(Mn – µ) → N (0, πσ2/2) showing incidentally that, as an estimator of µ, Mn has asymptotic efficiency (relative to X ) of 2/π = 0.637. The same result holds for n even.
5.2 Extreme Order Statistics
The situation is more complicated when p1 = 0 or pk = 1, corresponding to the extremes X1:n, Xn:n and more generally to the mth extremes Xm:n, Xn+1−m:n, where m is a fixed positive integer. For Xn:n, suitably normalized, there are three limiting distributions, the simplest of which is the Type III extreme-value distribution with cdf Λ3(x) = exp (-e−x) – ∞ < x < ∞. This distribution has been found very useful in describing the behavior of floods and other extreme meteorological phenomena. A convenient sufficient condition for Λ3(x) to be the appropriate limiting distribution is that the underlying distribution satisfy
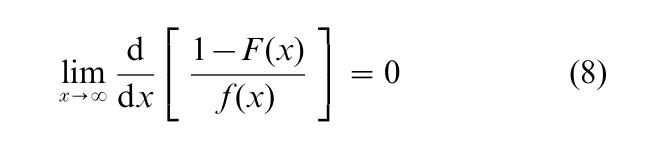
Then
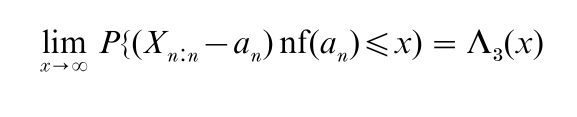
where an is given by F(an) = 1 – 1/n. Distributions for which Eqn. (8) holds include the normal, gamma, and logistic families. For a full treatment of the extreme-value case, see Galambos (1987).
5.3 Intermediate Order Statistics
An example of an intermediate order statistic is X√n:n. A suitably normalized form of Xr:n may have either a normal or nonnormal asymptotic distribution (e.g., Arnold et al. 1992, p. 226).
5.4 Asymptotic Independence Results
A useful result is that, after appropriate normalization, upper extremes are asymptotically independent of lower extremes. Moreover, all extremes are asymptotically independent of the sample mean (e.g., David 1981, pp. 267–70).
5.5 L-Statistics
It is clear from the above that a linear function of sample quantiles, ∑kj=1cjXnj:n, tends to normality as n → ∞ (k fixed). On the other hand, the asymptotic distribution of linear functions of the extremes, such as the range, will be more complicated. An L-statistic, ∑ni=1cinXi:n, involving extreme, intermediate, and central order statistics, may be asymptotically normal or nonnormal, depending on the underlying distribution and on how much weight is placed on the extreme order statistics.
6. Applications
6.1 Probability Plotting
This very useful graphical method typically is applied to data assumed to follow a distribution depending, as in Eqn. (3), only on location and scale parameters µ and σ. The ordered observations xi:n(i = 1, …, n) are plotted against νi = G−1 ( pi), where G is the cdf of Y = (X – µ) σ and the pi are probability levels, such as pi =(i – 1/2)/n. The plotting is immediate if probability paper corresponding to G is available, as it is for, for example, the normal, lognormal, and Weibull distributions. If a straight-line fit through the points (νi, xi:n) seems unreasonable, doubt is cast on the appropriateness of G. Often this simple procedure is adequate, but it may be followed up by a more for- mal test of goodness-of-fit.
If a straight line fits satisfactorily, a second use may be made of the graph: σ may be estimated by the slope of the line and µ by its intercept on the vertical axis. A detailed account of probability plotting and the related hazard plotting is given in Nelson (1982).
6.2 Selection Differentials And Concomitants Of Order Statistics
If the top k ( < n) individuals are chosen in a sample from a population with mean µ and sd σ, then Dk,n = (Xn−k+1:n +…+ Xn:n – kµ)/kσ measures the superiority, in sd units, of the selected group. The mean and variance of this selection differential is given immediately by Eqns. (5) and (6) as E (Dk,n) = ∑ αi:n /k, var (Dk,n) =∑∑βij:n/k2, where all summations run from n – k + 1 to n.
Often one is interested in how this group performs on some related measurement Y. Thus, X may refer to a screening test and Y to a later test or X to a parent animal and Y to an offspring. The Y-variate paired with Xr:n may be denoted by Y[r:n] and called the concomitant of the rth order statistic. Corresponding to Dk,n, the superiority of the selected group on the Y-measurement is, with obvious notation, D[k,n] = (∑Y[i:n] – kµY)/kσY. If Y is linearly related to X, such that Yi = µY + ρσY(Xi – µX)/σX + Zi where ρ is the correlation coefficient between X and Y, and Zi is independent of Xi, with mean 0 and variance σY2(1 – ρ2), then Y[r:n] = µY + ρσY(Xr:n – µX)/σX + Z[r] where Z[r] is the Z-variate associated with Xr:n (e.g., David 1981, p.110 ). It follows that EYr:n = µY + ρσYαr:n, var Y[r:n] = σ2Y(ρ2βrr:n + 1 – ρ2), cov (Y[r:n], Y[s:n]) = ρ2σ2Yβrs:n r =s so that the mean and variance of D[k,n], the induced selection differential, are ED[k,n] = ρEDk:n, var D[k,n] = ρ2var Dk:n + (1 – ρ2 )/k. The asymptotic distribution of D[k:n] as well as many other properties and applications of concomitants of order statistics are treated in David and Nagaraja (1998).
6.3 Outliers And Selection Of The Best
Order statistics, especially Xn:n and X1:n, enter naturally into many outlier tests. Thus, if X1, …, Xn are supposedly a random sample from a normal dis tribution with unknown mean and known variance σ2, then large values of Bn = (Xn:n – X)/σ make this null hypothesis, H0 , suspect. The corresponding two-sided statistic is Bn´ = maxi=1,…,n|Xi-X|σ . If σ is unknown, studentized versions of Bn or Bn´ can be used. The subject, with its many ramifications, is treated extensively in Barnett and Lewis (1994), where tables needed to carry out such tests are given. If the observed value of the chosen statistic is large enough, H0 is rejected and Xn:n (or X1:n) becomes a candidate for further examination or rejection.
The foregoing approach is related closely to the following multiple decision procedure, illustrated on the balanced one-way classification with n ‘treatment’ means Xi, i = 1, …, n, each based on m replications. To test the null hypothesis H0 of equal population means µ1, …, µn against the ‘slippage’ alternative µ1 =…=µi−1 = µi+1 =…µn and µi = µ1 + ∆, where i and ∆ < 0 are unknown, n + 1 decisions may be taken, that is, D0:H0 holds or Di: the ith treatment mean has slipped to the right. Under the usual normal-theory assumptions, an optimal procedure at significance level α is to choose DM if / (e.g., David 1981, p. 226) Cn,ν = m (XM – X )/(TSS)1/2 > cn,υ;α, where M is the subscript corresponding to the largest Xi, TSS is the analysis of variance total sum of squares, and cn,v;α, with ν = n(m – 1), is given in Table 26a of Pearson and Hartley (1970 1972). If Cn,υ < cn,υ;α the decision D is taken. Slippage in either direction can be handled similarly with Table 26b.
In the above, the focus is on the detection of a single outlier or a single superior (or inferior) treatment. The handling of multiple outliers is an important part of Barnett and Lewis (1994).
6.4 Simultaneous Inference
Order statistics play an important supporting role in simultaneous inference procedures. A well-known example is Tukey’s use of the studentized range in setting simultaneous confidence intervals for the treatment means in fixed-effects balanced designs.
6.5 Robust Estimation
Here one gives up the classical idea of using an estimator that is optimal under tightly specified conditions in favor of an estimator that retains reasonably good properties under a variety of departures from the hypothesized situation. Since the largest and smallest observations tend to be more influenced by such departures, which include the presence of outliers, many robust procedures are based on the more central order statistics. A simple example is provided by the trimmed means
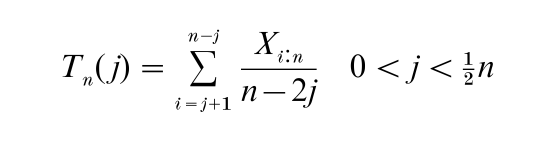
which include the sample median as a special case. For a very readable treatment of robust methods see Hoaglin et al. (1983).
6.6 Data Compression And Optimal Spacing
Given a large random sample of size n from a population with pdf, Eqn. (4), it is possible to estimate µ or σ or both from a fixed small number k of well chosen order statistics. The loss in efficiency of estimation may be more than compensated by the storage space gained, especially as a test of the assumed underlying distribution can still be made by probability plotting. For example, in the case of a normal population, the optimal estimator of µ is, for k = 4,
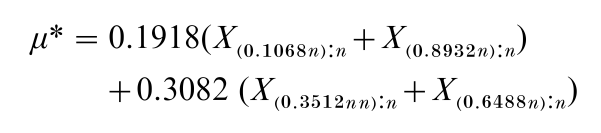
where (0.1068n) is the largest integer ≤ 0.1068n +1, etc. The estimator µ* has asymptotic efficiency (AE) 0.920 and, since it does not involve the more extreme order statistics, is more robust than X. Also, µ* is much more efficient than the median (AE = 0.637) (see, e.g., David 1981, Sect. 7.6).
7. Concluding Remarks
The two large multiauthored volumes (Balakrishnan and Rao 1998a, 1998b) cover many more topics in both theory and applications of order statistics than can even be mentioned here. Additional applications include ranked set sampling and especially the use of median, order-statistic, and other filters in signal and image processing.
Bibliography:
- Arnold B C, Balakrishnan N, Nagaraja H N 1992 A First Course in Order Statistics. Wiley, New York
- Balakrishnan N, Rao C R (eds.) 1998a Handbook of Statistics 16, Order Statistics: Theory & Methods. Elsevier, Amsterdam
- Balakrishnan N, Rao C R (eds.) 1998b Handbook of Statistics 17, Order Statistics: Applications. Elsevier, Amsterdam
- Barnett V, Lewis T 1994 Outliers in Statistical Data, 3rd edn. Wiley, New York
- David H A 1981 Order Statistics, 2nd edn. Wiley, New York
- David H A, Nagaraja H N 1998 Concomitants of Order Statistics. In: Balakrishnan N, Rao C R 1998a, (eds.) Handbook of Statistics 16, Order Statistics: Theory & Methods. Elsevier, Amsterdam, pp. 487–513
- Galambos J 1987 The Asymptotic Theory of Extreme Order Statistics, 2nd edn. Krieger, Malabar, FL
- Hahn G J, Meeker W Q 1991 Statistical Intervals: A Guide for Practitioners. Wiley, New York
- Harter H L, Balakrishnan N 1996 CRC Handbook of Tables for the Use of Order Statistics in Estimation. CRC Press, Boca Raton, FL
- Harter H L, Balakrishnan N 1997 Tables for the Use of Range and Studentized Range in Tests of Hypotheses. CRC Press, Boca Raton, FL
- Hoaglin D C, Mosteller F, Tukey J W (eds.) 1983 Understanding Robust and Exploratory Data Analysis. Wiley, New York
- Lloyd E H 1952 Least-squares estimation of location and scale parameters using order statistics. Biometrika 38: 88–95
- Nelson W 1982 Applied Life Data Analysis. Wiley, New York
- Pearson E S, Hartley H O (eds.) 1970/1972 Biometrika Tables for Statisticians, Vol. 1, 3rd edn., Vol. 2. Cambridge University Press, Cambridge, UK
- Sarhan A E, Greenberg B G (eds.) 1962 Contributions to Order Statistics. Wiley, New York
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality