
View sample computer forensics research paper. Browse research paper examples for more inspiration. If you need a thorough research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our writing service for professional assistance. We offer high-quality assignments for reasonable rates.
The 1s and 0s that make up digital data are incomprehensible to most people. Even though we have heard about them many times, we often have no idea how the 1s and 0s turn into useful data. Forensic analysts must make sense this data and present it to persuade others. This research paper explains how the binary data (1s and 0s) are exactly equal to a slightly easier way of showing the data: hexadecimal. Hexadecimal is commonly seen as the most fundamental representation of the data. Once expressed, the organization of the data becomes easier to understand. Common structures and methods of discovering and explaining other structures are explained and then shown in two examples: carving a lost or deleted file and finding hidden data in a common JPEG photograph. In the first example, a step-by-step set of commands is used to find and recover a deleted picture. The commands demonstrate the same steps used by automated forensic packages. The second example examines data embedded in a JPEG photograph byte by byte. Using publicly available resources, the structures of embedded data are explained. With this information, an analyst’s ability to present data exceeds the ability of commonly used forensic packages. Along with the examples is a discussion of how these operations are handled by automated forensic tools. The whole is brought together in a discussion of how these techniques can improve testimony and the investigative effectiveness of a forensic analyst.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
Introduction
Digital information in its raw form is expressed as ones and zeros, or more correctly as on’s and off’s. Each single piece of information: one or zero is called a bit. This understanding is part of popular culture, but is essentially useless. Almost all meaningful information is gathered into bytes or “words.” With Intel processors, the standard word is 2 bytes or 16 bits. Even though the fundamentals of chip architecture and low-level file structure may also seem useless to the day-to-day business of an investigator or forensic analyst, the structure of data is critical to understanding digital evidence. While the majority of useful evidence comes from active user files, the majority of disk space is unallocated. This means that either direct interpretation of unallocated space forensic recovery or file carving is necessary to access that space. All three of these activities benefit from some knowledge of reading a hexadecimal presentation of the data. The term “hexadecimal presentation” is specifically chosen because it is merely another way to look at the data on the disk and in no way changes the content of the file.
Fundamentals Of Data: An Explanation Of Hexadecimal Presentation
Data “presentation” refers to the way data is displayed to a user. A native presentation is the way the file was intended to be displayed to a user. Hexadecimal presentation shows the data in a raw form but summarized into couplets of hexadecimal digits. Hexadecimal digits include the familiar 0–9 of decimal but also include A–F. Where the more familiar decimal repeats its digits every 10 counts, hexadecimal repeats every 16. Since these counting systems use the same characters, it is common to specify which system is being used. Hexadecimal numbers are often followed by “xh” to denote hexadecimal (e.g., 00xh); similarly, decimal notation can be noted with “xd” if it is intermixed with hexadecimal.
There is no mathematical difference between counting in hexadecimal (base 16), decimal (base 10), or even binary (base 2). Each notation can be converted to the other with absolutely no loss of information. For example, 255 (decimal) is exactly equal to FF (hexadecimal) which is exactly equal to 1111 1111 (binary). Internet addresses also demonstrate this fact. 192.168.0.1, a valid IP address, is expressed in decimal-dot notation. It can also be expressed in binary as 1100 0000. 1010 1000.0000 0000.0000 0001. However, it can most efficiently be expressed as C0.A8.0.1 in hexadecimal.
Hexadecimal notation is especially convenient for information based on 8-bit bytes. As can be seen in the IP address, two hexadecimal digits – a hexadecimal couplet – can completely express 8 bits. Rather than presenting eight digits in a row, the system uses two digits, making the information easier to interpret.
The underlying structure of a file is often based on a byte structure. Either an 8-bit word (byte) or some multiple of them is used to hold data. In Windows programming, a 16-bit word is called a WORD, a 32-bit word is called a DWORD, and a 64-bit word is called a QWORD. When reading outside resources about file structure, these terms are often used freely with the assumption that the reader understands them. Resources that do not deal specifically with the Windows Application Programming Interface (WinAPI) may use “word” in a different way.
Even when it only requires one or two digits to account for all possible values, a full byte or even a WORD or DWORD may be used to maintain byte alignment. This means that new fields within the data tend to start on the 0th, 4th, 8th, or 12th byte of a row of 16 bytes. Even when only single bytes are used, a full WORD or DWORD may be filled with padding to maintain byte alignment. Although any value can be used for padding, it is most common to find nulls (00xh). When working with tools that allow a user to change the number of columns displayed in hexadecimal, it can be useful to maintain the standard 16 byte width to allow easy recognition of byte aligned file structures.
Basic File Structures
File types are structured according to the needs of their creators; thus, there are no universal rules about file structures. However, most file types use a header and body structure. Headers contain information about the file. A file signature value or “magic number” is often used to identify the file type. There is no guarantee that a signature value is unique to a given file type. The Web site wotsit.org maintains lists of file types by extension and gives signatures values when available. Other commonly found fields in the header include file version number, count of records contained in the file, logical size of the file, checksums of file contents, and many others. Header information usually contains only information necessary to interpret the file structure and identify the file type.
The body of the file contains the data used by the application interpreting the file. All of the possible data types cannot be listed here, but there are a few general types. Text-based file types tend to be presented in Unicode or ASCII equivalent. Most hex tools provide an ASCII interpretation to the right of the hex itself. Unicode corresponds to ASCII with Latin characters (the letters used in English). The only difference noticeable is that Unicode has columns of null (00xh) between the letters. Unicode needs the extra bits to encode accented Latin characters and non-Latin characters. However, in English they are not used so the bits are empty, thus null.
The body of a file may also contain blended text and non-text regularly interspersed. This is the hallmark of a file with discrete records. Each record can either follow a precisely established format or contain its own header information. The contents of the record may need to be interpreted or may be readable as text. Repeating record structures make it much more likely that a file fragment will provide useful information. For example, partial Web browser history files can be recovered and read from the hex without recovering an intact file. In many cases, the human eye can spot repeating patterns or legible fragments of files that cannot be identified by automated file carving software. A few regular expression searches (RegEx) and a little knowledge of file structure can produce accurate and precise results.
Encapsulated File Structures: Encryption, Compression, And Encoding
Sometimes it is not immediately apparent that data is part of a known file type. This may be because the data is encapsulated or layered in other forms of processing. It is common practice in computer science to break a complex task into layers of activity. Each layer is responsible for a discrete task and either passes up or down to the next layer without interacting with the contents. In this way, multiple layers can be imposed on the data found on the disk. Processes that encrypt, compress, or merely convert data can make it impossible to directly analyze the data. The data on disk in no way resembles the original file data when viewed directly, but the original file data can be easily recalled by reversing the encapsulation or layering process. For useful analysis, the data must be converted to a readable format. Automated forensic packages can process this data back through the layers that were imposed on it or it can be done by isolating the file and processing it with a stand-alone tool.
Accessing The Data
There are many tools available that allow an analyst to access data with a hexadecimal presentation. Rather than try to exhaustively list them, an example of each type can serve to illustrate them. XXD is a utility found on Linux systems that will present a file in hexadecimal. It can also be used in Windows with the Cygwin utility. XXD is called from the command shell (e.g., Bash). Unless the file to be examined is small, it is best to send the output to “less” or a GREP search as follows: XXD/evidence/image.dd | grep ffd8ffe1. This line will search a forensic image for a JPEG signature characteristic of a JPEG picture with EXIF data embedded in it. WinHex is a full featured hex editor that is commercially available. Care should be taken when using hex editors to not write to the file being examined. The interface is familiar to Windows users. Familiar menus and dialog boxes allow the user to open a file in hex presentation. Additional dialogs allow a user to open a partition or physical disk the same way. FTK Imager is a commercial-grade imaging and data access tool provided at no cost by AccessData. Imager can open physical devices (disks, CDs, flash drives, etc.), partitions, or files. A file system hierarchy view similar to Windows Explorer allows a user to traverse a file structure and display data in hexadecimal or in its native presentation. FTK Imager is intentionally incapable of performing searches in the data.
Automated Forensic Packages And Hexadecimal-Level Analysis
Automated forensicpackages allow analysts to rapidly conduct searches across multiple data setsand access archive files (layered data) without intermediate steps. These toolsare not rivals or replacements for lower-level tools; quite the contrary, they includelow-level tools with other functions that add greater convenience for theanalyst. Automated tools can contextualize the data within the file system orwithin search results. Automated packages can also prevent human error found incomplex, repetitive tasks; however, they can mask unique aspects of the datathrough consistent presentation. For example, some forensic software takes a file that was never meant to be viewed by a user and presents it as a table of values or an html presentation (shows it as a Web page). While there is no “native” view of the file, hexadecimal presentation is the most accurate. Ifthe software cannot interpret a field of data, it may simply be skipped in the“user-friendly” presentation. If the user relies on the tool, then there may neverbe a chance to see the skipped data until an opposing expert brings it forward.Most forensic experienced users are aware of the warnings to “know” their toolsand the tool’s limitations, but without a firm basis in interpreting thehexadecimal data, they are left thinking that comparing the output of twoforensic tools works as validation; it does not.
Automated packages can also introduce a bias for intact data that can be cleanly presented by the package. There is no denying that automated packages are necessary to process the massive amounts of data found on even a moderately sized corporate system (very roughly 40 GB). It is self-evident that automated packages are needed for home systems that can run into the multiple terabytes. Automated packages tend toward a clean presentation of native views. With huge amounts of data available, there may be justification in searching visible user files first. As this practice is taught to new examiners and becomes ingrained in experienced examiners or, worst of all, becomes part of policy in a police department or forensics practice, it leads to a bias toward intact data of known types. It is easy to automate searches in EnCase™ with EnScripts™. If policy is in place to exclude unknown file types or search only intact data, large amounts of relevant data can be completely missed. It is easy to avoid this with the full text indexing and searches found in FTK: the Forensic Tool Kit™ by AccessData. However, users soon learn to ignore or even explicitly filter out results from unallocated space or files fragments in favor of those that can be cleanly presented. Users of either package can overcome these limitations, but there is a tendency to become complacent with the tool. By getting in the habit of examining “corrupt” files, unknown file types, and fragmentary data, a forensic examiner builds a mastery of forensic examination that goes beyond document review or tool dependence.
Interpreting File Content
The two lines in Fig.1 are output from a hex editor. The first line identifies the column (inhexadecimal, there are 16xd columns). The second is the first 16 bytes of aJPEG photograph with EXIF data embedded. The JPEG signature is FF D8 FF E1xh(bytes 0–3). The JPEG type identifier is 45 78 69 66xh (bytes 6–9). This isfollowed by two null bytes: 00 00xh (bytes A–B). The next two bytes identifythe order of following information 4D 4Dxh (bytes C–D). The ASCIIinterpretation of the bytes (4D 4Dxh) as MM indicates that values should beread left to right as read by Motorola chips (called big endian byte order).The other possible value is “II,” indicating that values should be read rightto left as read by Intel chips (called little endian byte order). Much moreinformation can be found in the following lines like the make and model of thecamera used to create this photograph. The GPS coordinates are also recorded inthis particular photograph (not shown). Without an EXIF aware viewer, ananalyst would not know this data was present without viewing it in hexadecimal;the userfriendly presentation shows only the photograph.

There are thousands of file types in common use, it would be impossible to catalog them all in this research paper, but technical details can be found on the Web in a few common resources. Microsoft file formats can be found in Microsoft TechNet or in the Microsoft Developer Network (MSDN). To identify an unknown file signature or extension, wotsit.org maintains voluminous catalogs of file types. Details of open-source file types can often be found through their SourceForge projects. Some file types are maintained by work groups comprised of representatives from many companies, academic institutions, governmental bodies, etc. Web searching these resources or simply looking for them in the results of a Web search for the first 4–8 bytes, in hexadecimal, from an unknown file will help find authoritative and reliable sources for file formats.
Recovering And Interpreting Data
Files that have beendeleted or corrupted can be recovered by using the techniques described in thisresearch paper. File carving is the process of recovering a file or fragmentsof a file from unallocated space (where the file system has marked the space asunused). The easiest way to do this is to search for a header signature (FF D8FF E1xh for a JPEG picture) and copy all the data between it and the filefooter signature (FF D9xh for a JPEG) as seen below in the last line of a JPEGfile (Fig. 2).

Recovering A File From Start To Finish
In this example, a JPEG photograph was copied to 128 MB flash drive formatted with the FAT32 file system. An image of the physical drive was created with the Linux/Unix utility “dd” using a SMART boot disk on a host system. SMART is a commercial forensic package created by ASR data, but any forensically sound Linux boot disk will work. The raw, bit-stream copy of the flash memory is analyzed using hexadecimal tools mentioned previously. The purpose of this example is to comment on various file structures along the way to recovering the file. A few pointers on the commands will help in understanding what is happening. All commands are issued in a terminal window in the Ubuntu operating system. Multiple commands can be strung together with a “pipe” character (|). Commands can also have options that change the way they act. Each of the following commands defines an operation in the recovery of a file. These same operations are used by automated packages. The automated packages do not actually implement the Linux/ Ubuntu commands, but they have the same functions.
The first step is to find the file to be recovered. As seen previously, the signature of a JPEG file is FFD8FFxh. Choosing to include the fourth couplet, either E0xh or E1xh, limits the number of files found. Removing it has other interesting effects as will be seen later. “xxd” converts a file from a binary stream to a hexadecimal stream. By refining it with command options, it can be used to extract specific information. “grep” is a Unix environment search tool that has been ported out to many other environments. By sending the output of an entire file in a hexadecimal stream to grep, an analyst can search that stream very efficiently. The image file is named “image_dd.001.”
UBUNTU Command: xxd -g 0 image_dd.001 | grep ffd8ff
Output:
0400400: ffd8ffe000104a464946000101010048…… JFIF…..H
By default xxd lists 16-byte lines with a hexadecimal line number. In this case, the line number is 0400400xh. It is not obvious, but that line number is a good sign for carving a complete file. Each sector is 512xd bytes. 512xd equals 200xh. Thus, any line number evenly divisible by 200xh is the first line of a sector. Most files start on sector boundaries, not in the middle of a sector. The first four bytes are ffd8ffe0xh. This is one of the possible JPEG signatures. These bytes are followed by the remaining 12 bytes in hexadecimal followed by the ASCII conversion of the data. One other consideration is that xxd gives output in a conveniently grouped byte pattern by placing a space between each hexadecimal couplet. “xxd –g 0” removes the grouping and makes the output searchable by grep.
It is necessary to convert this line number to decimal. In Windows, open calculator and choose scientific view. Enter 400400 in hexadecimal and convert to decimal. In a Linux command line, also use a calculator: bc. Echo directs output to stdout (the terminal or a pipe). “bc” is the binary calculator. The following command tells echo to repeat the information “ibase = 16; 400400” to bc. bc interprets the input base (ibase) as hexadecimal (16) and the number as 400400 with no other operations. The default base for bc is 10, so the output base stays 10. The output is the 400400xh converted to decimal. When using bc, remember the default input in hexadecimal is uppercase, but the default output of xxd is lowercase. This will be shown in the next example.
UBUNTU Command: echo “ibase ¼ 16; 400400” | bc
Output:
4195328
Once the header location is known, the footer signature location must be found to locate the end of the file. Line 400400xh was the first to contain a JPEG signature, so all previous lines can be skipped. Once again, xxd and grep can locate this value.
UBUNTU Command: xxd -s 4195328 -g image_dd.001 | grep ffd9
Output:
0406 fc0: 20 86 73 13 7a ee 7f ff d9 00 00 00 00 00 00 00.s.z………..
The line number is 0406fc0xh. The first nine bytes are part of the JPEG file. Bytes number eight and nine are the footer signature value (FF D9xh), marking the end of the file. The trailing nulls (00xh) are file slack space. It cannot be seen from the output above, but there are actually 55 bytes of file slack space before the end of the sector and in this case, the beginning of the next file. Those bytes could contain fragments of previous file(s) stored in that sector. In this case, they contain nulls because the media was securely deleted before use in this example.
Again, it is necessary to convert the line number to decimal, but also to add the 9 bytes found in that line. The direct output of the line number needs to be converted to uppercase or produced from xxd using the “-u” switch to make the hexadecimal digits uppercase. The default output of xxd is lowercase and bc requires uppercase. Since decimal and hexadecimal use the same characters for 0–9, it may be hard to tell that the additional nine bytes are added in hexadecimal.
UBUNTU Command: echo “ibase = 16; 406FC0 + 9” | bc
Output:
4222921
A final calculation will yield the file length. This can also be accomplished with a simple calculator.
UBUNTU Command: echo “4222921 – 4195328” | bc
Output:
27593
With all the file location information available, the file itself can be carved out of the image and exported to a file system. In this case, it is simply exported to the working directory containing the image, but the output can be directed to any mounted file system.
UBUNTU Command: dd if = image_dd.001 of = carved.jpg skip = 4195328 bs = 1 count =27593
Output:
27593 + 0 records in
27593 + 0 records out
27593 bytes (28 kB) copied, 0.515814 s, 53.5 kB/s
There is also a new file called “carved.jpg.” It can be viewed with the xview command or with the tools of the desktop environment. To be clear, there is no difference between the carved file and the original. This can be seen by viewing the JPEG file and seeing the picture. It can also be mathematically confirmed by running an MD5 checksum of the original file and the carved file. In this case, the MD5s match, confirming that not one bit is different.
Interpreting Information In A JPEG File
Aside from the pictureitself, there is often other data embedded in a JPEG file. Two of the manytypes of JPEG file are discussed here. The first is the standard “JFIF” file.This is the type of file seen in the previous example. To comply with the JFIF standard,the first two bytes must be the image marker FF D8xh. The second two bytes arethe application marker FF E0xh. These bytes are the header signature value. Afive-byte identifier follows these: 4A 46 49 46 00xh; the identifier has theASCII values JFIF followed by a null terminator. This can be seen in (Fig. 3).

The second type of JPEG file contains additional information embedded within the file. EXIF data is often included with Tagged Image File Format (TIFF) files and JPEG/TIFF files. With photographs, it is most often used to capture camera settings, manufacturer, model, and other details relevant to photographers. As cellular phone cameras have become more common, the data has begun to include other elements like GPS coordinates. EXIF data also includes metadata describing the JPEG file. It is possible to get creation date for the image from the camera rather than from the file system containing the image. Much of this information is typically available through media management software, but automated forensic packages have been slow to update the types of EXIF data offered. This means that without exporting each JPEG file and viewing them in media management software (not forensically sound software), a forensic examiner may miss critical data like the GPS coordinates of where the picture was taken or embedded data possibly used on social media sites. As an alternative, the analyst can learn how to decipher the contents of that data directly.
In the followin gexample, the first 48 bytes of a JPEG picture are used to illustrate how EXIFinformation is stored in TIFF and JPEG files (Fig. 4) (Table 1).


The designers of theJPEG file, the Joint Photographic Experts Group, created the JPEG file to beversatile. A number of options were left open for future development orcustomization. Because of these fields could not be anticipated and listed inthe original file specification, some fields were reserved specifically todescribe subsequent field’s structures and locations. Image File Directories(IFDs) may either contain brief data (IFD resident data) or indicate where moreextensive data stores may be found by following a pointer to another locationin the file. The IFD tag is shown in bold in the example above. Each IDF is 12bytes. The table below explains the first two IFDs from the example above. Thefirst field of the IFD identifies it as tag number 271 (10 F in hexadecimalequals 271 in decimal). This value can be found in the TIFF standard on page 35and in a table on page 117. The TIFF standard document indicates that tag 271is the make of the camera or scanner. The second field in the first IFD is thefield type. According the TIFF standard on page 15, type 2 is 7-bit ASCII text.That means that the camera or scanner make will be reported in ASCII text. Thethird field of the first IFD is the length. Themake of the camera will be reported in 8 ASCII characters. The fourth and finalfield of the first IFD is either the data indicated (make of the camera) or apointer to the make of the camera. The last field has four bytes; if the datalength is greater than four, the value of this field is a pointer to where thedata can be found. Counting 158 bytes from the APPO section (not the beginningof the file), there are 8 ASCII bytes that identify the camera’s make:“HTC-8900.” This cannot be seen the sample; the sample data ends before thethird IFD’s field type is shown (Table 2).
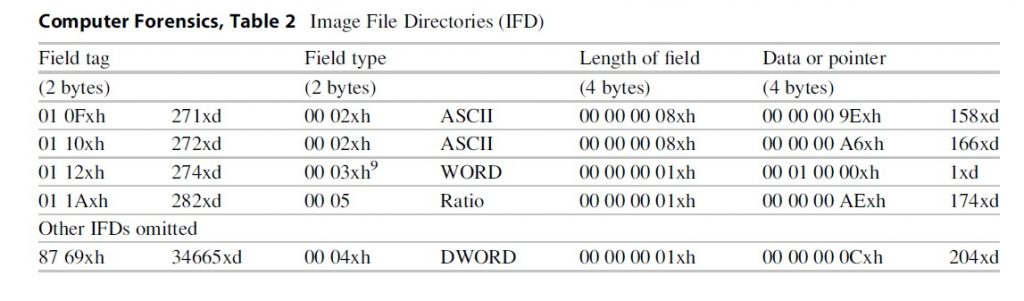
The second IFD indicates the model of the camera or scanner. With the camera phone that created this photograph, the make and model are identical. The one difference that can be seen in the IFD is the pointer. The previous pointer was 158 bytes and the data occupied 8 bytes; the new pointer is 166 bytes (158 + 8 = 166). The third IFD is the orientation of the picture. The field type indicates that this is a WORD (2 bytes). The length of field indicates that only one unit is used to store the data. Since the field type is WORD and only one unit is used, the data for this IFD occupies one WORD or 2 bytes of data. The data or pointer field will contain data if it is less than four bytes. This IFD has resident data. Only the first two bytes are used, so the remaining two bytes are padded with a null (00xh).
The final IFD in the first group will indicate that there are no more IFDs with a pointer of 00 00 00 00xh or will give a pointer to the next IFD table. The tag type 34665 is reserved to indicate that the IFD does not contain displayable content but either a final entry or a pointer to the next set of entries. Tags higher than 32,768xd are considered private tags. They are typically used by organizations, hardware makers, or software makers for special data to be stored. There are no firm standards on where in the file an IFD can be stored. The presence of unique IFDs at unpredictable locations means that an analyst who is completely reliant on a given tool will likely miss data.
Both Finding And Interpreting Data In A JPEG
Another lesson presented by exploring the EXIF data is that pointers within a file indicate the location of data anywhere within the file. EXIF data can be placed anywhere within the Application Use area, as defined by the APPO marker and length. The JPEG file standards document, used to decipher the bytes found in the JPEG header, indicates that a JPEG is a wrapper for content data. Part of that data is one or more pictures, but part of it can be text or some other form of data. The file examined for EXIF data actually contains two images. A search for the image marker: FF D8xh shows that there can be three markers in a JPEG file. There is one marker at the beginning of the file, another at the beginning of a thumbnail, and a third at the beginning of the full-sized image. A fragment with a complete thumbnail may appear to be only a few lines of the greater image because the thumbnail does not display. The thumbnail may provide confirmation that the image was present on the system or it may show enough detail to prove useful. With out some knowledge of the underlying file structure, it is easy to ignore the image as being corrupt or incomplete.
Forensic Examination And Testimony
It is rare that a forensic examiner making conclusions supported by the data is challenged. The most common scenario in law enforcement forensics is the simple production of documents or images that speak for themselves. The challenge often lies in finding the data and backing the results with properly documented procedure, but not always. The most common scenario for civil forensic examiners is simple preservation of data in a forensically sound manner and production of documents for review by either an attorney or a content expert. Again, the challenge lies in producing a result in a consistent and searchable format with well-documented procedure, but not always. For this type of case, an automated forensic package with consistent results from a process that can be replicated is the tool of choice. They allow large volumes of data to be processed reliably.
For a subset of investigations in both civil and criminal forensics, the analyst must go deeper to understand what has happened to a particular file or in the system itself system. In the example above, the EXIF data contained in the picture includes GPS coordinates of where the picture was taken. The EXIF data in that picture also contains date and time stamps. Such times might differ from the file times that were created when the picture was downloaded from the camera. The EXIF data contains the make and model of the camera which can help match the camera to one seized at a crime scene. All of this information can help make a case, if the investigator is aware of it. In civil forensics, an “expert” may testify that all of a given type of file was produced to the opposing side during discovery. Without the ability to interpret and understand file types that are not known to the automated package used, the “expert” may miss an entire file type with crucial data. Almost worse, the “expert” may not warn the attorney of the presence of such information. An entire legal strategy may fail based on a key fact that was absent to the uninformed side.
Using the data from the JFIF and EXIF examples, it has been shown that files in unallocated space can be identified and recovered in a process known of file carving. By first locating the header signature of a file, then locating the footer signature, and copying all the data in between, an analyst can carve a file from unallocated space. This allows the analyst to demonstrate an understanding of the process used by automated tools that carve files. If segments of the file are stored in more than one location, a state called “fragmented,” an analyst can still derive useful information from EXIF data found in the initial fragment. Garfinkle (2007) published data that estimated 92 % of files found on an NTFS volume were intact or fragmented once. This means that most files can be found and carved intact. The remaining, fragmented, files can still yield useful results. If fragmentation is minimal, then file structure may indicate how to carve and combine the pieces.
Conclusion
Understanding the structures of digital files is more than an academic exercise. Analysts who limit themselves to the output of the tool do not bring any special skill to their analysis. Automated tools play an important role in rapidly processing large amounts of information, but they should not be allowed to set boundaries on the evidence. Restricting the data considered to easily displayed files places boundaries on the data. The inability to interpret file fragments places boundaries on the data. Even self-evident results can be successfully challenged by calling into question the process that produced them or the knowledge of the person who chose the process. Sometimes, an opposing expert can even pray on the ignorance of an analyst. The analyst either questions his or her own results or argues beyond his or her knowledge. The best defense to such challenges is a deep and thorough understanding of how the tools work and the structure of the data found as it sits on the disk.
Bibliography:
- Adobe Systems (1992) TIFF: Revision 6.0, http://exif.org/TIFF6.pdf
- Aware Systems (2008) Tiff tag reference, GPS tags, https://www.awaresystems.be/imaging/tiff/tifftags/privateifd/gps.html
- Becker R, Payne S (2011) International data forensic solution center: computer forensics investigation training. International Data Forensic Solution Center, Phillipsburg
- Garfinkle S (2007) Carving contiguous and fragmented files with fast object validation. Digital Invest 4(S 1):2–12
- Maischein M (2011) The TIFF file format: I-TIFF, https://www.fileformat.info/format/jpeg/corion.htm.
- Murray J, Van Ryper W (1996) Encyclopedia of graphics file formats, 2nd edn. O’Reilly Media, Sebastopol, CA
- National Digital Information Infrastructure & Preservation Program (2011) Still images: tags for tiff and related specifications, https://www.loc.gov/preservation/digital/formats/content/tiff_tags.shtml
- Nugent T, Moolenaar B (1996) XXD manpage. https://www.unix.com/man-page/OpenSolaris/1/xxd/.
- Pal A, Memon N (2006) Automated reassembly of file fragmented images using greedy algorithms. IEEE Trans Image Process 15(2):385–393
- Pal A, Sencar H, Memon N (2008) Detecting file fragmentation point using sequential hypothesis testing. Digital Invest 5(S 1):2–13
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality