
Sample Reading Nonalphabetic Scripts Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
1. The Japanese Language
Linguistically, Japanese does not relate to Chinese, Korean, or English, though it is similar to Korean in syntax, but not in speech sounds or vocabulary. However, Japanese has borrowed many words and characters, mainly from Chinese. Almost all indigenous people living in Japan speak Japanese, and ethnic Japanese living outside of Japan also do so. There are about 130 million Japanese speakers, and the language ranks sixth among the languages of the world after Chinese, English, Russian, Hindi, and Spanish.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
The Japanese language employs five vowels and 16 consonants. Compared to other languages such as English, the Japanese sound system contains few sounds. The Japanese sound system uses a unit called a ‘mora,’ which is a short beat, the time taken to pronounce a short syllable. The mora is the main unit in the Japanese language, and is also the unit of Japanese phonetic script—hiragana (or hirakana) and katakana. Each Japanese syllabary sign is based on a mora. There are 110 different moras, or syllables, in Japanese. It is one of the smallest inventories of any major languages. For example, there are 400 syllables in Chinese and several thousand in English. The small inventory of Japanese sounds gives rise to many homophones, but it is easy to represent the language by a simple syllabary.
The Japanese vocabulary consists of four word types: Japanese origin (47.5 percent), Sino-Japanese (36.7 percent; long ago adopted from China), foreign loan words (9.8 percent; mostly European adopted in modern times), and hybrids (6 per cent; Sino-Japanese or foreign word stems with Japanese endings).
2. The Japanese Writing System
The Japanese writing system consists of five kinds of script—kanji, hiragana, katakana, roman alphabet, and arabic numerals. Among these, the first three script types are employed most frequently in writing Japanese. Japanese text is therefore written using these five kinds of script, and it is also true that both the traditional vertical (tategaki) from top to bottom, and the horizontal ( yokogaki), from left to right, styles are used depending on the kind of being written. For example, newspapers are printed in takegaki style, whereas academic journals are printed in yokogaki style.
3. Kanji Script And Reading
As a result of waves of Chinese and Korean emigration to Japan during the fourth and seventh centuries AD, Chinese-based culture, mainly in the form of Confucian classics, medicine, and Buddhism, came to Japan. A writing system with Chinese characters was, therefore, the only script until two forms of syllabary, hiragana and katakana were created from kanji during the ninth century AD. ‘Kan-on’ kanji readings were borrowings from Confucian scholarship. Chinese ‘hanzi,’ associated with the Han Dynasty period, became Japanese ‘kanji,’ which remains the backbone of the Japanese writing system. As Japanese kanji borrowed Chinese hanzi in distinct historical periods, different pronunciations were adopted for these kanji, and makes reading complicated in modern writing systems. This feature of having multiple readings for many kanji characters in Japanese is different from those of Chinese and Korean, which have only a single reading.
The Japanese language uses not only Chinese and native readings of the logographic characters, but also several varieties of each type of reading, which makes the oral reading of characters complicated. For example, Mandarin Chinese read the simple character for ‘ten’ as one sound ‘shi,’ while the Korean reading is ‘sip’ (no tone or soundless). Both languages use only one reading, but Japanese speakers read the character as ‘to,’ ‘toh,’ ‘so,’ ‘jyu,’ ‘jutt-,’ all without tone (Taylor and Taylor 1995). The first three sounds are examples of Kun readings (Japanese native readings), while the others are ‘On’ readings (Chinese readings). The Kun reading is quite different from the Chinese because the two languages are unrelated. Besides the Kun reading, most kanji have one or more On readings which are not identical with Chinese sounds. Depending upon when and where the Chinese characters were borrowed, four different types of On reading (go-on, kan-on, toh-soh-on, and the habitual one) were agreed. Most Japanese kanji are given only one of the four types of On reading.
The number of kanji is enormous. Kanji dictionaries contain between 12,000 and 50,000 entries. In 1981, the Japanese Ministry of Education attempted to restrict the number of kanji as ‘joyo kanji’ to be used in the educational system. This contains 1945 kanji, but because almost all kanji possess both On and Kun readings, Japanese people therefore learn a total of 4084 kanji readings during their first 9 years of education. Generally, each kanji consists of a combination of radicals. There are 250 kinds of radical, each consisting of between one and 17 components (strokes). Most radicals consist of two to nine strokes (Ueda et al. 1993). As the number of kanji is so huge, this reduces any difficulty in understanding homophones. However, there is a clear asymmetry between reading and writing ability, and it is true that some adult Japanese fail to read even joyo kanji.
Cognitive psychologists once suggested that the processing route of reading depended on the type of orthography—that is, kanji has a single route from orthography to semantics, bypassing the contribution of phonological information, while the kana travel a phonological route to access semantics. But this is too simple an explanation. Recent reviews of kanji studies suggest that it is reasonable to conclude that, depending upon the task settings, familiarity, frequency, and complexity of kanji, one of the most efficient processing routes of phonology-based or grapheme-based routes (or both routes) is employed to access semantics (Kess and Miyamoto 1999). However, in the case of high-frequency and high-familiarity kanji, semantic access is achieved only through the grapheme-based route, and this is not specific to Japanese. There are examples in alphabetic systems where the cognitive route is also direct from grapheme to semantics.
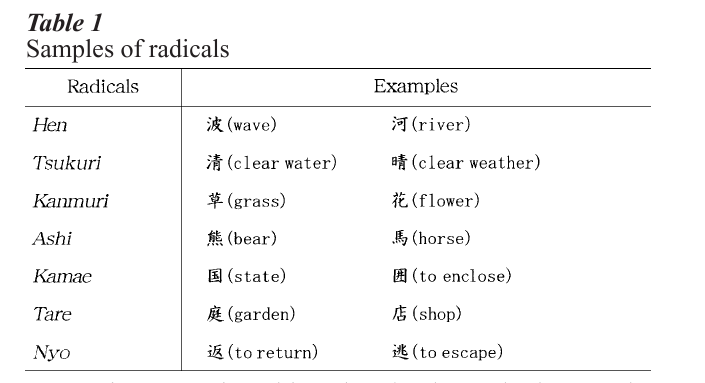
As shown in Table 1, complex kanji consist of semantic and phonetic radicals, hen (left hand), tsukuri (right hand), kanmuri (top), ashi (bottom), kamae (enclosure), tare (top-left), and nyo (bottomleft). Each acts differentially in reading. That is, generally, semantic radicals give clues to meanings, whereas phonetic radicals give clues to pronunciation. Research findings also suggest that the right hand radical is more informative than the left.
Many words in Japanese are represented not only by individual kanji but also by a compound which is a polysyllabic composite of between two and four kanji, usually carrying an On reading. More than 50 percent of the words in most Japanese dictionaries are compound kanji. Research findings also suggest that the reading processes of kanji compound words constitute another grouping. In addition to the frequency of the compound word itself, the first kanji of a compound is important, because the first kanji defines the range of possible collocations in the cohort of potential kanji compounds.
There is strong evidence that the individual kanji are processed as a recognition unit and kanji compounds themselves are also recognition units. A case has been that one agraphic patient was able to read the single kanji ‘hand’ and ‘paper’ but failed to read their coupling as ‘letter,’ while another patient had less difficulty in reading a compound word, but could not read the single kanji which constituted the compound word (Hatta et al. 1998). This double dissociation suggests that single and compound kanji words are stored with different addresses in the mental lexicon.
4. Kana Scripts And Reading
In addition to kanji, there are two syllabary types of script in Japanese—hiragana and katakana (see Table 2). The kana unit represents a sound unit, which corresponds roughly to a syllable. Both scripts contain 46 basic symbols and 25 additional symbols with diacritic marks. Hiragana and katakana share the same syllabic reference points, therefore the same syllable can be written by either system. Hiragana is cursive, as shown in Table 2, and used mainly for some content words, morphological endings, function words, and the rest of the grammatical scaffoldings of sentences. In contrast, katakana is angular in shape and is used for writing foreign loan words.

Kana developed gradually out of Chinese characters in the following order—kanji, kanji as phonetic signs, simplified kanji shapes, and kana. During this development, mainly female authors used hiragana to write letters, poems, diaries, and stories; this is because hiragana is a graceful, cursive form of its original kanji. For a long time, it has been the convention that a cursively simplified hiragana is used for grammatical morphemes, and the angular simplified katakana is used for foreign loan words and onomatopoeia. However, an explanation for the use of both types of script because of differing roles in syntax cannot be the only reason why the Japanese have kept three kinds of script usage irrespective of high cost. Japanese people might have found it useful or convenient to express semantic emotional information by employing different types of script.
Conventionally, there is a connection between orthography type and the words used. This has a strong effect on Japanese word readings. Japanese people possess a strong, emotional semantic image for each type of script—kanji is seen as masculine, hiragana feminine, and katakana exotic. Japanese people sometimes employ this emotional image of a script when writing, irrespective of the conventional usage of scripts and words. For example, reading experiments suggested that when Japanese people see the kanji word for chair , an image of an old-fashioned, strongly-built chair is generated; when they see the katakana word for chair, they imagine a modern and elegant chair; and in the case of the hiragana word for chair , they may imagine a simple wooden chair (Ukita et al. 1996).
5. Summary Of Research Findings In Cognitive And Neuropsychological Studies
The results of earlier cognitive psychological experiments suggest that orthographic configurations can be used to access directly phonological form, meaning, or both, depending on the processing task requirement. Although the role and the importance of these factors may differ for each orthography in respect to the processing strategy favored and the processing times required, Japanese seems not to be an exceptional writing system, but possesses idiosyncratic requirements of the world’s writing systems.
However, neuropsychological studies have suggested that kanji and kana are processed differentially and stress the importance of orthography difference in reading (Iwata 1984, Yamadori 1975). In alexia with agraphia due to angular gyrus lesions, kana reading is impaired more severely than kanji, whereas left posterior–inferior temporal lesions impair kanji reading (Iwata 1984, Kawamura et al. 1987). These findings support the hypothesis that there are two pathways of reading in Japanese: one is the ventral pathway from the visual area in the occipital cortex via the posterior part of the inferior and middle temporal gyli of the left hemisphere, which is used in semantic reading of kanji; the other is the dorsal route from the visual area via the angular gyrus to Wernicke’s area, and is used for the phonological processing of kana reading.
Regarding the visual half field, several studies have revealed that the right hemisphere contributes more than the left in kanji recognition. For example, a tendency toward a right hemisphere advantage was reported in the case of single kanji (Hatta 1977), and in the case of two-kanji non-word pairs (Sasanuma et al. 1977). On the other hand, a left hemisphere advantage was reported in the case of two-kanji compound words (Hatta 1978). By employing a very recent new research method (MEG), Koyama et al. (1998) revealed that not only the left but also the right hemisphere is activated in reading kanji words, and support the view of the right hemisphere engagement in kanji reading. These studies suggest that hemisphere function in kanji reading is not the same as in the reading of English and kana words.
The discrepancy between cognitive psychological and neuropsychological research findings in Japanese reading leaves us to conclude that there is a language non-specific cognitive processing in reading. Further studies concerning non-alphabetical scripts are necessary to answer this question.
Bibliography:
- Hatta T 1977 Recognition of Japanese kanji in the left and right visual fields. Neuropsychology 15: 685–88
- Hatta T 1978 Recognition of Japanese kanji and Hiragana in the left and right visual fields. Japanese Psychological Research 20: 51–9
- Hatta T, Kawakami A, Tamaoka K 1998 Writing errors in Japanese kanji. Reading and Writing 10: 457–70
- Iwata M 1984 Kanji versus kana: Neuropsychological correlates of the Japanese writing system. Trends in Neuroscience 7: 290–93
- Kawamura M, Hirayama K, Hasegawa K, Takahashi N, Yamaura A 1987 Alexia with agraphia of kanji (Japanese morphograms). Journal of Neurology, Neurosurgery and Psychiatry 50: 1125–29
- Kess J F, Miyamoto T 1999 The Japanese Mental Lexicon. Benjamins, Amsterdam
- Koyama S, Kakigi R, Hoshiyama M, Kitamura Y 1998 Reading of Japanese kanji (morphograms) and kana (syllabograms): A magneto-encephalographic study. Neuropsychology 36: 83–98
- Sasanuma S, Itoh K, Mori K, Kobayashi Y 1977 Tachistoscopic recognition of kana and kanji words. Neuropsychology 15: 547–53
- Taylor I, Taylor M M 1995 Writing and Literacy in Chinese, Korean, and Japanese. Benjamins, Amsterdam
- Ueda M, Okada M, Iijima T, Sakaeda T, Iida D 1993 Shin Daijiten. Kodansha, Tokyo
- Ukita J, Sugishima M, Minagawa M, Inoue M, Kashu K 1996 Psychological Research on Orthographic Forms in Japanese. Psycholology Monographs 25, Japanese Psychological Association
- Yamadori A 1975 Ideogram reading in alexia. Brain 98: 231–8
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality