
Sample Corpus Linguistics Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. iResearchNet offers academic assignment help for students all over the world: writing from scratch, editing, proofreading, problem solving, from essays to dissertations, from humanities to STEM. We offer full confidentiality, safe payment, originality, and money-back guarantee. Secure your academic success with our risk-free services.
Corpus linguistics encompasses the compilation and analysis of collections of spoken and written texts as the source of evidence for describing the nature, structure, and use of languages. Developing out of a long tradition of using texts rather than introspection, intuition, or elicitation as the empirical basis for linguistic description and argumentation, corpus linguistics is a methodology or approach for undertaking linguistic description. It is not a theory of language or a separate branch of linguistics such as morphology or sociolinguistics. Indeed, by providing sources of authentic, not made-up, examples of linguistic items, structures, or processes, the use of corpus-based evidence can complement other methodologies used by linguists. This evidence can be used for testing hypotheses, validating the accuracy of descriptions, making generalizations, and answering research questions which arise from theories of language or practical language-related issues in society.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
With texts in electronic form as the source of linguistic data, and the speed and reliability of computers to assist analysis, the particular contribution of modern corpus linguistics has been to bring an additional quantitative dimension to linguistic description. On the basis of their occurrence in corpora, linguistic features can be shown to have different probabilities of occurrence in a language according to genres or domains of use. Thus, for example, Francis and Kucera (1982) showed that in US written English almost 15 percent of the verb predications in in-formative prose occur in the passive voice whereas in fiction, only about 4 percent of the predications are passive. Further, even within informative prose genres there can be considerable variation, with press re-portage averaging about 13 percent passives and academic writing across many subject fields averaging 22 percent. Passive voice sentences can occur with an agent (e.g., ‘These results were anticipated by the market’). However, in texts from academic sources over 85 percent of passive voice predications typically occur without an agent. Corpus-based linguistic descriptions typically show not only what items, structures, or processes are possible, but which ones are probable in particular domains of use, thus inviting explanations of why this should be so. It can be argued that by including a quantitative dimension as part of descriptive adequacy, corpus linguistics has helped bring to the study of language a concern for distribution which is characteristic of other sciences.
1. Pre-Electronic Corpora
Although corpus-based linguistics since the 1960s has been associated with texts stored and analyzed on computers, the use of texts as the basis for linguistic description goes back well before electronic computers became available (see Kennedy 1998). In particular we may note the use of texts in lexicography, the study of the meaning and use of words. For example, the first edition of the Oxford English Dictionary, which was completed in 1928 after 70 years’ work, was based mainly on the analysis of a collection of citations, totaling perhaps 50 million words, from texts from the canon of English literature, representing the use of written English over a period of 800 years.
Educationalists and linguists in the USA also used corpora of up to 18 million words in the first half of the twentieth century to discover the most frequently used words in English so as to develop better curricula for improving literacy education. This work of Thorndike, Sapir, and others was also very influential in the development of language teaching methodology. Their work was carried further in the UK by West and others and had a major impact on the methodology used for the teaching of English to speakers of other languages in substantial parts of Africa and Asia.
The first corpus compiled on a principled basis to be ‘representative’ of a language was the Survey of English Usage Corpus (SEU). Begun in1959 the SEU consists of 200 samples, each of 5,000 words, from some 24 genres of spoken and written British English. Al- though the corpus was not initially in machine- readable form, the spoken half of the SEU was eventually made available in electronic form as the London–Lund Corpus, until recently the largest available corpus of transcribed spoken language. The SEU marked the beginning of modern corpus linguistics and led to a large number of studies of English, culminating in the most extensive modern description of English grammar—A Comprehensive Grammar of the English Language (Quirk et al. 1985).
2. Computer-Based Corpus Linguistics
Computers have given new impetus to corpus linguistics. The first computerized corpus designed for linguistic research was the Brown Corpus of con-temporary written American English, compiled by Francis and Kucera. The one-million-word Brown Corpus consists of 500 text samples, each of 2,000 words representative of material printed in the USA in the year 1961. It became available in 1964. The careful design of the Brown Corpus with texts sampled from some 42 genres of informative and imaginative prose, the speed with which it was com-piled and the way it was made freely available for linguistic research set new standards. It is noteworthy that although this first electronic corpus was compiled in the USA and there was an academic tradition there of text-based linguistic analysis and educational applications, most of the major developments in corpus linguistics for the next three and half decades came from Europe. These included the compilation of corpora for linguistic research, software development, and published research. This was partly because the direction of linguistic theory and research in the USA became dominated from the early 1960s by the influence of Noam Chomsky and attention shifted away from the observation of linguistic behavior (‘performance’) to a more epistemological focus (‘competence’), with the study of performance ceasing to be normative except within subdisciplines such as sociolinguistics.
Following the compilation of the SEU and Brown Corpora, one million words became for a time the typical corpus size. This was brought about partly because one-million-word corpora were found to provide a reliable basis for many types of linguistic description, and because initially there were limitations in computer processing capacity and difficulty in getting machine-readable versions of texts before electronic text storage and optical scanning became more readily available. Until the mid-1980s most corpora had to be compiled through laborious key-boarding. A number of one-million-word corpora with the same basic design as the Brown Corpus were compiled in the 1970s and 1980s. These included, for example, the Lancaster–Oslo–Bergen Corpus (LOB) of written British English, the Kolhapur Corpus of written Indian English, and the Wellington Corpus of Written New Zealand English. All of these corpora and others of similar size compiled for synchronic or diachronic linguistic research purpose are available on CD-ROM from the International Computer Archive of Modern and Medieval English (ICAME) which also distributes the most complete bibliographic resources on corpus-based descriptions of English.
Although a high proportion of corpus-based re-search has been on English, there are now hundreds of corpora in existence, not only in English but in many other languages. Some have been compiled for commercial purposes such as dictionary making. Many others are available for research purposes and can be analyzed on personal computers (see Biber et al. 1998). Further information about corpora can be found in the journals International Journal of Corpus Linguistics and Computational Linguistics and through organizations such as the Linguistic Data Consortium and the European Corpus Initiative.
In addition to the central focus on linguistic description, the study of the phonology, morphology, syntax, and discourse structure of languages, con-temporary work in corpus linguistics has focused on four other main areas of activity:
(a) corpus design and compilation;
(b) the development of automatic grammatical annotation of corpora by means of word-class tagging and parsing to assign constituent structures;
(c) methodology for linguistic analysis using corpora; and
(d) applications of corpus-based linguistic descriptions to assist the development of natural language processing and language teaching.
(a) Corpora which are designed for linguistic analysis differ according to the purpose for which they are compiled. Some are highly structured and attempt, by judicious sampling in different domains of use, to be representative of a language or language variety. Such general or ‘balanced’ corpora are used for making generalizations about a wide variety of linguistic phenomena.
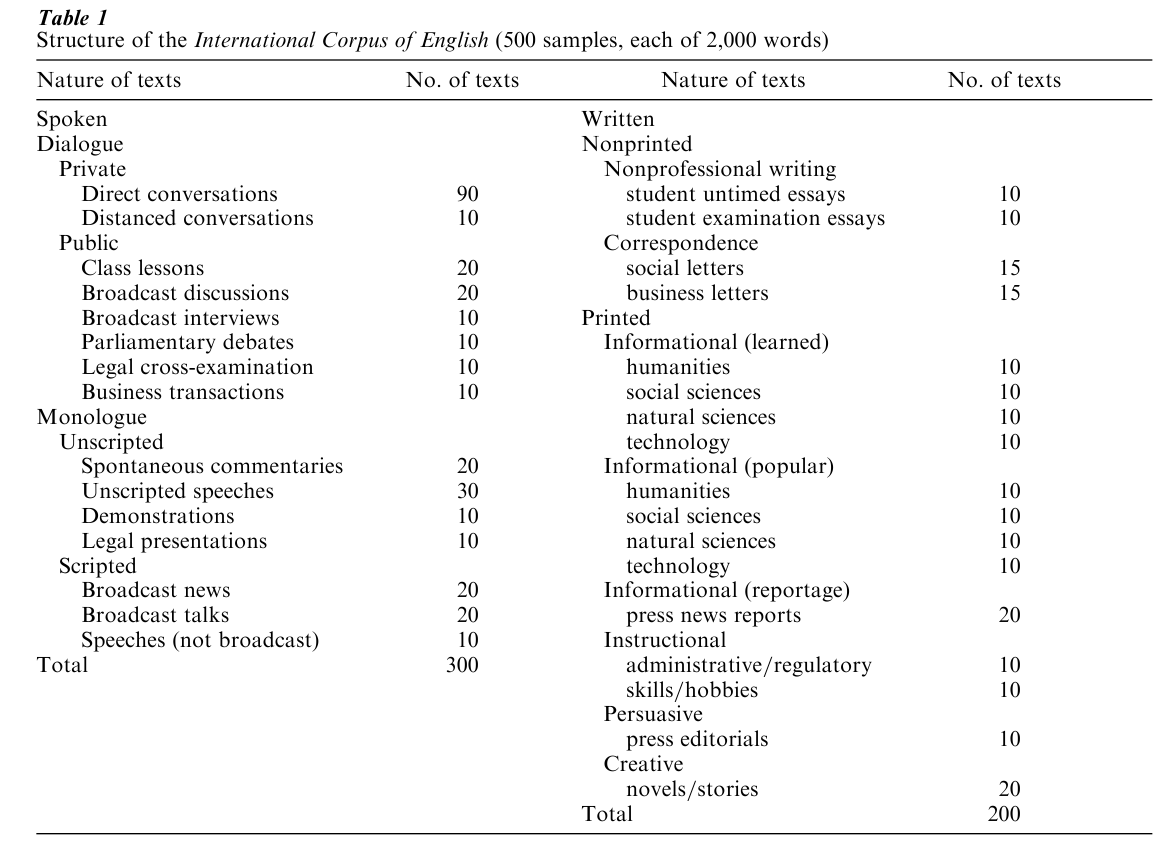
Corpora are also compiled for particular specialized research, such as how speakers bid for turns in conversation, how language develops in children, how teachers use directives in classrooms, the vocabulary and grammatical structures most frequent in academic writing in the social sciences, telephone conversations among familiars, or how a language such as English has developed across the centuries. Corpora are compiled in different ways, with some consisting, for example, of samples from many texts, others consisting of whole texts, the complete works of an author, or all the issues of a newspaper over decades (see Kennedy 1998). By way of illustration, Table 1 shows the structure of one of the most recent and ambitious structured corpus projects, the International Corpus of English (ICE). This project, when completed, will include 20 one-million-word corpora of English (60 percent from spoken sources) compiled in different parts of the world from texts produced in the 1990s. In addition to the whole corpus forming a representative sample of English as an international language, the 20 individual subcorpora can be the basis of comparative studies of regional varieties of English. The British section of ICE, the first section publicly available, comes equipped with sophisticated search and retrieval software for automatic lexical and grammatical analysis.
For lexicographical purposes and the study of low-frequency words or processes, however, corpora need to be much larger than one million words, in order to provide enough instances of individual items to enable valid and worthwhile generalizations to be made. One of the most notable large structured corpora is the British National Corpus (BNC) This corpus of 100 million words (10 percent spoken sources) is carefully designed to represent British English in the 1990s. it has been sponsored by a consortium of government, leading universities, and publishers and has brought significant changes to our understanding of the lexical, grammatical, and discoursal resources of British English.
However, size or structure does not necessarily make a corpus representative. A major issue in corpus linguistics has been whether corpora should be structured at all. Corpora such as the Bank of English are huge, heterogeneous and rapidly expanding col-lections of texts of all kinds added to the corpus as opportunity arises. Such ‘dynamic’ or ‘monitor’ corpora do not have a particular structure or finite size. In some ways, they resemble the even larger text databases of parliamentary proceedings, literary works or newspaper archives now available which can also be used for linguistic research. The rapid expansion of the Internet also provides potential sources of text for certain types of linguistic description. For example, where it is difficult to find enough tokens of low frequency words in a corpus to provide reliable lexicographical description, Internet search engines can often provide more than enough. In the final analysis, because any corpus is useful only so far as it makes possible answers to particular questions, corpora may be best categorized by the uses to which they can be put rather than by their design features.
(b) The automatic grammatical annotation of texts has become increasingly important. Specifically, the identification and counting of words, collocations and grammatical structures in a corpus can be greatly facilitated when variant forms of the same word (e.g., book books, go went) are represented by a single form (‘lemmatization’) and when all words in a corpus are tagged to show their appropriate word class, and parsed to show their grammatical function as part of the constituent structure of sentences. Such text annotation not only serves linguistic description but can be a prerequisite for other applications of corpus analysis associated with natural language processing.
(c) Particular techniques and procedures have come to be associated with corpus-based analysis. To some extent, available computer software has influenced these methodologies. In addition to producing word lists showing the frequency of occurrence of each word type, corpus-based analysis has depended heavily on concordancing. A concordance is a list of all the occurrences (‘tokens’) of a particular word or phrase in a corpus in the context of a given number of preceding and following words. Concordancing soft-ware has led to a focus on words and on ‘collocations,’ the company a word typically keeps. For example, linguists have noted that English intensifiers such as very, quite, pretty, terribly have a tendency to precede particular adjectives (e.g., terribly nice, pretty horrible). Corpus-based research on collocations has led increasingly to the recognition that a high proportion of what people say or write consists of prefabricated ‘formulaic’ groups of words (e.g., pouring rain, strong tendency, at the moment), thereby blurring somewhat the distinction between lexis and grammar.
(d) Important applications of corpus linguistics have occurred in the fields of natural-language processing (NLP) and second-language teaching. Research has been undertaken by computational linguists and others to make progress on the automatic lemmatization, tagging, and parsing of text. Rule-based approaches to annotation have sometimes been used, but increasingly some of the most promising NLP research has employed corpus-based statistical in-formation on the probability of occurrence of linguistic items or processes as a basis for advances in automatic word-class tagging, parsing and disambiguation. Such information is prerequisite for developments in the retrieval of information from databases, speech recognition, speech synthesis, and automatic language translation.
Within second language teaching for the last 80 years there has been a continuing but by no means universal concern among curriculum designers and teachers as to which linguistic items or processes are most likely to be needed by language learners. In English for example, fewer than 100 words typically account for half of all the words used, and about 3,000 words account for 90 percent. According to Biber et al. 1999, just 12 English verbs account for nearly 45 percent of all lexical verbs in conversation. Many language teachers have known since the 1960s that although English verb phrase morphology appears complex and fraught with possibilities, the simple present and simple past tenses account for over 80 percent of all verb phrase structures in most corpora. Similarly, more recent work has shown that there is a much greater tendency for prepositional phrases rather than relative clauses to be used in English postnominal modification (e.g., The person in the car was alone is likely to be much more frequent than the person who was in the car was alone).
3. Current Issues And Directions
Corpus research has resulted in descriptive studies of all levels of language. Some of the most innovative work has been on linguistic variation. Biber (1988), for example, pioneered the corpus-based study of how the distribution of linguistic items in texts and the patterns of co-occurrence of these items could be used to characterize the ways in which languages vary diachronically and synchronically in different regional and sociolinguistic contexts. However, frequency of occurrence is not an end in itself. With easier avail-ability of corpora, more powerful computers and more sophisticated software, corpus linguists have new opportunities to move beyond describing the structure and quantitative distribution of linguistic features. Some of the best work in corpus linguistics continues to involve the judicious use of manual analyses supported by the computer. There are opportunities for corpus linguists to illuminate the significance of distribution, and to use corpora to test hypotheses and the robustness of linguistic theories. In focusing on the ways in which language users habitually express themselves, corpus linguistics has already thrown new light on how languages vary systematically in different regional and sociolinguistic contexts, genres, and registers. There is potential to provide further insights on the speed and direction of language change and on the factors which contribute to change. Corpus linguistics may also come to give greater support to work in cognitive linguistics through further exploration of the semantic roles and functions of linguistic features.
Bibliography:
- Aijmer K, Altenberg B (eds.) 1991 English Corpus Linguistics. Longman, London
- Biber D 1988 Variation across Speech and Writing. Cambridge University Press, Cambridge, UK
- Biber D, Conrad S, Reppen R 1998 Corpus Linguistics: Investigating Language Structure and Use. Cambridge University Press, Cambridge, UK
- Biber D, Johansson S, Leech G, Conrad S, Finegan E 1999 Longman Grammar of Spoken and Written English. Longman, London European Corpus Initiative. http://www.cogsci.ed.ac.uk/elsnet/eci.html
- Francis W N, Kucera H 1982 Frequency Analysis of English Usage: Lexicon and Grammar. Houghton Mifflin, Boston
- Garside R, Leech G, Sampson G (eds.) 1987 The Computational Analysis of English: A Corpus-based Approach, Longman, London
- Greenbaum S (ed.) 1996 Comparing English Worldwide: The International Corpus of English. Clarendon Press, Oxford, UK
- International Computer Archive of Modern and Medieval English (ICAME). http://nora.hd.uib.no./whatis.html
- Johansson S, Hofland K 1989 Frequency Analysis of English Vocabulary and Grammar. Clarendon Press, Oxford, UK
- Johansson S, Stenstrom A-B 1991 English Computer Corpora: Selected Papers and Research Guide. Mouton de Gruyter, Berlin
- Karlsson F, Voutilainen A, Heikkilo J, Antilla A (eds.) 1995 Constraint Grammar: A Language-independent System for Parsing Unrestricted Text. Mouton de Gruyter, Berlin
- Kennedy G 1998 An Introduction to Corpus Linguistics. Long-man, London, UK Linguistic Data Consortium. http://www.ldc.upenn.edu
- Quirk R, Greenbaum S, Leech G, Svartvik J 1985 A Comprehensive Grammar of the English Language. Longman, London, UK
- Scott M 1996 WordSmith. Oxford University Press, Oxford, UK
- Sinclair J 1991 Corpus, Concordance, Collocation. Oxford University Press, Oxford, UK
- Svartvik J (ed.) 1992 Directions in corpus linguistics. Proceedings of Nobel Symposium 82, Stockholm, 4–8 August 1991. Mouton de Gruyter, Berlin
- Thomas J, Short M (eds.) 1996 Using Corpora for Language Research. Longman, London
- Tottie G 1991 Negation in English Speech and Writing. Academic Press, London
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality