
Sample Nonlinear Phonology Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
Nonlinear phonology is a loose collection of relatively recent theories that address various aspects of the sound structure of human languages. Traditional approaches to phonology are linear, which means that they represent each word as nothing more than a string of speech sounds (called segments). Each segment is a bundle of its phonetic attributes, called distinctive features, but no further structure is assumed. Nonlinear phonology posits a richer architecture: segments are organized into a hierarchy of constituents, such as the syllable, the stress foot, and so on; and distinctive features are liberated from the segmental feature-bundle, allowing them to have domains that are larger or smaller than a single segment. This research paper examines some of the consequences of this hypothesis, focusing on two particular implementations of it.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
1. Historical Background
Before the mid-1970s, most research in phonological theory started from the assumption that segments are linked together like beads on a string. In this view, phonological representations are very similar to alphabetic writing, with exactly one symbol standing for each segment and with little or no structure beside the linear order of the segments in a word.
The best known theory of this general type is the one in Chomsky and Halle’s (1968) The Sound Pattern of English (SPE). The SPE theory is rigorously and consistently linear: for example, syllables play no role at all, and constituents such as the word have only a derivative status. The only departure from the alphabetic model is that each segment is assumed to be a bundle of distinctive features standing for its various attributes (such as nasal, voiced, rounded lips, and so on.
During the 1940s, two important precursors to contemporary nonlinear phonology emerged independently in the work of J. R. Firth and Zellig Harris. They shared the idea that phonological properties could have domains larger than a single segment. For example, in the South American language Terena, the meaning of ‘I’ or ‘my’ is marked by nasalizing (indicated by a tilde) a sequence of segments beginning at the left edge of the word: owoku ‘house’, owo gu ‘my house’; arine ‘sickness’, arıne ‘my sickness’. Firth or Harris would say that the domain of nasality in Terena is (approximately) the word. Their theories did not have much influence, though, and their work was largely neglected for several decades.
2. Nonlinear Phonology
In reaction to SPE’s strongly segmental orientation, the mid-1970s saw a profusion of nonlinear approaches to phonological phenomena, supplying ideas and insights that continue to be studied in the present day. These models were developed to address empirical problems that had been disregarded or treated unsatisfactorily in SPE: tone, long distance assimilation processes, syllables, the typology of stress systems, and the interaction of phonology with morphology and syntax.
Two leading ideas have emerged. One is autosegmentalism, the notion that distinctive features, rather than segments, are the atoms of phonological representation. (This term was coined by John Goldsmith.) From an autosegmental perspective, a distinctive feature is not an attribute of a segment, as in SPE, but a free standing entity. This status allows the feature to act independently of its segmental host, approximately as in Firth’s and Harris’s theories. The other leading idea is the prosodic hierarchy (a phrase coined by Elisabeth Selkirk), which organizes segments into successively larger constituents such as the syllable or word. The prosodic constituents are analogous to the more familiar syntactic constituents such as sentence or noun phrase, and, as in syntax, structural requirements imposed on the constituents are an important analytic tool.
Autosegmentalism and the prosodic hierarchy are complementary, not competing, hypotheses. As a matter of logic, they are not mutually exclusive, since autosegmentalism speaks to the nature of subsegmental units (distinctive features), while the prosodic hierarchy is a claim about how segments themselves are organized into larger groupings. They have also been applied to factual domains that are mostly distinct. Autosegmentalism helps to solve problems in tone and featural phonology, such as assimilation. The prosodic hierarchy is important in understanding the phonology of syllables, stress, words, and phrases.
Autosegmentalism and the prosodic hierarchy are, ultimately, claims about how language is represented in the human mind. Though they allow for a considerable range of variation between languages, they also have a core that is claimed to be universal. Hence, the main evidence for these theories comes from observations about phenomena that recur in many languages.
The rest of this research paper discusses the implementation of these two aspects of nonlinear phonology, the their present and future prospects.
3. Autosegmental Phonology
The following example illustrates one of the key arguments for autosegmentalism. Some speakers of the Bantu language Sanga use a secret language (analogous to pig Latin in English) called Kinshingelo. Words in this secret language are formed by systematically permuting the segments of Sanga words, as in the following example:
Sanga
baa.ko.lwee baa.dyaa ma.ta.ba aa. kaa.mbo
Kinshingelo
baa.lwe.koo dyaa.baa ma.ba.ta aa.mboo. ka
Gloss
‘The birds are eating my grandfather’s corn.’
The accents mark tones: acute o is high and grave o is low. Double vowels are long, so aa stands for a long a vowel with a rising (i.e., low–high) tone. For ex- pository convenience, syllable divisions have been indicated with a full stop.
A Kinshingelo word is formed by swapping the last two syllables of each Sanga word. But not precisely: the segments themselves are swapped, but their tones and length are not. Speakers of Sanga unconsciously regard aa as somehow divisible into three components: a part that describes the action of the tongue and lips in forming consonants and vowels, a part that de- scribes the action of the larynx in controlling tone, and a part that describes the duration of the vowel. A useful analogy is an orchestral score, which contains distinct but coordinated instructions for many, different instruments. This is the central insight of autosegmental phonology: speech sounds consist of independent components which are coordinated in time.
Tone is the premier example of an independent component of speech, and in fact autosegmental phonology was first developed to deal with tone. Some other consequences of autosegmentalism for the analysis of tone include:
(a) Persistence under deletion. When a vowel deletes, its tone may remain and attach itself to some nearby vowel.
(b) Floating tones. When a vowel deletes, its tone may remain and express itself indirectly, by affecting following tones.
(c) Toneless syllables. Some syllables have no tonal specification at all. Their pitch is determined by linear interpolation between syllables that have tones.
(d) Tone shift. In the Bantu language Kikuyu, every tone shifts exactly one syllable to the right, domino fashion, so /tomatomaγa/ becomes tomatomaγa
(e) Tone melodies. In some languages, words are limited to a small set of fixed tone melodies, or tone melodies may mark certain morphological distinctions.
In sum, tones and segments may behave independently of one another. This is the expected result of the autosegmental hypothesis.
Not long after it was developed, autosegmental phonology was applied to nontonal phenomena as well. The idea is that every distinctive feature—[nasal], [voiced], and so on—occupies its own separate auto-segmental ‘tier,’ allowing it to function independently of segments or other features. The main focus of research in this area has been on two related problems:
In assimilation, one segment (the target) takes on some of the features of another, nearby segment (the trigger). Harmony is a kind of long distance assimilation, where the triggering segment and its target are not necessarily adjacent. Here are some examples from the South American language Warao, and the North American language Chumash:
(a) Warao /moaupu/ → moaupu ‘give them to him’
(b) Chumash /k-sunon-s/ → ksunons ‘I am obedient’
In Warao, the feature [nasal] assimilates, affecting a potentially unbounded sequence of vowels after a nasal consonant. In Chumash, the feature [anterior] assimilates, changing s to s (the initial consonant in ship) if followed anywhere in the word, at whatever, distance, by another s.
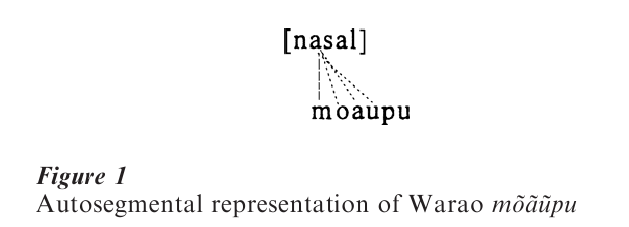
Autosegmentalism contributes to the understanding of these processes in two ways. First, it provides a natural interpretation of assimilation. Because features and segments are independent, the domain of a feature can be larger than a single segment. Assimilation expands the domain of a feature from one segment to many. Second, autosegmentalism allows long distance harmony processes to be analyzed as local on the tier of the assimilating feature. These two key insights are usually expressed graphically, as in Fig. 1. The feature [nasal] is shown on its own autosegmental tier, separate from the rest of the segment. Temporal coordination between [nasal] and the rest of the segment is indicated by association lines. The solid association line is original, while the dotted association lines are the result of the process of assimilation. The effect of assimilation here is to expand the domain or scope of [nasal] to include the vowels oau.
The most radical autosegmental theory is one in which every distinctive feature is on a separate tier, with complete freedom to act independently of all other features. This view cannot be right, because there are strong functional associations among various subsets of the features. For example, the features that characterize states of the larynx have a considerable degree of cohesion in phonological systems, assimilating or neutralizing together.
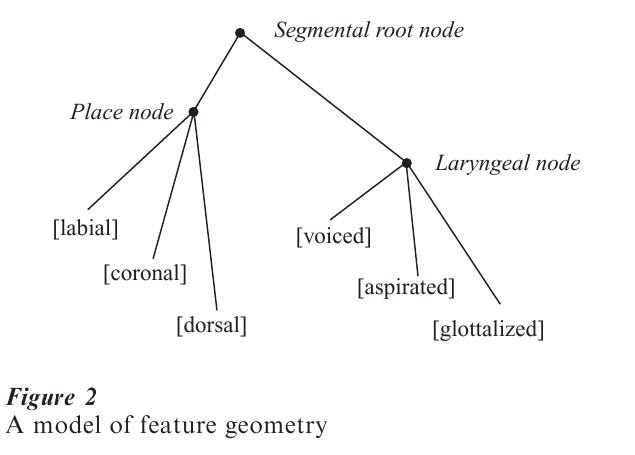
Functional groupings of features are addressed in theories of feature geometry. (This term was proposed by G. N. Clements.) The idea is to posit a layer of representation between the segment and the features. Elements of this intermediate layer, called class nodes, are constituents corresponding to the observed functional groupings. A typical implementation, abstracting away from controversial details, appears in Fig. 2. The laryngeal features often act together in phonological processes, and so there is a constituent, the Laryngeal node, that unites them. Similarly, a single process will often affect the various features that distinguish p from t from k, and so there is a constituent, the Place node, to unite them as well. Feature geometry, like autosegmental phonology itself, is claimed to be universal. Research in this framework is oriented toward discovering a set of class nodes that will account for all (or at least all common) phonological processes in the world’s languages.
4. The Prosodic Hierarchy
The term prosody is used by phonologists to refer to the durational, rhythmic, and phrasing aspects of speech. The study of prosody includes syllables, stress, restrictions on the size or shape of words, and many of the ways in which morphology or syntax can affect pronunciation.
A key insight into the nature of prosody is the idea of a small, universal set of prosodic categories arranged into a hierarchy (see Fig. 3). Certain additional assumptions give the hierarchy predictive value:
(a) Grouping and layering. Level n of the hierarchy imposes a grouping structure on the layer just below it, level n – 1.
(b) Headedness. Every constituent at level n designates a specific, most prominent constituent at level n – 1 as its head.
(c) Structural requirements. There are global and parochial conditions on the well-formedness of constituents. For example, languages frequently require that feet be binary, and there is also evidence of binarity conditions on other levels of the prosodic hierarchy. So, proceeding from the bottom of the hierarchy, a syllable is a grouping of segments; the head of the syllable is the peak of acoustic energy, usually a vowel. A foot is a grouping of (usually two) syllables, one of which is more prominent than the other. The more prominent syllable is the locus of linguistic stress. A phonological word is a grouping of feet, one of which is also the most prominent (the locus of main stress). A phonological phrase is a grouping of phonological words that also includes a most prominent member, and so on.

Results of surprising subtlety and generality can be derived from these modest premises. For example, many languages set a lower bound on the size of the phonological word. The Australian language Diyari is typical in this respect: it has no monosyllabic words at all. This so-called minimal word requirement follows from joint action by three different constraints: layering (the phonological word dominates the foot in the prosodic hierarchy); headedness (every word must contain at least one foot, to serve as its head); and a structural requirement that feet be binary, since they are the basic units of stress rhythm. Comparable results can be found at other levels of the prosodic hierarchy.
5. Present And Future Prospects
Nonlinear phonology has been an active area of research since the late 1970s. The basic autosegmental hypothesis enjoys wide and perhaps universal acceptance. Various details are matters of debate, however:
- Do all features have the same autosegmental status as tone?
- Is feature geometry an appropriate model of featural organization?
- If so, exactly how are the features organized?
- Are (binary) features the appropriate units of subsegmental structure?
The prosodic hierarchy is somewhat more controversial. Although notions of constituency do play a role in most theories of prosody, there are also models that are partly or entirely constituent-free.
In recent years, much research has focused on the ways in which Optimality Theory can illuminate topics in nonlinear phonology. A particularly productive line of investigation has been the study of constraints that align the edges of prosodic constituents with morphological or syntactic ones. These constraints relate the prosodic hierarchy to the hierarchy of grammatical constituents, offering a new perspective on the interface between phonology and grammar.
Bibliography:
- Chomsky N, Halle M 1968 The Sound Pattern of English. Harper & Row, New York
- Clements G N 1985 The geometry of phonological features. Phonology Yearbook 2: 225–52
- Clements G N, Keyser S J 1983 CV Phonology: A Generative Theory of the Syllable. MIT Press, Cambridge, MA
- Goldsmith J A 1990 Autosegmental and Metrical Phonology. Blackwell, Oxford, UK
- Hayes B 1995 Metrical Stress Theory: Principles and Case Studies. University of Chicago Press, Chicago
- van der Hulst H, Smith N 1985 The framework of nonlinear generative phonology. In: van der Hulst H, Smith N (eds.) 1985 Advances in Nonlinear Phonology. Foris Publications, Dordrecht, The Netherlands
- Kenstowicz M 1994 Phonology in Generative Grammar. Blackwell, Cambridge, MA
- Liberman M, Prince A 1977 On stress and linguistic rhythm. Linguistic Inquiry 8: 249–336
- McCarthy J, Prince A 1993 Generalized alignment. In: Booij G, van Marle J (eds.) 1993 Yearbook of Morphology. Kluwer, Dordrecht, The Ntherlands
- McCarthy J, Prince A 1995 Prosodic morphology. In: Goldsmith J A (ed.) 1995 The Handbook of Phonological Theory. Blackwell, Oxford, UK
- Nespor M, Vogel I 1986 Prosodic Phonology. Foris, Dordrecht, The Netherlands
- Odden D 1995 African tone languages. In: Goldsmith J A (ed.) 1995 The Handbook of Phonological Theory. Blackwell, Oxford, UK
- Pierrehumbert J, Beckman M 1988 Japanese Tone Structure. MIT Press, Cambridge, MA
- Selkirk E 1981 On the nature of phonological representation. In: Laver J, Meyers T, Anderson J (eds.) The Cognitive Representation of Speech. North-Holland, Amsterdam
- Selkirk E O 1984 Phonology and Syntax: The Relation Between Sound and Structure. MIT Press, Cambridge, MA
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality