
Sample Cognitive Psychology Of Literacy Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. iResearchNet offers academic assignment help for students all over the world: writing from scratch, editing, proofreading, problem solving, from essays to dissertations, from humanities to STEM. We offer full confidentiality, safe payment, originality, and money-back guarantee. Secure your academic success with our risk-free services.
Once oral language was evolving, humans needed to code and decode it for purposes of storage, transmission, and tradition. Thus, writing systems (scripts) were invented and literacy, that is, competence with a written language, evolved. Cognitive psychology of literacy studies how the cognitive processes underlying (de-)coding oral language function in reading, spelling, and writing and how humans learn to become skilled literates. It uses a variety of cognitive models (e.g., boxological, mathematical, and computational; for a classification see Jacobs and Grainger 1994) and methods (e.g., psychophysics, mental chronometry, brain imaging) to explain how humans (learn to) perform the fundamental processes underlying literacy: (a) code elementary speech sounds as written symbols (e.g., phonemes as letters in alphabetic scripts) and vice versa, (b) transform information about those symbols (e.g., phoneme letter identities and their relative position) into information about meaning, and (c) transform information about meaning into written symbols.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
1. Major Issues
Most of the cognitive research on literacy studies the question how humans learn and apply the alphabetic principle in perception and action, that is, the fact that in many languages letters (or letter groups) symbolize elementary speech sounds. Other major issues concern: (a) the functional units of learning processing spoken and written language (e.g., letters vs. words; phonemes vs. syllables), (b) the question which role phonological awareness, that is, explicit knowledge of the sound structure of words, plays in acquiring literacy, or (c) the causes of individual differences and deficits in the acquisition of literacy and methods to remedy such deficits.
1.1 Learning And Processing Scripts: A Question Of The Right Mapping
Literacy involves the mapping of multiple symbols and mental representations of symbol-related perceptions and actions on to each other. Cognitive psychology provides models for necessary and possible mapping processes and methods for testing those models. Since a single script can represent speech at more than one level of representation and different scripts represent different levels, an elementary task for learners of scripts is to detect the basic (i.e., most fine-grained) level at which visual and phonological representation meet (identity relationship) and to develop efficient cognitive processes for discriminating between them and for generalizing from known representations to new ones. About 10 levels of representations are possible: logogen, morpheme, syllable, onset, rime, nucleus, coda, phoneme, phon, and articulatory feature. By hypothesis, in logographic morphophonological languages like Chinese, the basic processing level is the word. In syllabic languages (e.g., Japanese kana), the same vowels or consonants (phonetically) are represented by different graphic features, depending on the syllable in which they occur. Therefore, the basic level is the syllable. In alphabetic orthographies (phonographic languages) the basic level is the phoneme, because letters code phonemes, not phones (e.g., [p] vs. [ph]). In such languages, a necessary condition for literacy is to detect the alphabetic principle and to develop both stable and flexible representations of the critical spelling-sound/sound-spelling relations.
The task of inducing the right relations is made difficult by a number of learning processing problems that differ across alphabetic languages. First, language users have to deal with the inconsistency of soundspelling and spelling-sound mappings: identical visual units can represent different sounds and identical sounds can represent different visual units, as illustrated in the famous ‘Beware of HEARD a dreadful WORD, it looks like BEARD and sounds like BIRD.’ Thus, acquiring literacy should be easier in languages with more consistent mappings (ideally, one-to-one mappings, as in Serbo-Croatian) and more difficult in languages with more inconsistent ones (many-to-many mappings). Indeed, quantifiable differences in the consistency of languages lead to differences in learning and processing performance. In English, whose spelling system was developed to keep morpheme (root meanings) spelling constant (e.g., heal health), about 40 phonemes have to be represented by 26 letters: thus, distinctive letter groups (i.e., graphemes) are required to represent all phonemes. Furthermore, about a dozen vowel segments in speech have to be represented by only five letters (in comparison: in Italian seven stressed vowels code five letters, any of which is pronounced uniquely). As a consequence, approximately 31 percent of English words are spelling-tosound inconsistent. Basically, this inconsistency is due to vowel ambiguity: in contrast to initial and final consonants that have the same pronounciation in about 96 percent to 91 percent of words, in only about 50 percent of the words, vowels are pronounced the same. Learners of English adapt to this fact by using higher units of processing than the basic level: by using onsets and rimes, the spelling-to-sound mapping becomes more consistent (vowels are now pronounced the same in about 80 percent of the words) and performance in a variety of psycholinguistic tests improves.
In contrast to English, there is evidence that learners of languages that are more spelling-to-sound consistent use basic-level representations (i.e., phonemes) in perceptual and motor processing (i.e., reading, spelling, writing): German (in which approximately 90 percent of words are spelling-to-sound consistent) or Italian children detect the alphabetic principle earlier and exhibit better decoding skills than English (Cossu et al. 1995, Wimmer and Landerl 1997). There is also evidence that even in skilled adult readers word recognition performance is affected by both the spelling-to-sound and sound-to-spelling mapping: words that are consistent both ways (e.g., duck) are processed better than words that are inconsistent both ways (e.g., swarm) with words being inconsistent either way yielding intermediate performance levels (note that approximately 80 percent of English and French words are sound-to-spelling inconsistent, as compared to 50 percent of German words). A simple and reliable predictor of skilled adult reading performance in English, as measured by the naming task, is the ratio of consistent pronounciations to all pronounciations of a given orthographic segment. The (type) consistency ratio of the orthographic segment-ave, for example, is 1/(1+12)=0.08, because there is only one word (have) with the /Av/ pronounciation compared to 12 (monosyllabic) words with a different pronounciation (save, gave, cave, etc.). Taking word frequency into account, the consistency ratio is very much increased to 0.89, because the token frequency of have is very high in relation to the summed frequency of its orthographic neighbors.
This notable asymmetry in the consistency of languages can be used to explain the observable asymmetry in the difficulty of reading and spelling: according to Bosman and Van Orden (1997) spelling is more difficult than reading for speakers of English because the sound-to-spelling mapping is more inconsistent than the spelling-to-sound mapping and because the sound-to-spelling inconsistencies must be resolved by the semantic-spelling dynamic, which is relatively weak in comparison to the semantic-sound dynamic that develops earlier in language learning. In contrast, sound-spelling inconsistencies are resolved by the stronger semantic-sound dynamic. This fundamental spelling-reading asymmetry is enhanced by the fact that reading is a more frequent Activity than spelling.
A second problem in acquiring the alphabetic principle is that higher-level representations are more accessible than lower-level ones. English-speaking kindergarteners have better access to the number of syllables in a word than to the number of phonemes in a syllable. They also have better access to rimes than to phonemes.
A third problem is the dominance of meaning over form. An example from children is the observation that common semantic features of two words (e.g., the fact that tiger and clown are associated with a circus) can mask phonological differences between them (e.g., that tiger and clown have different onsets). An example which should be familiar to all adult readers is that one has better mnestic access to semantic features than to form features (e.g., uppervs. lower-case) of words.
1.2 Functional Units In Orthographic And Phonological Awareness Processing
Which units are functional in learning and processing scripts? All of the above-mentioned 10 representation levels are possible, in principle, but some have been studied more extensively than others and seem to play a predominant role. As concerns visual units, the majority of studies suggest that reading is letter-based (e.g., Nazir et al. 1998), but some evidence favors the hypothesis that in addition it can also be word-based. However, intermediate units, such as graphemes (i.e., letter clusters representing a single phoneme) have also been found to play a role in word recognition performance: Identification times are longer for words that have fewer phonemes than letters (e.g., beach is composed of five letters and three phonemes, i.e., /biJ/) as compared to words with equally many phonemes and letters (e.g., crisp/krIsp/ ) suggesting that graphemes can be functional reading units (Rey et al. 1998). In addition, onset and rime can play a role in processing written English, as discussed above.
As concerns the problem of phonological awareness, the standard assumption is that three levels play a role: syllable, onset-rime, and phoneme (Byrne 1998).
As concerns the problem of meaning computation from written words, the debate revolves around the alternative: Phonological recoding of written words (i.e., the translation of visual units into sound codes in reading) as a necessary condition for meaning ex-traction vs. direct reading, that is, the computation of meaning without involvement of sound representations and processes. A related open question is whether orthographic and phonological processes are interactive or independent, and whether they develop interactively or sequentially (see Sect. 2). Many studies suggest that written words automatically activate their sound representations and there is increasing evidence for strong interactions between orthographic and phonological processes even in skilled adult readers (Ziegler et al. 1997).
1.3 Deficits
Reading, spelling, and writing disorders are complex, as evidenced by the postulated existence of at least seven types of dyslexias (peripheral: neglect dyslexica, attentional dyslexia, and letter-by-letter reading; central: nonsemantic reading, surface dyslexia, phonological dyslexia, and deep dyslexia) and about the same number of dysgraphias.
The standard position is that the basic problem underlying developmental disorders of literacy is a phonological processing deficit both in alphabetic and non-alphabetic scripts (e.g., Chinese; Siegel 1998), as efficiently diagnosed by the pseudoword reading test (see Sect. 3). However, possible deficits in temporal and visual processing including eye movements must also be considered.
2. Methods
A wealth of cognitive methods allows to study the multiple processes involved in the investigation of literacy. Pragmatically, they can be classified on various dimensions, such as modality (auditory vs. visual presentation), cognitive aspect (perceptual, mnestic, motor) and task (detection, discrimination, classification, identification), or dependent variable (error rate vs. simple or choice reaction time).
Apart from standard classroom reading and writing tests, tests of phonological awareness are most important for discovering potential developmental disorders in literacy acquisition. Adams (1990) classified the enormous set of tests into five difficulty classes (selected examples are given from difficult to easy): phoneme deletion, addition, or exchange; phoneme tapping; syllable splitting; oddity task, that is, detecting the odd item in a set (e.g., lot, cot, hat, pot); and rhyming task.
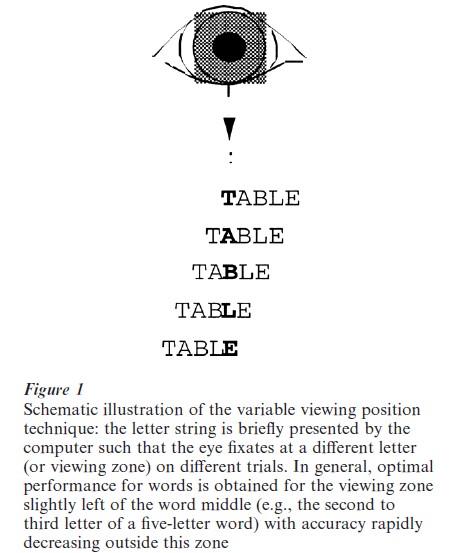
More sophisticated, computer-controlled tests from psychophysics and mental chronometry (i.e., measurement of reaction times) should complement standard (paper–pencil) classroom reading tests more often in the future. Among the multiple perceptual identification tests, such as the classical Reicher paradigm for properly measuring the word-superiority effect, the grapheme detection (Ziegler et al. 1997) and word fragmentation tests (Ziegler et al. 1998) or the variable viewing position (see Fig. 1; Nazir et al. 1998) and luminance increment procedures (Rey et al. 1998) are recent promising examples for quantifying potential perceptual disorders. For example, children who do not show a word-superiority effect (i.e., the fact that letters in words are processed better than letters in other conditions, such as in pseudowords or in isolation) in the Reicher task may have a deficit in phonological recoding or lexical processing. Deficits in phonological recoding can be assessed with the grapheme detection test using the absence of a pseudohomophone effect as diagnostic: normal readers yield suboptimal performance for pseudohomophone stimuli (e.g., brane) as compared to control stimuli (e.g., brate), presumably because of an automatic phonological recoding of letter strings. Deficits in lexical processing can be quantified and computationally modeled with the fragmentation test in combination with an interactive activation model of performance in this test. The variable viewing position procedure in combination with the mathematical model of Nazir et al. (1998) allows parametrization of the capacity to integrate letters into words which is an important element for the acquisition of literacy.
The standard alphabetic and lexical decision tasks (i.e., decide as quickly and accurately as possible whether a single sign is a letter or not, or whether a letter string is a word or not, respectively) allow to assess how well alphabetic and lexico-orthographic knowledge can be accessed without a necessary involvement of phonological or semantic processes (Grainger and Jacobs 1996). The naming task (i.e., pronounce a letter string as quickly and accurately as possible) can measure the ease of accessing knowledge about grapheme-phoneme relations. This task is especially interesting for diagnosing problems in acquiring literacy when using pseudowords, because difficulties with reading aloud pseudowords are a reliable indicator of dyslexia (Siegel 1998). For example, to assess whether children have (implicit) knowledge of and access to the rule ‘a final e in a onesyllable (English) word makes the vowel long,’ pseudowords like rike, fute, or mose can be used.
3. Models
As a rule of cognitive psychology a given cognitive test should be accompanied by a falsifiable cognitive (process or task) model that makes explicit the processes and structures underlying performance in the test and allows qualitative and quantitative predictions about performance to assess its validity. Contemporary cognitive models relevant to studies of literacy and reading can be distinguished according to about a dozen criteria (Jacobs and Grainger 1994). Three basic lines that separate them are: (a) prequantitative vs. quantitative, (b) rationalist vs. associationist, and (c) learning vs. performance models.
Prequantitative and quantitative models complement each other: Modeling a given aspect of reality in a prequantitative manner, such as the ubiquitious ‘boxological’ (i.e., boxes-and-arrows) models of cognition, allows to summarize a wide variety of data obtained with different methods in a static, informal, abstract way. Macroscopic boxological models can be tested at the level of qualitative predictions of off-line data, such as behavioral errors in neuropsychological studies. In order to allow falsifiable predictions, such prequantitative models have to be made more explicit in the form of either mathematical or computational models. Mathematical models use closed-form expressions to describe general functions of dependent vs. independent variables in order to detect lawful relations and are mainly static and very abstract. An example is Nazir et al.’s (1998) model of visual effects in word recognition that can be used to parametrize reading disorders. Computational models allow testing of quantitative predictions of on-line behavioral data that takes into account complex, nonlinear, dynamic interactions between many cognitive processes at different microscopic levels of representation. Prominent examples relevant to research on literacy are interactive activation (Grainger and Jacobs 1996), activation–verification (Paap et al. 1999), dual-route (Coltheart et al. 1993), and parallel distributed processing models of word processing (Zorzi et al. 1998).
Most cognitive models in this field follow the basic rationalism vs. associationism distinction in the philosophy of mind, that is, viewing the mind as a modular system in which rules manipulate symbols vs. the mind as an association machine that detects and acts on correlations between events. Currently open questions addressed by such models are: (a) whether graphemephoneme relations are represented by rules or associations or both, (b) whether reading aloud requires access to whole-word representations in a hypothetical mental lexicon or simply involves grapheme-phoneme associations, or (c) whether spelling requires two processes or only one.
A third difference between cognitive models concerns the focus on learning vs. processing performance. There is a variety of prequantitative models attempting to model the acquisition of literacy, some of which postulate independent stages, while others assume interactive development of orthographic and phonological processes. Increasing evidence favors the latter view (Ehri 1997). As concerns quantitative models, basically, distributed connectionist models allow to study learning problems, while localist connectionist models allow to simulate processing problems (Grainger and Jacobs 1998). Both can complement each other in simulating the main learning processing problem in acquiring literacy: Analyzing oral speech in a way compatible with the symbols and representations composing the script.
4. Applications
For more than a century, teaching literacy has been the battlefield of advocats of different forms of the whole-word method (also known as meaning-based approach) competing with advocats of different forms of the ‘phonics’ approach. In the former method the mapping between written and spoken words is taught explicitly at the expense of making explicit letter phoneme mappings. In the latter approach, children are taught to break words down into their component letters and ‘sound them out.’ More studies support a superiority of phonics approaches (Byrne 1998), but, of course, an exclusive choice of one or the other method is not necessary: many kinds of mixture approaches are possible. Note, however, that the optimal method depends on the particular spelling-to-sound and sound-to-spelling mappings of a language (Wimmer and Landerl 1997).
5. Challenges
In a world full of illiterates and dyslexics, the biggest challenge for cognitive psychology surely remains to provide the applied disciplines with the necessary and sufficient fundamental knowledge allowing to design efficient and reliable methods for diagnosis, teaching, training, and rehabilitation. Given the enormous, heterogeneous set of models and methods in the cognitive literature on literacy, another challenge is theoretical and methodological unification. For example, fundamental research on speech perception still remains relatively disconnected from research on reading and writing; research on implicit learning and working memory is still widely separated from research on literacy; more research on standards for model building and evaluation, as well as for evaluating diagnostic and teaching methods is needed, if we want to fully explain the conditions favoring optimal acquisition and mastering of literacy; finally, so far, too little effort has been spent on developing a formal framework for evaluating the sensitivity, reliability, or validity of cognitive tests relevant to literacy research, such as the ubiquitious lexical decision or the naming tasks.
Bibliography:
- Adams M J 1990 Beginning to Read: Thinking and Learning about Print. MIT Press, Cambridge, MA
- Bosman A M T, Van Orden G C 1997 Why spelling is more difficult than reading. In: Perfetti C A, Rieben L, Fayol M (eds.) Learning to Spell: Research, Theory, and Practice across Languages. LEA, Mahwah, NJ, pp. 173–94
- Byrne B 1998 The Foundation of Literacy. Psychology Press, Hove, UK
- Coltheart M, Curtis B, Atkins P, Haller M 1993 Models of reading aloud: Dual-route and parallel-distributed-processing approaches. Psychological Review 100: 589–608
- Cossu G, Shankweiler D, Liberman I Y, Guigliotta M 1995 Visual and phonological determinants of misreadings in a transparent orthography. Reading and Writing 7: 237–56
- Ehri L C 1997 Learning to read and learning to spell are one and the same, almost. In: Perfetti C A, Rieben L, Fayol M (eds.) Learning to Spell: Research, Theory, and Practice across Languages. LEA, Mahwah, NJ, pp. 237–69
- Grainger J, Jacobs A M 1996 Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review 103: 518–65
- Grainger J, Jacobs A M 1998 On localist connectionism and psychological science. In: Grainger J, Jacobs A M (eds.) Localist Connectionist Approaches to Human Cognition. Erlb-aum, Mahwah, NJ, pp. 1–38
- Jacobs A M, Grainger J 1994 Models of visual word recognition: Sampling the state of the art. Journal of Experimental Psychology: Human Perception and Performance 20(6): 1311–34
- Nazir T A, Jacobs A M, O’Regan J K 1998 Letter legibility and visual word recognition. Memory & Cognition 26: 810–21
- Paap K R, Chun E, Vonahme P 1999 Discrete threshold versus continuous strength models of perceptual recognition. Canadian Journal Experimental Psychology 53(2): 227–93
- Rey A, Jacobs A M, Schmidt-Weigand F, Ziegler J C 1998 A phoneme effect in visual word recognition. Cognition 68: 71–80
- Siegel L S 1998 Phonological processing deficits and reading disabilities. In: Metsala J L, Ehri L C (eds.) Word Recognition in Beginning Literacy. LEA, Mahwah, NJ, pp. 141–60
- Wimmer H, Landerl K 1997 How learning to spell German differs from learning to spell English. In: Perfetti C A, Rieben L, Fayol M (eds.) Learning to Spell: Research, Theory and Practice across Languages. LEA, Mahwah, NJ, pp. 81–96
- Ziegler J C, Rey A, Jacobs A M 1998 Simulating individual word identification thresholds and errors in the fragmentation task. Memory and Cognition 26: 490–501
- Ziegler J, Van Orden G C, Jacobs A M 1997 Phonology can help or hurt the perception of print. Journal of Experimental Psychology: Human Perception and Performance 23: 845–60
- Zorzi M, Houghton G, Butterworth B 1998 Two routes or one in reading aloud? A connectionist dual-process model. Journal of Experimental Psychology: Human Perception and Performance 24: 1131–61
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality