
Sample Knowledge Representation Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our custom research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
1. Knowledge Representation: Ideal And Reality
The fundamental conjecture of knowledge-based artificial intelligence (AI), known as the physical symbol system hypothesis (Newell and Simon 1976), posits that the cognitive processes of any broadly intelligent agent, natural or artificial, can be largely characterized in terms of a knowledge base: a transparent, symbolic representation of the agent’s beliefs, intentions, and value judgments, together with reasoning processes that modify the knowledge base in rational ways, and perceptual and motor processes that connect the knowledge base to the outside world. The field of knowledge representation (KR) is the study of how such a knowledge base can be constructed.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
The physical symbol system hypothesis requires that a knowledge base be symbolic, transparent, and modular. That is, the atomic elements of a knowledge base are symbols, each of which has an associated meaning. It is possible to identify small substructures of the knowledge base that correspond to specific beliefs, judgments, and intentions. For example, the belief that Holbein painted a portrait of Thomas More in oil might be represented in a predicate calculus formula like
3X oil painting(X )
^ painter(holbein, X ) ^ depicts (X, thomas more)
or in a fragment of a semantic net, such as that shown in Fig. 1. Here the symbols are ‘ 3 ’ (meaning ‘there exists’), ‘X’ (a variable), ‘ ^’ (meaning ‘and’),
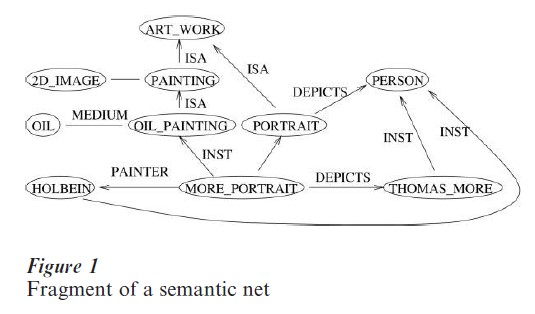
‘oil painting,’ ‘painter,’ ‘holbein,’ and ‘thomas more’; the parentheses and the comma indicate the syntactic structure. (The fact that some of these symbols are English words is purely for the convenience of the human reader; the formula could just as well be notated
3X g001(X ) ^ g002(g003, X ), ^ g004(X, g005)
if it is accepted that ‘g001’ denotes the property of being an oil painting, that ‘g002’ denotes the relation of a person painting a painting, and so on.) It should be noted that not every belief of the agent can be explicitly expressed in the knowledge base. For example, a person who knows that Holbein painted a portrait of Thomas More will also know that Holbein knew how to paint; that Thomas More was painted; that Thomas More was born before Holbein’s death; and so on. Clearly it is not plausible that each of these ancillary beliefs is separately represented in the knowledge base. Rather, they are represented implicitly, in the sense that they can be derived as needed.
Of course, the construction of the broadly intelligent artificial agent described above is today just a pipe dream for the distant future. Any work aimed at achieving a working system any time soon must be much more modest in its ambitions. Within the context of such limited objectives, the problem of knowledge representation is one of finding data structures that express the knowledge needed for the particular application.
Thus broadly construed, the problem of knowledge representation would appear to be equivalent to computer programming generally. Any program, after all, uses some data structures, and incorporates some kind of knowledge. What distinguishes a data structure as interesting from the point of view of knowledge representation is that its design reflects some of the features of the broadly intelligent knowledge-based agent described above. As artificial intelligence is the study of tasks that are easy for people (or animals) to carry out but difficult to implement in a computer, so knowledge representation is the design of data structures that express knowledge that people deal with easily, but are hard to encode in a data structure.
The design of a knowledge representation can be very roughly divided into four parts
(a) Architectural issues involve defining general-purpose schemas for knowledge representation and procedures for reasoning with these schemas. Most of the research in knowledge representation has been addressed to architectural issues, as they are largely independent of the particular domain and application (Reichgelt 1991).
(b) Content issues address such questions as what is the knowledge to be represented, how should the domain be conceptualized, what are the key concepts in the domain, and what kinds of partial knowledge must be dealt with. Since content issues are always domain-dependent, and often task-dependent, they are much less susceptible to general treatment. However, there are some domains—such as time, space, epistemic states, plans, and so on—that are so ubiquitous in intelligent reasoning, and so difficult, that it is worthwhile studying them extensively in the abstract, without reference to a particular application (Davis 1990).
(c) The implementation of the knowledge representation as a data structure and of the reasoning mechanisms as procedures is usually carried out in a uniform way for a given architecture; alternatively, it may be highly specialized to a particular class of problems.
(d) Finally, any knowledge representation requires an interface, either to user queries or to application programs such as robot control. As interface issues are entirely task-dependent, there is very little that can be said about them in general.
This research paper will begin (Sect. 2) by discussing some features that are desirable in a knowledge representation. It will then (Sect. 3) survey some of the important architectures in knowledge representation. Section 4 will discuss the issue of content, illustrating it with a brief discussion of representations of time. Finally, Sect. 5 will discuss two alternative approaches to knowledge representation: neural networks and digital libraries.
2. Desiderata
The design of a knowledge representation, whether for a broadly intelligent agent or for some limited application, will generally aim toward the following objectives:
(a) Scope. A comprehensive knowledge representation scheme should ideally be extensible to cover any possible object of human thought, and any humanly possible belief system.
Of course, the designer of a KR theory need not explicitly state how the theory can express knowledge about the Parthians, the blue whale, and the Crab Nebula. But a convincing case should be made that beliefs about such things can be expressed in the representation, if necessary. A complete KR theory should explain in detail how to represent fundamental and universal subjects of human thought, such as time, space, simple physical categories, the human mind, and human relations (Davis 1990, Hayes 1979, McCarthy 1968).
A knowledge representation for a limited application should cover all relevant aspects of relevant domains.
(b) Expressivity. The KR scheme should be able to express the various forms of partial and incomplete knowledge that naturally arise for the desired application.
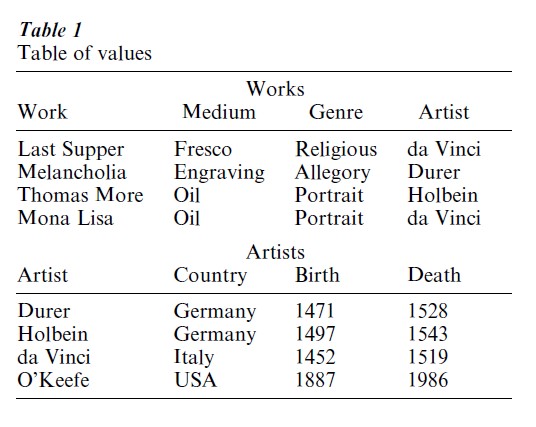
For example, a standard form of representation is a collection of tables of values, known in computer science as a ‘relational database.’ For example, Table 1 displays a table of paintings and a table of artists. However, even within its narrow scope, such a representation may not achieve reasonable expressivity, because there is no way to express plausible partial states of knowledge such as:
Turner lived in the nineteenth century.
Rembrandt painted many oil paintings.
Vermeer did not make any sculptures.
The Sistine Chapel and the sculpture of David were created by the same artist.
If such partial states of knowledge are important in the application, then a more expressive language must be found.
Another example: it is tempting to represent spatial information using a representation that corresponds to a single picture of the scene. This is often called diagrammatic representation, (Glasgow et al. 1995), though this term is used in many different conflicting ways. Such representations are easily understood and support efficient inference. However, they cannot be used to represent partial information. For instance, an agent might know that A is a mile from B and that A is a mile from C without knowing the distance from A to C. However, it is not possible for a single picture to display the distances from A to B and from A to C without committing itself to some particular distance between B and C. Therefore, unless all the program’s geographic knowledge can always be expressed in a precise map, this representation will not be sufficiently expressive.
(c) Precision. The meaning of a knowledge representation should be unambiguous, and, as far as the nature of the subject matter allows, well defined.
(d) Support for reasoning. It must be possible to model the processes of reasoning involved in cognition in terms of well-defined operations over the knowledge representation. For example, as mentioned above, an agent who knows that Holbein painted a portrait of More should be able to conclude that Holbein knew how to paint, that More was born before Holbein died, and so on.
(e) Efficiency of reasoning. The implementation of reasoning operations over the knowledge representation must also be efficient. Conclusions must be derived in the time that they are needed, often a matter of seconds or fractions of a second.
(f ) Learnability. A broadly intelligent agent must be able to learn over time from experience and from instruction. Therefore, modules must exist that can learn from experience and can generalize individual cases to general rules. The knowledge representation should support such learning modules (Mitchell 1997). (g) Support for uncertainty. If an agent can only use knowledge that it knows with 100 percent certainty, it will be paralyzed. Rather, an agent must be able to compare relative likelihoods, and to take action on the basis of the best information it can get. A knowledge representation should therefore support the expression of relative degrees of certainty, and reasoning modules should be able to take these degrees of certainty into account (Pearl 1988).
(h) Robustness. The information in a knowledge base will sometimes be simply wrong or corrupted. The effects of a single error in the knowledge base should be limited in scope.
(i) Ease of construction. In the best case, it may be possible to build a large knowledge base automatically or semiautomatically from existing data sets, such as conventional databases, online libraries, or collections of digitized images. If the knowledge base must be constructed by hand, then a notation that is simple and natural enough to be used by programmers with little technical expertise is clearly preferable to one that can be used only by an expert in knowledge representation. Other things being equal, the less human labor, especially expert labor, that is required to build a knowledge base, the better.
(j) Interface. A knowledge representation should support a suitable interface to the user or the ap plication.
Expressivity and precision are features, both of the architecture and of the content of a knowledge base Scope is chiefly a feature of content, though expressivity and therefore architecture do bear on scope; some domains inherently require a very expressive language. Robustness, ease of construction, and support for reasoning, for learning, and for uncertainty are primarily features of the architecture. Efficiency of reasoning depends on the implementation, which, in turn, reflects the architecture, and on the class of problems being solved.
3. Architectures
A number of KR architectures are briefly surveyed below. The particular architectures included here have been included, in part because of their importance in KR research and applications, and in part to illustrate the range of possible approaches to KR.
3.1 Logic-Based Systems
A logic-based system represents knowledge as a set of sentences in a logical language. Reasoning is implemented as inference procedures that carry out deductive proofs authorized within the logical theory (Geneserth and Nilsson 1987).
A logical theory characteristically consists of three parts
(a) A syntax, which specifies what kinds of symbols may be used, and how they can be combined to form well-formed sentences.
(b) A semantics, which specifies what kinds of meanings may be attached to symbols, and how these meanings combine to form the meaning of sentences.
(c) A proof theory, which specifies what manipulations over sentences constitute deductive proof.
For example, first-order logic (also known as the predicate calculus) is the most widely used logic in knowledge representation. In first-order logic, there are seven kinds of symbols.
(a) Constant symbols represent individual entities. For example ‘holbein’ may represent Hans Holbein. The symbol ‘ad1517’ may represent the year 1517.
(b) Predicate symbols represent properties of relation. For example, ‘painter’ may represent the two- place relation of a person painting a painting. The predicate ‘precedes’ may represent the two-place relation of one event preceding another.
(c) Function symbols represent mappings. For example, ‘birth of’ may represent the one-place mapping of a person to the event of his her birth. The function ‘creation of’ may represent the one-place mapping of an artifact to the event of its creation.
(d) The Boolean operators are ‘ ’ meaning ‘and’; ‘˅’ meaning ‘or’; ‘ -’ meaning ‘not’; and ‘→’ meaning ‘implies.’
(e) Variables, such as X, Y, Z, represent indeterminate objects.
(f ) The quantifiers are meaning ‘for all,’ and ‘3’ meaning ‘there exists.’
(g) Finally, the grouping symbols, which serve to specify the structure of a sentence, are the comma and the open and close parentheses.
Constant, predicate, and function symbols are known as non-logical symbols; they may be chosen, and their meanings may be assigned, by the designer of the knowledge base. Boolean operators, quantifiers, variables, and grouping symbols are known as logical symbols; their meanings are fixed by the logic. The distinction is roughly analogous to the distinction between open and closed categories in linguistics, or to the distinction between identifiers and reserved words in programming languages.
The syntactic rules for first-order logic establish that these symbols can be put together to form sentences such as
(1) AX,Y painter (X, Y ) → precedes(birth of(X ), creation-of(Y ))
The semantic rules establish that, given the above assignments of meanings to the symbols ‘painter,’ ‘precedes,’ ‘birth of,’ and ‘creation of,’ the meaning of this sentence is that the birth of a painter precedes the creation of any of his works. The proof theory establishes that, given formula (1) above and the fact, ‘painter(holbein, more portrait),’ it is possible to infer
(2) precedes (birth of(holbein),
creation of(more portrait)),
i.e., that Holbein was born before the portrait of More was painted. Details of these rules may be found in any logic textbook (e.g., Mates 1972)
First-order logic is probably the most common foundation for a logic-based knowledge representation, but many other logics have also been applied. Some of these extend first-order logic to achieve greater expressivity. Modal logics define a variety of operators on sentences. For instance, given a base sentence such as ‘Bill Clinton is President,’ a temporal operator might generate the sentence ‘Bill Clinton has been President,’ an epistemic operator might generate the sentence, ‘Al Gore knows that Bill Clinton is President’; a deontic operator might generate the sentence ‘Bill Clinton ought to be President.’ These operators can be combined, as in the sentence ‘Al Gore should have known that Bill Clinton would be President’ (Turner 1984). Fuzzy logic allows the use of vague terms that are hold to greater and lesser degree; for example, ‘George Washington was a tall person’ is reasonably true, ‘Abe Lincoln was a tall person’ is quite true, ‘Wilt Chamberlain was a tall person’ is absolutely true (Zadeh 1987). Probabilistic logics allow sentences to be tagged with a measure of certainty (Bacchus 1990).
Other knowledge representations have used logics less expressive than the predicate calculus in order to achieve greater efficiency in a general purpose inference engine. For instance, in the propositional calculus, the only logical symbols are Boolean operators, and a separate symbol must be used for each atomic proposition. Thus there is one symbol for the proposition, ‘Leonardo painted the Last Supper,’ another for the (false) proposition, ‘Rodin painted the Last Supper,’ and so on. General rules like formula (1) above can then only be stated every instance for every pair X and Y. Despite this proliferation of symbols and formulas, however, as long as the underlying domain is not too large, it is often more effective to use the propositional calculus than the predicate calculus because the best methods of inference known are much faster for the propositional calculus than the predicate calculus (Selman et al. 1992).
The chief virtues of logic-based representation are precision and modularity. The meaning of a formula in a logic-based representation is completely and exactly fixed by the logic and the meaning of the symbols included. It is independent of any other formula in the knowledge base, and any other aspect of the knowledge base. Another important virtue is that procedures for deductive inference over logic-based knowledge bases are known. These procedures characteristically generate only valid inferences and all valid inferences (in the technical jargon, they are sound and complete) and, in practice, they can often be implemented so as to find useful answers quickly.
Their chief failing is difficulty of use. Building a knowledge base in a logic-based representation inevitably requires a large investment of expert labor. Moreover, even experts in knowledge representation find the encoding of complex domains in logical languages surprisingly difficult and error-prone. Logic-based languages also tend to be fragile. In principle, any inconsistency in any part of a logical theory invalidates the entire theory; and in practice small and subtle inconsistencies in foundational parts of a logic-based knowledge base can lead to bizarre and unpredictable results.
3.2 Semantic Networks
A semantic network consists of labelled nodes connected by labelled arcs (Fig. 1). A node may represent an individual such as Hans Holbein or a category, such as oil paintings. An arc represents a two-place relation between nodes, such as the relation ‘painter’ between a work of art and a person.
The most important arcs in any semantic network are those labelled ‘INST’ and ‘ISA.’ An ‘INST’ link goes from an individual I to a category C and asserts that I is an instance of C. An ISA link goes from category C to category D and asserts that C is a subset of D. Implicitly, therefore, if there is a chain of ISA links from C to D, then it can be inferred that C is a subset of D. If there is an INST link from I to C and then a chain of ISA links from C to D, then it can be inferred that I is an instance of D. For instance, in Fig. 1, it can be inferred that oil paintings are works of art, and that the portrait of Thomas More is a work of art.
The central reasoning mechanism in a semantic network is inheritance: a node inherits all the properties of the nodes that contain it. For instance, in Fig. 1, the node ‘MORE PORTRAIT’ inherits the ‘MEDIUM’ arc to ‘OIL’ from ‘OIL PAINTING’; it inherits the ‘FORM’ arc to ‘2D-IMAGE’ from ‘PAINTING’; it inherits the ‘DEPICTS’ arc to ‘PER- SON’ from ‘PORTRAIT.’ In other words, the system can infer that the portrait of More is a two-dimensional image from the facts that it is a painting, and that all paintings are two-dimensional images.
The semantic network architecture, as described above, has a number of advantages. It is easy and natural to use; its meaning can be defined precisely; and the inheritance mechanism is easy to implement and efficient. The chief disadvantage is that it is not very expressive. Also, the apparent simplicity of the representation can end up working against precision; unless the user adheres rigorously to the specifications of use, it is very easy to construct a semantic network that looks plausible, but that uses the same notation with two completely different meanings (Woods 1975).
It is possible, and indeed common, to increase the expressivity of the very minimal architecture described above by adding additional features, such as ‘metaarcs’ that connect two arcs and describe the logical relations between them (Sowa 2000). However, the more such features are added, the less simple and natural the representation becomes.
3.3 Frame-Based Systems
A frame represents either an individual or a category, and associates with its subject a collection of pairs of a slot with a corresponding filler. A slot is just the name of a feature of an individual. A filler of a slot for an individual is just the value of that feature; for example, the ‘color’ slot for ‘statue of liberty’ has filler ‘green.’ The filler of a slot for a category contains information of some kind about the fillers of the same slot for individual instances of the category. This can take many different forms; it can be a particular value, a range of values, a constraint on values, or a function that computes the value. A tag, or structure of tags, indicates which type of information is involved. For instance, in frame ‘oil-painting’ in Table 2, the value of the ‘date’ slot is a constraint asserting that the date of a painting must take place within the painter’s lifetime. The ‘@’ sign used here is a special-purpose variable meaning the particular instance of the frame. The value of the ‘painter’ slot must either be a particular human or a particular workshop. The value of the ‘owner’ slot is either a particular person or institution, or the values ‘lost’ or ‘destroyed.’ (Note: the specific syntax used here is invented, but the features are typical of frame-based systems.) As in semantic nets, frames inherit fillers through ‘inst’ links, which contact an individual to a category, and through ‘isa’ links, which connect a subcategory to a supercategory. Other forms of inference in frame-based systems include computing or verifying the value of a slot using inherited procedures or constraints and categorizing a new individual as an instance of a category based on its features (Minsky 1975, Borgida et al. 1989).

Obviously, frame-based systems are in many ways similar to object-oriented programming languages; indeed, the two theories interacted strongly in their development.
The chief advantages of frame-based architectures are expressivity, flexibility, and ease of use. The chief disadvantages is lack of precision, and lack of a well-defined model of inference. The architecture provides a wealth of features and options for both representation and inference, but only a weak underlying model. Hence, in a complex case, it is difficult to predict how these features will interact, or to explain unexpected interactions, which makes debugging and updating difficult.
4. Content
The most difficult problems facing the designer of a knowledge base are those of content: What knowledge is needed for a given application, what concepts are needed, and how can the knowledge be effectively encoded in a given architecture?
For specialized knowledge-based systems, known as expert systems, the accepted procedure of encoding knowledge involves an extended collaboration between a human expert and a ‘knowledge engineer.’ The knowledge engineer observes the expert solving a problem, and interviews him in as great depth as possible as to how he found the solution, how his reasoning was justified, what additional factors could have led him to other conclusions, and so forth. The knowledge engineer then abstracts a system of concepts and rules, and implements a prototype reasoning program. The knowledge engineer tests the program on a collection of examples, the expert provides a critique of the behavior of the program, and the knowledge engineer uses this critique to refine and improve the program (Stefik 1995).
In encoding commonsense knowledge, a popular methodology is to begin by defining a microworld, a small, coherent domain of study. Aspects of the real world that lie outside the microworld will either be idealized away or dealt with in a coarse, ad hoc manner. A collection of commonsensically obvious inferences in the microworld is assembled. The researcher constructs a formal model that suffices to justify these inferences; defines symbols to express the concepts used in the inferences; and expresses the knowledge involved in the inferences in terms of these symbols in the chosen knowledge-base architecture. Over the course of time, the microworlds considered become broader in scope and richer in detail (Davis 1990, 1998).
4.1 Time
The issues involved in content may be illustrated in a discussion of representations of time, certainly the most ubiquitous domain in automated reasoning.
Ontologically, time may be taken to be discrete or continuous, to be linear or branching, to consist of points or of intervals, to be Newtonian or relativistic. Which choice is made depends on the applications being considered. For instance, in a chess-playing program, it is natural to take time to be discrete (as nothing significant happens between successive states of the board), and to be branching (to express the options available to each player at each stage). In reasoning about most physical processes, it is usually desirable to take time to be continuous, in order to describe continuous change, and linear, since no choices are being made. (Uncertainty about the future, as opposed to choices about the future, is easily accommodated in a linear theory of time.) The relativistic model of time need only be invoked if the application involves multiple observers whose relative speed is a large fraction of the speed of light.
Many different languages have been devised for time. Some of the most popular include:
(a) Time stamps. If a linear model of time is used, and clock times are known precisely and are important, then each event can be marked by date and clock time.
(b) Numerical constraints on time. If a linear model of time is used, and clock times are important but are not fully known, then a reasonable representation can use a collection of symbolic constraints between the times of events, such as ‘The date of the painting of More’s portrait comes after Holbein’s birth and before his death.’
(c) The situation calculus. This theory uses a branching, discrete model of time. There are three primary types of entities: situations, which are essentially instant of time; fluents, which are proposition whose value changes over time, such as ‘Clinton is President’; and actions which mediate between one situation and a successor situation. The two principal symbols are ‘results(S, A),’ which maps a situation S and an action A to the situation that results if A is performed in S; and ‘holds(S, F )’ the assertion that fluent F holds in situation S (McCarthy and Hayes 1969).
(d) The event/inter al calculus. Another representation for time popular in KR research is based around intervals and events. There are 13 possible temporal relations between intervals; interval I may entirely precede interval J; or the end of I may coincide with the beginning of J; and so on. The interval language contains primitives to describe these 13 relations, plus the reaction, ‘occurs(I, E ),’ meaning event E occurs in interval I (Allen 1983).
(e) Tense logic. This was developed in the philosophical literature to formalize the tenses of natural language. It is a modal logic, containing operators like, ‘φ will always be true,’ ‘φ has been true at some time in the past,’ and so on (van Benthem 1983).
(f ) Dynamic logic. This representation is popular in formal theories of programming languages. It uses a discrete, branching model of time. Statements have the form ‘after P has been executed, φ will be true’ where P is a plan or a computer program.
4.2 Very Large Knowledge Bases
Several recent projects have attempted to construct knowledge bases that encode some substantial fraction of commonsense knowledge, including the well-known CYC project (Lenat 1995) and the HPKB and Ontolingua projects. The architectures of these systems combine logic-based and frame-based features, and supply powerful and well-designed inference engines and user-interfaces. The associated knowledge bases are extremely large, and have been successfully applied in a number of different tasks, including natural language interpretation, and front ends to commercial databases. No systematic evaluation of the contents of these systems has been published, and the degree of success that has been attained in addressing the fundamental challenges of knowledge representation and commonsense reasoning is therefore difficult to determine.
5. Alternative Approaches
The KR architectures we have considered above, together with many other proposals of a more or less similar flavor, such as production systems, constitute what may be called the ‘classical,’ or (with some question begging) the ‘knowledge-based’ approach to AI. Knowledge representation, in this view, involves large, complex structures of symbols, defined and assembled by hand. This approach to AI essentially derives from a line of philosophical thought running from Descartes through Leibnitz, Frege, and Russell. In the late 1980s and 1990s, however, as a result of the inherent difficulty of this line of research, and of the limited progress that has been made, this approach to AI has been challenged by two alternative methodologies: neural networks, and statistical analysis of large corpora.
Neural network research (Haykin 1999) attempts to construct computational models that resemble, with greater or lesser fidelity, the structure of the brain as currently understood. These models vary greatly in detail, but, generally speaking, they consist of a fixed structure of very many, interconnected, primitive computational parts. Each such part models a single neuron. The behavior of a part is controlled by a small set of numerical parameters. In task execution mode, the network begins with an input state, representing the task to be accomplished, and evolves toward an output state, representing the desired behavior. In learning mode, the network tries to adjust the values of the control parameters so as to achieve optimal behavior during task execution.
The permanent knowledge of such a network is thus encoded in the value of the parameters that govern the neurons. This encoding is typically opaque and distributed; that is, it is not possible to say how the parameter values encode the knowledge or even to localize the knowledge to a particular part of the network. Rather, the knowledge is an emergent property of the network as a whole.
The strength of a neural network lies in the strong theory of learning that applies. Neural networks are also generally very robust; they can often survive well if some of the training data is incorrect, or if some of the components are unreliable. Scope and expressivity are characteristically much more limited than in conventional knowledge-based systems: a neural network generally carries out a small set of narrowly focused tasks.
The difficulties in constructing a neural network are very difficult from those of constructing a symbolic representation. It is not necessary, or indeed possible, to handcraft the representation to fit one’s understanding of the domain. However, it is often necessary to tune the structure of the network and the learning algorithms rather carefully to fit the application. This tuning is much more an art than a science.
The statistical approach to AI involves taking very large corpora of data, and analyzing them in great depth using statistical techniques. These statistics can then be used to guide new tasks. The resulting data, as compared to the knowledge-based approach, are extremely shallow in terms of their semantic content, since the categories extracted must be easily derived from the data, but they can be immensely detailed and precise in terms of statistical relations. Moreover, techniques—such as maximum entropy analysis— exist that allow a collection of statistical indicators, each individually quite weak, to be combined effectively into strong collective evidence.
From the point of view of knowledge representation, the most interesting data corpora are online libraries of text. Libraries of pure text exist online containing billions of words; libraries of extensively annotated texts exist containing hundreds of thousands to millions of words, depending on the type of annotation. Now, in 2001, statistical methods of natural language analysis are, in general, comparable in quality to carefully hand-crafted natural language analyzers; however, they can be created for a new language or a new domain at a small fraction of the cost in human labor (Charniak 1993, Armstrong 1994).
Viewed as a knowledge representation, natural language text is, of course, unparalleled in terms of scope, expressivity, and ease of construction. (A few domains of human knowledge, interestingly, lie largely outside the scope of natural language; natural language is notoriously poor at expressing spatial knowledge or mechanical knowledge, such as how to tie a shoelace.) It is exceptionally weak in terms of precision and support for inference. Natural language constructs are constantly, massively ambiguous, and the disambiguation that human understanders carry out automatically and effortless depends, in many cases, on precisely the kinds of world knowledge whose representation has been found to be so difficult.
Bibliography:
- Allen J 1983 Maintaining knowledge about temporal intervals. Communications of the ACM 26(11): 832–43
- Armstrong S (ed.) 1994 Using Large Corpora. MIT Press, Cambridge, MA
- Bacchus F 1990 Representing and Reasoning with Probabilistic Knowledge: A Logical Approach to Probabilities. MIT Press, Cambridge, MA
- Borgida A, Brachman R, McGuiness D, Resnick L 1989 CLASSIC: A Structural data model for objects. In: Proceedings of SIGMOD ’89. Portland, OR, pp. 59–67
- Charniak E 1993 Statistical Language Learning. MIT Press, Cambridge, MA
- Davis E 1990 Representations of Commonsense Knowledge. Morgan Kaufmann, San Mateo, CA
- Davis E 1998 The naive physics perplex. Artificial Intelligence Magazine 19: 51–79
- Genesereth M, Nilsson N 1987 Logical Foundations of Artificial Intelligence. Morgan Kaufmann, San Mateo, CA
- Glasgow J, Narayanan N, Chandrasekaran B 1995 Diagrammatic Reasoning. MIT Press, Cambridge, MA
- Hayes P 1979 The naive physics manifesto. In: Michie D (ed.) Expert Systems in the Microelectronic Age. Edinburgh University Press, Edinburgh, UK, pp.
- Haykin S 1999 Neural Networks: A Comprehensive Foundation. Prentice Hall, New York
- Lenat D 1995 CYC: A large-scale investment in knowledge infrastructure. Communications of the ACM, 38(11): 33–8
- Mates B 1972 Elementary Logic. Oxford University Press, Oxford
- McCarthy J 1968 Programs with common sense. In: Minsky M (ed.) Semantic Information Processing. MIT Press, Cambridge, MA, pp. 403–18
- McCarthy J, Hayes P 1969 Some philosophical problems from the standpoint of artificial intelligence. In: Metzler B, Michie D (eds.) Machine Learning 4. Edinburgh University Press, Edinburgh, UK, pp.
- Minsky M 1975 A framework for representing knowledge. In: Winston P (ed.) The Psychology of Computer Vision. McGrawHill, New York, pp.
- Mitchell T 1997 Machine Learning. McGraw-Hill, New York
- Newell A, Simon H 1976 Computer science as empirical inquiry: Symbols and search. Communications of the ACM 19: 113–26
- Pearl J 1988 Probabilistic Reasoning in Intelligent Systems. Morgan Kaufmann, San Mateo, CA
- Reichgelt H 1991 Knowledge Representation: An AI Perspective. Ablex Publishing, Norwood, NJ
- Selman B, Levesque H, Mitchell D 1992 A new method for solving hard satisfiability problems. Proceedings of AAAI-92, pp. 440–46
- Sowa J 2000 Knowledge Representation: Logical, Philosophical, and Computational Foundations. Brooks Cole, Pacific Grove, CA
- Stefik M 1995 Introduction to Knowledge Systems. Morgan Kaufmann, San Mateo, CA
- Turner R 1984 Logics for Artificial Intelligence. Wiley, New York
- van Benthem J 1983 The Logic of Time. Reidel, Dordrecht, Netherlands
- Woods W 1975 What’s in a link: foundations for semantic networks. In: Bobrow D, Collins A (eds.) Representation and Understanding: Studies in Cognitive Science. Academic Press, New York, pp. 35–82
- Zadeh L 1987 Commonsense and fuzzy logic. In: Cercone N, McCalla G (eds.) The Knowledge Frontier: Essays in the Representation of Knowledge. Springer-Verlag, New York, pp. 103–36
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality