
Sample Educational Assessment Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. iResearchNet offers academic assignment help for students all over the world: writing from scratch, editing, proofreading, problem solving, from essays to dissertations, from humanities to STEM. We offer full confidentiality, safe payment, originality, and money-back guarantee. Secure your academic success with our risk-free services.
The role of assessment and evaluation in education has been crucial, probably since the earliest approaches to formal education. However, change in this role has been dramatic in the last few decades, largely due to wider developments in society. The most dramatic change in our views of assessment is represented by the notion of assessment as a tool for learning. Whereas in the past, we have only seen assessment as a means to determine measures and thus certification, there is now a realization that the potential benefits of assessing are much wider and impinge on all stages of the learning process. In this research paper, we will outline some of the major developments in educational assessment, and we reflect on the future of education within powerful learning environments, where learning, instruction, and assessment are fully integrated.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
1. Definition Of The Concept
Much has been written about assessment, measurement, and evaluation in educational practice. However, there are different meanings and it is necessary to draw as clear a distinction as possible between these three different concepts. In this context, semantic distinctions embedded in the literature are considered. What measurement, assessment, and evaluation have in common is the operation of testing. Each commonly (but not always) makes use of tests, but none of the three operations is synonymous with testing. More- over, the types of the instruments used for each of the three operations may be different (Fig. 1).
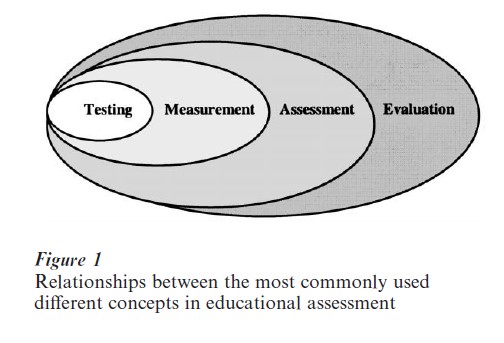
Worthen and Van Dusen (1991) define ‘measurement’ as the process of making observations about some attribute or characteristic of a person, a behavior, an event, or even an object, using clearly specified procedures to translate those observations into quantifiable or categorical form. Educational measurement is broader than educational testing. In addition to the fact that measurement frequently employs tests, it can also employ instruments, checklists, and other methods that are not considered as testing tools. However, measurement is rarely undertaken for its own sake. It is a basic research procedure that may be a component of both assessment and evaluation. Measurement itself places no value on what is measured or on the results of the measurement process.
In evaluation, quite the opposite is the case. The major attributes studied in evaluation are precisely chosen because they represent educational values. Objectives are educational values and they define what is sought to develop in learners as a result of exposing them to a set of educational experiences. Evaluation literature provides multiple perceptions of evaluation, differing in level of abstraction and in their descriptive or judgmental character. At the most general level, evaluation has been defined as a formal appraisal of the quality of educational phenomena (Popham 1988), as a determination of goal achievement, or as a measurement of merit (Scriven 1967). These definitions can be characterized as judgmental. More elaborated definitions are given, describing evaluation as ‘data-collection of education materials for providing information for decision-makers.’ These definitions have a more descriptive character. The definition of evaluation as ‘an act of collecting systematic information regarding the nature and quality of educational objects’ (Nevo 1995) combines description and judgment.
Closely related to the notion of measurement and evaluation is the term ‘assessment.’ According to Worthen and Van Dusen (1991), ‘assessment’ refers to the process of transferring test scores—or results of alternative means of appraising learning outcomes— into statements about student performance. Such learner assessment is built on the bedrock of measurement’s value neutrality, but its capstone is evaluation whenever the assessment data contain implicit judgments of the merit or worth of the performance of individuals or groups of students.
The difference between assessment and evaluation is also made clear by Scriven (1967). ‘The goal of evaluation is that of providing answers to significant evaluation questions (e.g., assessing student performance), whereas its roles refer to various ways in which those answers are used (e.g., using these achievement data to determine the adequacy of the curriculum).’ The distinction made by Nevo (1995) between ‘primary’ and ‘secondary’ functions of student evaluation is relevant here. Primary functions of assessment are those in which the student is the object of the evaluation and it is intended to provide information for the improvement of learning to certify individual accomplishment. Secondary functions of student assessment are those where the object of evaluation is not the student, but rather the teacher or the school or some other object, and the results of the evaluation are used for school accountability, or to control students or motivate them. Nevo uses the British synonym of ‘student assessment,’ for student evaluation. He also points at the difference between this British use of student assessment, and the recent distinctions between ‘student testing’ and ‘student assessment,’ referring to performance testing and authentic testing.
2. Functions And Criteria Of Student Assessment
One of the main issues in student assessment is clarity about the type of instructional decision that is supported by the assessment procedure. Nitko (1989) identifies four types of instructional decisions that are supported by tests. These are discussed below.
2.1 Placement Decisions
This is deciding in which instructional sequence or at what level in the instructional sequence a student should begin in order to avoid unnecessary repetition of what is already known, and to allow the more rapid attainment of new goals. Placement or prior knowledge state tests are given before a student begins a unit of instruction. They may focus on the prerequisite knowledge and skills for proposed learning or on the outcome knowledge and skills to determine whether students have already attained the desired outcome of the instruction. Thus, instructors use prior knowledge state tests to place students in instructional modes by (a) determining the degree to which prerequisite entry behaviors or skills are present or absent, (b) determining entering mastery of course objectives, and also for (c) matching students to alternative instructional modes, based on student characteristics.
2.2 Monitoring Decisions
This is deciding (a) whether students are learning appropriately, and (b) whether the assigned learning activity is working effectively, or a different activity should be assigned. So-called progress assessments or assessments of growth are the instruments for the assessment of a student’s progress toward the final learning objectives. Progress assessments provide feedback to students on how their learning is progressing and can lead to the (formative) decision that there is a need to remediate or relearn a certain instructional unit. Progress assessments, taken during instruction, are used by instructors to (a) choose or modify subsequent learning activities, (b) prescribe remediation of group or individual deficiencies, and (c) provide on-going feedback to the student for the purpose of directing advanced or remedial study.
2.3 Attainment Decisions
This involves deciding, at the end of a particular instructional segment, whether a student has attained the desired instructional goals. Final tests are used for certifying student learning and evaluating teacher effectiveness.
2.4 Diagnostic Decisions
This is deciding which learning outcomes a student has not acquired and the probable cause(s) of the failure to acquire them, in order to remediate or correct incomplete or erroneous prior learning. Diagnostic assessments are designed to provide specific information on individual learning deficiencies and misunderstandings. When prior knowledge state assessments, progress assessments, and final assessments are designed and interpreted properly they can also provide information of a diagnostic nature since students and teachers can use this information in order to regulate learning processes.
Another issue in student assessment relates to criteria setting. A distinction can be made between norm-referenced and criterion-referenced tests. Norm-referenced tests determine the level of students relative to some groups (e.g., class, school, age-group), whereas criterion-referenced tests determine the level of a student relative to some predetermined criterion set by the curriculum, the teacher, or some authority. Nevo (1995) mentions that while norm-referenced tests are suitable for selection procedures, criterion-referenced tests are the tests schools predominantly need.
3. Innovations In Assessment
3.1 Consequences Of The Developments In Society
Economic and technological change, bringing with it significant changes in the requirements of the labor market, poses increasing demands on education and training. For many years, the main goal of education has been to make students knowledgeable within a certain domain. Building a basic knowledge store was the core issue (Dochy and McDowell 1997). Students taking up positions in modern organizations in the twenty-first century need to be able to analyze information, to improve their problem-solving skills and communication, and to reflect on their own role in the learning process. People increasingly have to be able to acquire knowledge independently and use this body of organized knowledge in order to solve unforeseen problems. As a consequence, education should contribute to the education of students as lifelong learners.
3.2 Paradigm Change: From Testing Towards Assessment
Many authors (Dochy and McDowell 1997) have pointed out the importance of instruction to promote students’ abilities as thinkers, problem-solvers, and inquirers. Underlying this goal is the view that meaningful understanding is based on the active construction of knowledge and often involves shared learning. It is argued that a new form of education requires reconsideration about assessment (Dochy et al. 1999). Changing towards new forms of learning, with a status quo for evaluation, undermines the value of innovation. Students do not invest in learning that will not be honored. Assessment is the most determining factor in education for the learning behavior of students. Traditional didactic instruction and traditional assessment of achievement are not suited to modern educational demands. Such tests were generally designed to be administered following instruction, rather than to be integrated with learning. As a consequence, due to their static and product-oriented nature, these tests not only lack diagnostic power but also fail to provide relevant information to assist in adapting instruction appropriately to the needs of the learner. Furthermore, standard test theory characterizes performance in terms of the difficulty level of response choice items and primarily focuses on measuring the amount of declarative knowledge that students have acquired.
This view of performance is at odds with current theories of cognition. Achievement assessment must be an integral part of instruction, in that it should reflect, shape, and improve student learning. Assessment procedures should not only serve as a tool for crediting students with recognized certificates, but should also be used to monitor progress and, if needed, to direct students to remedial learning activities. The view that the evaluation of students’ achievements is something which happens at the end of the process of learning is no longer widespread; assessment is now represented as a tool for learning (Dochy and McDowell 1997).
Birenbaum and Dochy (1996) describe this movement as a paradigm change between two cultures in the measurement of achievement and relate this to developments in the learning society. In the traditional so-called testing culture, instruction and testing are considered to be separate activities. Instruction is the responsibility of the teacher, whereas testing is the responsibility of the psychometric expert, who can use elaborate procedures for test development and sophisticated psychometric models for the analysis of test responses. The work of such experts within testing agencies was stimulated by the demand for objectivity and fairness in testing and a high level of standardization where important decisions were to be based on test scores. Stemming from such demands, common tools for assessment in education were easy-to-score items such as multiple-choice items and true false items. The testing culture fits well with the traditional approach to education where teaching is seen as an act of depositing the content which students receive, memorize, and reproduce. The most efficient way of testing this process is by standardized tests delivered by external testing agencies.
The changing learning society has generated the so-called assessment culture as an alternative to the testing culture. The assessment culture strongly emphasizes the integration of instruction and assessment. Students play far more active roles in the evaluation of their achievement. The construction of tasks, the development of criteria for the evaluation of performance, and the scoring of the performance may be shared or negotiated among teachers and students. The assessment takes all kinds of forms such as observations, text and curriculum-embedded questions and tests, interviews, performance assessments, writing samples, exhibitions, portfolio assessment, and project and product assessments. Several labels have been used to describe subsets of these alternatives, with the most common being ‘direct assessment,’ ‘authentic assessment,’ ‘performance assessment,’ and ‘alternative assessment.’
3.3 New Methods Of Assessment
Investigations of new approaches (e.g., Birenbaum and Dochy 1996) illustrate the development of more ‘in context’ and ‘authentic’ assessment. Nisbet (1993) defines the term authentic assessment as ‘methods of assessment which influence teaching and learning positively in ways which contribute to realizing educational objectives, requiring realistic (or ‘‘authentic’’) tasks to be performed and focusing on relevant content and skills, essentially similar to the tasks involved in the regular learning processes in the classroom’ (p. 35).
Assessment of such ‘authentic’ tasks is highly individual and contextualised. The student gets feedback about the way he or she solved the task and about the quality of the result. Evaluation is given on the basis of different ‘performance tasks,’ performed and (reviewed) assessed at different times. The evaluation criteria have to be known in advance. When students know the criteria and know how to reach them, they will be more motivated and achieve better results. This form of evaluation gives a more complete and realistic picture of a student’s ability (achievement). It not only evaluates the product, but also evaluates the process of learning. Students get feedback about their incorrect thinking strategies. Within the new forms of ‘new assessment,’ much attention is paid to authentic problem-solving, case-based exams, portfolios, and the use of peer and self-assessment. (Birenbaum and Dochy 1996).
In traditional education, the question ‘who takes of the exam and who defines the criteria?’ is seldom asked. Most of the time, it is the teacher. New forms of education do pose this question. Student themselves, other students, or the teacher and students together, are responsible for assessment. The type of student self-assessment referred to most frequently in the literature is a process which involves teacher-set criteria and where students themselves carry out the assessment and marking. Another form of student self-assessment is the case where a student assesses herself or himself, on the basis of criteria which she or he has selected, the assessment being either for the student’s personal guidance or for communication to the teacher or others. According to Hall (1995) there are two critical factors for genuine self-assessment: the student not only carries out the assessment, but also selects the criteria on which the assessment is based. Similarly, peer assessment can indicate that fellow students both select the criteria and carry out the assessment. Any situation where the tutor and students share in the selection of criteria and/or the carrying-out of the assessment is more accurately termed co-assessment (Hall 1995). However, it is still frequently the case that teachers control the assessment process, sometimes assisted by professional bodies or assessment experts, whereas students’ assessments and criteria are taken seriously but considered to be additional to the assessment undertaken by the teacher or professor rather than replacing it. Implementing forms of self-, peer, and co-assessment may de- crease the time-investment professors would other- wise need to make in more frequent assessment (Dochy et al. 1999). In addition to that advantage, using these assessment forms assists the development of certain skills for the students, e.g., communication skills, self-evaluation skills, observation skills, and self-criticism.
4. Assessing New Assessment Forms
Judgments regarding the cognitive significance of an assessment begin with analyses of the cognitive requirements of tasks as well as the ways in which students try to solve them. Two criteria by which educational and psychological assessment measures are commonly evaluated are validity and reliability. One can say that based on these criteria the results above are not yet consistent and, depending upon the assessment form, there is a larger or smaller basis to state that the evaluation is acceptable.
It is however important to note that Birenbaum (1996) mentions that the meaning of validity and reliability has recently expanded. Dissatisfaction with the available criteria, which were originally developed to evaluate indirect measures of performance, is attributed to their insensitivity to the characteristics of a direct assessment of performance. The most important element of new assessment models is the reflection of the competencies required in real-life practice. The goal is to ensure that the success criteria of education or training processes are the same as those used in the practice setting. Hence, as notions of fitness of purpose change, and as assessment of more qualitative areas are developed, the concepts of validity and reliability encompassed within the instruments of assessment must also change accordingly. This means that we should widen our view and search for other and more appropriate criteria. It should not be surprising that a new learning society and consequently a new instructional approach and a new assessment culture cannot be evaluated solely on the basis of the pre-era criteria.
5. Validity-Related Issues
Although performance assessment appears to be a valid form of assessment, in that it resembles meaningful learning tasks, this measure may be no more valid than scores derived from response choice items. Evidence is needed to ensure that assessment requires the high-level thought and reasoning processes that they were intended to evoke.
The authors of the 1985 Standards define test validity as ‘a unitary concept, requiring multiple lines of evidence, to support the appropriateness, meaningfulness, and usefulness of the specific inferences made from test scores’ (AERA, APA, NCME 1985, p. 9). All validity research should be guided by the principles of scientific inquiry reflected in construct validity.
Within the construct validity framework, almost any information gathered in the process of developing and using an assessment is relevant when it is evaluated against the theoretical rationale underlying the proposed interpretation and inferences made from test scores (Moss 1992). Thus, validation embraces all the experimental statistical and philosophical means by which hypotheses are evaluated (Messick 1994). Validity conclusions, then, are best presented in the form of an evaluative argument (Cronbach 1989) that integrates evidence to justify the proposed interpretation against plausible alternative interpretations.
Kane’s argument-based approach is in line with Cronbach’s view on validity. According to Kane (1992), to validate a test-score interpretation is to support the plausibility of the corresponding interpretative argument with appropriate evidence (a) for the inferences and assumptions made in the proposed interpretative argument, and (b) for refuting potential counter arguments. The core issue is not that we must collect data to underpin validity, but that we should formulate transparent, coherent, and plausible arguments to underpin validity.
Authors like Kane and Cronbach use validity principles from interpretative research traditions, instead of psychometric traditions, to assist in evaluating less standardized assessment practices.
Other criteria suggested for measuring validity of new assessment forms are the transparency of the assessment procedure, the impact of assessment on education, directness, effectiveness, fairness, completeness of the domain description, practical value, and meaningfulness of the tasks for candidates, and authenticity of the tasks. According to Messick (1994), these validation criteria are, in a more sophisticated form, already part of the unifying concept of validity, which he expressed in 1989. He asserted that validity is an evaluative summary of both evidence for and the actual as well as potential consequences of score interpretation and use. The more traditional conception of validity as ‘evidence for score interpretation and use’ fails to take into account both evidence of the value implications of score interpretation and the social consequences of score use.
Messick’s unifying concept of validity encompasses six distinguishable parts—content, substantive, structural, external, generalizability, and consequential aspects of construct validity—that conjointly function as general criteria for all educational and psychological assessment. The content aspect of validity means that the range and type of tasks used in assessment must be an appropriate reflection (content relevance, representativeness) of the construct domain. Increasing achievement levels in assessment tasks should reflect increases in expertise of the construct-domain. The substantive aspect emphasizes the consistency between the processes required for solving the tasks in assessment, and the processes used by domain-experts in solving tasks (problems). Further, the internal structure of assessment— reflected in the criteria used in assessment tasks, the interrelations between these criteria, and the relative weight placed on scoring these criteria—should be consistent with the internal structure of the construct-domain. If the content aspect (relevance, representativeness of content, and performance standards) and the substantial aspect of validity is guaranteed, score interpretation based on one assessment task should be generalizable to other tasks assessing the same construct. The external aspect of validity refers to the extent that the assessment scores’ relationship with other measures and non-assessment behaviors reflect the expected high, low, and interactive relations. The consequential aspect of validity includes evidence and rationales for evaluating the intended and unintended consequences of score interpretation and use (Messick 1994).
In line with Messick’s conceptualization of consequential validity, Frederiksen and Collins (1989) proposed that assessment has ‘systematic validity’ if it encourages behaviors on the part of teachers and students that promote the learning of valuable skills and knowledge, and allows for issues of transparency and openness, that is to access the criteria for evaluating performance. Encouraging deep approaches to learning is one aspect which can be explored in considering consequences. Another is the impact which assessment has on teaching. Dochy and McDowell (1997) argue that assessing high-order skills by authentic assessment will lead to the teaching of such high-order knowledge and skills.
With today’s emphasis on high-stakes assessment, two threats to test validity are worth mentioning: construct under-representation and construct-irrelevance variation. In the case of ‘construct-irrelevance variation,’ the assessment is too broad, containing systematic variance that is irrelevant to the construct being measured. The threat of ‘construct underrepresentation’ means that the assessment is too narrow and fails to include important dimensions of the construct being measured (Dochy and Moerkerke 1997).
5.1 Special Points Of Attention For New Assessment Forms
The above implies in our view that other criteria suggested for measuring validity of new assessment forms will need to be taken into account, i.e., the transparency of the assessment procedure, the impact of assessment on education, directness, effectiveness, fairness, completeness of the domain description, practical value and meaningfulness of the tasks for candidates, and authenticity of the tasks.
Authentic assessment tasks are more sensitive to construct under-representation and construct-irrelevance variation, because they are often loosely structured, so that it is not always clear to which construct-domain inferences are drawn. Birenbaum (1996) argues that it is important to specify accurately the domain and to design the assessment rubrics so they clearly cover the construct-domain. Messick (1994) advises the adoption of a construct-driven approach to the selection of relevant tasks and the development of scoring criteria and rubrics, because it makes salient the issue of construct underrepresentation and construct-irrelevance variation.
Another difficulty with authentic tasks, with regards to validity, concerns rating authentic problems. The literature reveals that there is much variability between raters in scoring the quality of a solution. Construct under-representation in rating is manifested as an omission of assessment criteria or ideosyncratic weighting of criteria such that some aspects of performance do not receive sufficient attention. Construct-irrelevance variation can be introduced by the rater’s application of extraneous, irrelevant, or idiosyncratic criteria. Suggestions for dealing with these problems in the literature include constructing guidelines, using multiple raters, and selecting and training raters. However, even within communities of problem-solvers, there is no common sense about the solution to an ill-defined problem. Since universally accepted (objective) criteria do not exist, argumentation can be an important means to judge the quality of solutions for an ill-structured problem. Therefore, product and process quality criteria need to be identified, defined, and communicated to candidates and raters (Dochy and Moerkerke 1997).
6. Reliability-Related Issues
Reliability in classical tests is concerned with the degree in which the same results would be obtained on a different occasion, in a different context, or by a different assessor. Inter and intra-rater agreement is used to monitor the technical soundness of performance assessment rating. However, when these conventional criteria are employed for new assessments (for example using authentic tasks), results tend to compare unfavorably to traditional assessment, because of a lack of standardization of these tasks.
The unique nature of new forms of assessment has affected the traditional conception of reliability, resulting in the expansion of its scope and a change in weights attached to its various components (Birenbaum 1996). In new assessment forms, it is not about achieving a normally distributed set of results. The most important question is to what extent the decision ‘whether or not individuals are competent’ is dependable. Differences between ratings sometimes represent more accurate and meaningful measurement than would absolute agreement. Measures of inter-rater reliability in authentic assessment, then, do not necessarily indicate whether raters are making sound judgment and do not provide bases for improving technical quality. Suen et al. (in press) argue that the focus on objectivity among raters as a desirable characteristic of an assessment procedure leads to a loss of relevant information. In high-stake decisions, procedures which include ways of weighing high-quality information from multiple perspectives may lead to a better decision than those in which information from a single perspective is taken into account. Measuring the reliability of new forms of assessment stresses the need for more evidence in a doubtful case, rather than to rely on making inferences from a fixed and predetermined set of data.
In line with these visions on reliability is Moss’ idea (1992) about reliability. She asserts that a hermeneutic approach of ‘integrative interpretations based on all relevant evidence’ is more appropriate for new assessment because it includes the value and contextualized knowledge of the reader, than the psychometric approach that limits human judgment ‘to single performances,’ results of which are then aggregated and compared with performance standards.
7. Conclusion: Future Research And Developments
The assessment culture leads to a change of our instructional system from a system that transfers knowledge into students’ heads to one that tries to develop students who are capable of learning how to learn. The current societal and technological context requires education to make such a change. The explicit objective is to interweave assessment and instruction in order to improve education. Although promising results have been reported, the first attempts to introduce new assessment procedures have not been entirely positive. Madaus and Kellaghan (1993) reported problems with the organization, time, and costs of assessment programs. A number of lessons can be learned from the early applications of new assessment programs.
Firstly, one should not ‘throw the baby out with the bath water.’ Objective tests are very useful for certain purposes, such as high-stake summative assessment of an individual’s achievement, although they should not dominate an assessment program. Increasingly, measurement specialists recommend so-called balanced or pluralistic assessment programs, where multiple assessment formats are used (Birenbaum 1996). There are several motives for these pluralistic assessment programs: a single assessment format cannot serve several different purposes and decision-makers; and each assessment format has it own method variance, which interacts with people.
There is a need to establish a system of assessing the quality of new assessment and implement quality control. Various authors have recently proposed ways to extend the criteria, techniques, and methods used in traditional psychometrics (Kane 1992). Others, like Messick (1994), oppose the idea that there should be specific criteria, and claim that the concept of construct validity applies to all educational and psychological measurements, including performance assessment.
Further, there is a need for well-designed and well-evaluated heuristics, which would help teachers to implement and design high-quality new assessment procedures. Teachers need clear criteria for the development and use of assessment procedures, and easy-to-use techniques for quality improvement and quality control.
Surely, there is no one ideal assessment format for all cases. All assessment formats can have negative effects on teaching and learning. From this perspective, Frederiksen’s criticism (1984) can be more broadly interpreted than simply as an exposure of the negative effects of multiple-choice items; it also shows that some aspects of any assessment may have negative as well as positive educational consequences. However, new assessment forms with their potential to develop and assess learning achievements which are congruent with contemporary views of the nature of knowledge and the needs of society for educated persons, is an avenue which we must continue to explore.
Bibliography:
- American Educational Research Association, American Psychological Association, National Council on Measurement in Education 1985 Standards for Educational and Psychological Testing. Washington, DC
- Birenbaum M 1996 Assessment 2000: Towards a pluralistic approach to assessment. In: Birenbaum M, Dochy F R J C (eds.) Alternatives in Assessment of Achievement, Learning Processes and Prior Knowledge. Kluwer Academic, Boston
- Birenbaum M, Dochy F R J C (eds.) 1996 Alternatives in Assessment of Achievement, Learning Processes and Prior Knowledge. Kluwer Academic, Boston
- Cronbach L J 1989 Construct validation after thirty years. In: Linn R L (ed.) Intelligence: Measurement, Theory and Public Policy. Invington, New York, pp. 147–71
- Dochy F, McDowell L 1997 Assessment as a tool for learning. Studies in Educational Evaluation 23(4): 279–98
- Dochy F, Segers M, Sluijsmans D 1999 The use of self-, peer and co-assessment in higher education: A review. Studies in Higher Education 24(3): 331–50
- Dochy F, Moerkerke G 1997 The present, the past and the future of achievement testing and performance assessment. International Journal of Educational Research 27(5): 415–32
- Frederiksen N 1984 The real test bias influences of testing on teaching and learning. American Psychologist 39(3): 193–202
- Frederiksen J R, Collins A 1989 A system approach to educational testing. Educational Researcher 18(9): 27–32
- Hall K 1995 Co-assessment: Participation of Students with Staff in the Assessment Process. A report of Work in Progress.
- Paper given at the 2nd European Electronic Conference on Assessment and Evaluation, EARLI-AE list European Academic and Research Network (EARN) (http://listserv./surfnet.nl/archives/earli-ae.html)
- Kane M 1992 An argument-based approach to validity. Psychological Bulletin 112: 527–35
- Madaus G F, Kellaghan K 1993 British experience with authentic testing. Phi Delta Kappan 74: 458–569
- Messick S 1994 The interplay of evidence and consequences in the validation performance assessments. Educational Researcher 23(2): 13–22
- Moss P A 1992 Shifting conceptions of validity in educational measurement: Implications for performance assessment. Review of Educational Research 62(3): 229–58
- Nevo D 1995 School-Based Evaluation. A Dialogue for School Improvement. Pergamon, London
- Nisbet J 1993 Introduction. In: OECD Curriculum Reform: Assessment in Question. Organization for Economic Cooperation and Development, Paris, pp. 25–38
- Nitko A J 1989 Designing Tests that are Integrated with Instruction Educational Measurement. Macmillan, New York
- Popham W J 1988 Educational Evaluation, 2nd. edn. Prentice Hall, Englewood Cliffs, NJ
- Scriven M J 1967 The methodology of evaluation. In: Tyler R W, Gagne R M, Scriven M (eds.) Perspective of Curriculum Evaluation. AERA, Monograph Series Evaluation, No. 1. Rand McNally, Chicago
- Suen H K, Logan C R, Neisworth J T, Bagnato S (in press) Parent-professional congruence: Is it necessary? Journal of Early Intervention
- Worthen B R, Van Dusen L M 1991 Nature of evaluation. In: Husen T, Postlethwaite T N (eds.) International Encyclopedia of Education, 2nd edn. Pergamon Press, Oxford New York, pp. 4345–56
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality