
Sample High Performance Computing Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our custom research paper writing service for professional assistance. We offer high-quality assignments for reasonable rates.
Many scientific and engineering applications require a higher computing power than standard computers can provide. So in the last three decades of the twentieth century specialized computer architectures for high performance computing (HPC) have been built. They are mainly optimized to execute floating-point operations at very high speed. The fastest HPC systems are also called supercomputers (the term supercomputing is sometimes used as a synonym for HPC). High performance is obtained by vector computing, parallel computing, use of special fast technologies or by a combination of these techniques. This research paper reviews the history of HPC systems, explains the most important high-performance computer architectures, and presents some typical HPC applications.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
1. History Of HPC
Figure 1 demonstrates that the performance of HPC systems based on the LINPACK benchmark (Dongarra 1990) was raised from about 0.1 GFlops−1 (billions of floating-point operations per second) in the 1970s to more than 1000 GFlops−1 in the last decade of the twentieth century; so every decade the performance was increased by two orders of magnitude.
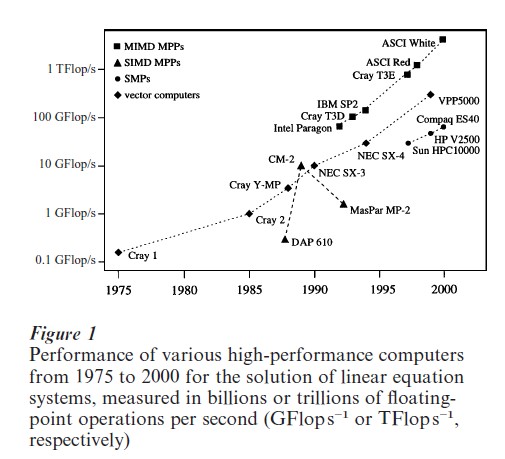
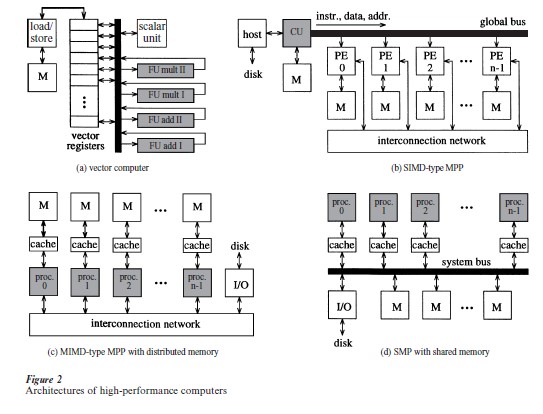
In the second half of the 1970s the introduction of vector computers marked the beginning of the HPC era. They offered a performance advantage of an order of magnitude compared to standard computer systems of that time, reducing the cycle time by introducing pipelining in the processor architecture and supporting high-level operations on complete vectors (e.g., component-wise addition or multiplication) by hardware. Typically, several functional units (FU), each dedicated to a particular arithmetic operation, are avail- able in a vector processor (see Fig. 2(a)) and two or even more result vectors can be computed simultaneously. To achieve a high performance, the pipelines of all FUs must be filled and emptied again at very high speed. Thus, input/output data and intermediate results are read from and written to fast vector registers each holding a fixed number (mostly 64 to 256) of vector elements. Separate load/store units perform an independent and overlapped data transfer from/to memory.
The first vector computer, Cray 1, was introduced in 1976. It is composed of six FUs and one load/store unit and is realized in fast emitter coupled logic (ECL) technology operating at 80 MHz. In later vector processor architectures, such as Cray 2 (1985), Cray Y-MP (1988), NEC SX-3 (1990), and NEC SX-4 (1994), performance was further increased by using up to 16 FUs and up to eight load/store units. Also the clock cycle time was decreased (e.g., by using liquid- cooled processors). During the 1980s, the number of vector processors installed in vector computers grew from one to eight and later to 16. Although they could communicate via a shared memory, it was difficult to use several processors on a single job, so mainly the throughput was increased by running several jobs in parallel.
As an alternative to vector computers, in the 1970s massively parallel processing (MPP) systems appeared as a new class of high-performance computers. Here a large number (typically ranging from 256 to 65,536) of processors, interconnected by a static network, operate in parallel to compute one task. The memory is distributed among the processors. In the first MPP systems the SIMD (single instruction multiple data) operation principle was used. The instructions are broadcast from a control unit (CU) to very simple processors (called processing elements or PEs) where they are executed simultaneously in lock-step mode on different local data items (see Fig. 2(b)). PEs are based on simple arithmetic units operating on words of limited length (often only of 1 bit). Operations on integers or floating-point numbers are performed by software routines that take several clock cycles de- pending on the length of the operands. Thus the power of such machines does not result from the PE itself but from the enormous number of installed PEs. So SIMD-type MPPs perform excellently on applications based on large matrices of short data elements, such as signal or image processing.
One of the first commercially available SIMD-type MPP systems was the distributed array processor (DAP) with up to 4096 PEs arranged in a 64×64 grid. The most famous machine of this class is the Connection Machine CM-1 (1985) and CM-2 (1987) with up to 64k simple one-bit processors connected by a hypercube network (Hillis 1989). For certain applications the CM-2 offered a higher performance than the CRAY Y-MP (see Fig. 1). MasPar MP-1 (with 4- bit PEs, 1990) and MP-2 (with 8-bit PEs, 1992) represent the last important machines of this architecture class, which disappeared from the market in the first half of the 1990s.
At the same time a new kind of HPC systems was proposed: MPPs based on advanced microprocessors operating according to the MIMD (multiple instruction multiple data) principle. In contrast to SIMD architectures the processors execute different tasks asynchronously. A few hundred or thousand cheap off-the-shelf processors designed for high clockfrequencies are interconnected by a network of high bandwidth. However, the communication is much slower than in SIMD-type MPP systems because there is a high overhead for initializing each communication and for synchronizing the processors.
In the first MIMD-type MPP systems, such as Intel’s iPSC series with up to 128 processors or the nCube/2 system (1990) with up to 8,096 processors, the d-dimensional hypercube was the preferred topology. Here each processor can be reached in at most d steps; also twoand higher-dimensional grids can be embedded easily. Later systems were provided with additional communication controllers in each node and used new routing techniques so that the communication time became less dependent on the distance between nodes. Topology was no longer important (if contention is ignored) and cheaper topologies such as a grid or a torus were favored. The Intel Paragon (1992) consists of up to 4,000 Intel i860 processors connected by a two-dimensional (2D) grid. The Cray T3D (1993) and T3E (1997) systems are based on a three-dimensional (3D) torus with up to 2,048 Alpha processors. In the second half of the 1990s, sometimes several workstations or PCs connected by an Ethernet or fiber Channel network were used instead of many integrated processors. Conceptually, this network of workstations (NOW) is not different from a distributed-memory MPP system, but the communication latency is higher.
The advantages of MIMD-type MPP systems are a good price/performance ratio and a good scalability of the architecture. On the one hand cheap and small systems with a few processors and a medium level of performance can be built easily; on the other hand the high performance of expensive vector computers can be reached or even exceeded at lower cost by using a sufficiently large number of processors. Due to the large communication overhead, MIMD-type MPP systems are well suited for applications with a coarsegrain parallelism.
Since about 1995 several companies started to sell symmetric multiprocessor (SMP) models of their workstation families. In the first systems a rather small number (typically 4 to 16) of microprocessors access a shared memory built from several memory modules by using a central system bus (see Fig. 2(d)). Here each variable can be read and updated by each processor, which is supplied with a local cache to reduce the memory access time. The main problem in SMPs is to ensure that each variable remains consistent in all caches, especially when it is updated by one processor. This cache coherency problem is solved via a special protocol. Instead of a single bus often a set of several buses or even a crossbar network are used to reduce the risk of bus contention and to increase the collective bandwidth between memory and processors.
At the end of the twentieth century SMPs with a larger number of processors and a hierarchical interconnection structure became available. Here clusters of tightly-coupled processors are interconnected by a less costly and also slower network. Typical examples are Sun’s HPC series (1997) and Hewlett-Packard’sVclass series (1998). SMPs offer a high performance at low price. However, the scalability is limited: only a medium number of processors can be installed. So the performance levels of MPPs and vector computers cannot be reached (compare Fig. 1).
2. Programming HPC systems
On vector computers any existing sequential code can be used although it should be optimized manually to achieve high performance. For MPPs, SMPs and NOWs, however, the program must be parallelized based on either the data-parallel programming model or the message-passing model.
Data-parallel programs express all operations on vectors and matrices from a global point of view. The compiler automatically maps the data structures onto the parallel architecture. No manual synchronization or communication between the processors must be programmed, so the design of such data-parallel programs is rather simple. Examples of data-parallel languages are the several dialects of C offered by the manufactures of SIMD systems and High Performance Fortran (HPF).
In parallel programs based on the message-passing model the user must distribute tasks and data structures among the available processors. The user must also program each synchronization and communication explicitly by sending messages between the parallel tasks running on different processors. Each task can be implemented in a standard programming language such as C, C++ or Java. For the exchange of messages between tasks several standardized libraries such as PVM (parallel virtual machine) or MPI (message passing interface) are available.
3. HPC Applications
In the beginning of the HPC era most applications involved the solution of large systems of linear or (partial) differential equations. Later other computation-intensive applications have emerged, such as the simulation of chemical and nuclear physical models, image processing, virtual reality, and optimization. Also artificial intelligence applications can be accelerated by parallelism—for instance, in 1997, IBM’s MIMD-type MPP system Deep Blue consisting of 32 processors and 512 chess co-processors defeated world chess champion Kasparov. Deep Blue used a parallel alpha–beta tree search algorithm, tuned with expert knowledge, and could generate and evaluate 200 million chess moves per second (Hamilton and Garber 1997).
The simulation of artificial neural networks (ANN) represents another typical HPC application. Many ANN models (such as multi-layer perceptrons or radial-basis function networks) have been proposed that can be applied to many classification, approximation and optimization tasks without a formal treatment of the underlying problem. The training of ANNs by examples requires a high computational power, and many researchers have successfully simulated such ANN training on various parallel computer architectures (for an overview, see Serbedzija (1996)). ANNs involve an inherent massive parallelism that can be exploited for a parallel implementation on different levels: either the neurons (basic ANN operating elements), the synapses (weighted connections between neurons), the layers (in case of a multi-layer network), or the patterns of the training set can be mapped onto different processors. However, especially at the first two levels, the communication computation ratio is rather high because only simple operations are performed in each synapse or neuron between two communication steps. So, in particular, SIMD-type MPPs are well suited for a parallel implementation on all levels because of their good communication capabilities. High performance on MIMD-type MPPs, SMPs and NOWs can only be achieved by a pattern-parallel implementation; however, this technique can be applied to just a few neural learning algorithms. So for ANN simulation the paradoxical situation exists that older (and no longer available) SIMD-type systems are more suitable than modern HPC computer architectures.
The importance of high-performance computers is also steadily increasing in computational neuroscience. Complex biology-oriented neural models can be simulated on HPC systems in acceptable periods of time. Examples are: highly detailed single-cell models (such as a cerebellar Purkinje cell with 4550 compartments (De Schutter and Bower 1994), medium-sized networks of neurons modeled at a less detailed level (such as hippocampal circuits with up to 128 pyramidal cells described by 70 compartments (Traub et al. 1996) or very large networks of neurons modeled at a higher abstraction level (such as the cat’s primary visual system with 16 384 integrate-and-fire neurons (Niebur and Brettle 1994). In all cases discrete-time approximations to the solutions of a large set of nonlinear differential equations must be found.
Furthermore, HPC systems can accelerate several computation-intensive tasks in psychology such as simulating complex models of cognitive processes, simulating realistic models of visual perception, or analyzing electromagnetic activities in the brain. Especially the evaluation of psychological models and the estimation of model parameters yielding a best fit to data requires high computing power (for recent such applications, see Edwards (1997)).
4. Perspective
In the last three decades of the twentieth century, high performance computing was marked by a strong dynamic with a continuous appearing and disappearing of manufacturers, systems, and architectures. This rapid change will probably continue in the near future. Due to technological progress faster microprocessors will become available each year and cheap HPC systems with a few processors will offer a performance that could formerly be achieved only by expensive vector computers or MPP systems. Thus, high-performance computers will no longer be specialized architectures but be the high end of a continuum of fast desktop systems and servers. Scalable architectures can easily be adapted to the performance requirements of most computation-intensive HPC applications. However, for algorithms with high interprocessor communication demands (such as the simulation of ANN), it is not obvious if future HPC systems will be able to provide a sufficiently low communication latency to allow efficient parallel implementation.
A few special applications (such as weather prediction and computational fluid dynamics) require a still higher computing power than near-term HPC systems can provide. In 1996, the US Department of Energy’s Accelerated Strategic Computer Initiative (ASCI) launched a program for a three-fold increase in computing performance every 18 months over a 10year period using commercial hardware only. The first systems, ASCI Red (1997) and ASCI White (2000), consist of more than 7000 microprocessors and exceed 1 TFlops−1 (see Fig. 1).
The scope of HPC applications will be further extended in the future. New applications will emerge, not only in science and engineering, but also in commerce (in areas such as information retrieval, decision support, financial analysis, or data mining). Data-intensive algorithms are used here; they must operate on very large databases containing massive amounts of information (e.g., about customers or stock prices) that have been collected over many years. In particular, the rapid future increase in the amount of data stored worldwide will make HPC indispensable.
Bibliography:
- De Schutter E, Bower J M 1994 An active membrane model of the cerebellar Purkinje cell. Journal of Neurophysiology 17: 375–419
- Dongarra J J 1990 The LINPACK benchmark: an explanation. In: Van der Steen A J (ed.) Evaluating Supercomputers. Strategies for Exploiting, Evaluating and Benchmarking Computers with Advanced Architectures. Chapman and Hall, London, pp. 1–21
- Edwards L (ed.) 1997 Special issue on high performance computer applications in the behavioral sciences. Behaviour Research Methods, Instruments, and Computers 29: 11–124
- Fox G C, Williams R D, Messina P C 1994 Parallel Computing Works. Morgan Kaufmann, Los Altos, CA
- Hamilton S, Garber L 1997 Deep Blue’s hardware–software synergy. Computer 30: 29–35
- Hillis W D 1989 The Connection Machine. MIT Press, Cambridge, MA
- Leighton F T 1992 Introduction to Parallel Algorithms and Architectures: Arrays, Trees, Hypercubes. Morgan Kaufmann, San Mateo, CA
- Niebur E, Brettle D 1994 Efficient simulation of biological neural networks on massively parallel supercomputers with hypercube architecture. Advances in Neural Information Processing Systems 6: 904–10
- Serbedzija N B 1996 Simulating artificial neural networks on parallel architectures. Computer 29: 56–63
- Traub R D, Whittington M A, Stanford I M, Jefferys J G R 1996 A mechanism for generation of long-range synchronous fast oscillations in the cortex. Nature 383: 621–4
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality