This sample DNA and genetic engineering research paper features: 10100 words (approx. 33 pages), an outline, and a bibliography with 23 sources. Browse other research paper examples for more inspiration. If you need a thorough research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our writing service for professional assistance. We offer high-quality assignments for reasonable rates.
Outline
Introduction
An Introduction to Biotechnology and Genetic Engineering
Early Concepts of Inheritance
Gregor Mendel: The Father of Genetics
Hugo DeVries: The Mutation Theory of Evolution
Morgan and Muller: The First Genetic Experiments
The Discovery of the DNA Molecule
Chromosomes: Compact DNA
DNA Structure: The Double Helix
DNA Replication
The RNA Molecule
Transcription: DNA to RNA
Translation: Protein Synthesis
DNA Sequencing
The Human Genome Project: Living in the Postgenomic Era
Anthropology has studied humankind in numerous capacities: morphologically, culturally, archaeologically, and philosophically. However, the knowledge gained by understanding the DNA molecule has increased our knowledge of humankind on a genetic and molecular level. In addition, with the completion of the Human Genome Project in 2003, the entire human genome has been sequenced and is now available for analysis. This is important to anthropologists because it allows the field to go beyond the bones and into the DNA.
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
Genetic engineering may provide scientific ways to explore the chemical record provided by DNA. Anthropologists will be able to view and explore the past, the present, and conceivably the future of any species, including our own, by the scientific examination of DNA. In addition, understanding DNA and genetic engineering will potentially provide anthropologists with analytical data to explain our genetic relationship to other primates. This type of data will serve to strengthen and further clarify earlier DNA homology studies that have already provided empirical evidence of our close genetic relationships to chimpanzees and gorillas. In the future, this technology can be used to determine our genetic relationship to Neanderthals and Cro-Magnons.
The genetic study of Homo sapiens sapiens is possible because the DNA molecule provides a chemical record of humankind’s genetic makeup and evolutionary history as a process of time. This chemical record will allow examination because DNA is present in every cell in the body and is universal to all life-forms on this planet. All current conglomerations of DNA in all living species are a result of genetic variation and natural selection within populations throughout ongoing organic evolution.
An Introduction to Biotechnology and Genetic Engineering
The two terms biotechnology and genetic engineering are used somewhat synonymously. However, the two have different origins and initially they had slightly different applications. Biotechnology, by conventional definitions, is the intentional alteration of other living things (i.e., plants and animals) for the purpose of benefiting humankind. This has been done throughout the history of our species. In fact, the word clone is Greek for “twig,” because small sprouting twigs were removed from mature trees and planted in order to grow new trees.
Examples of early biotechnology include breeding animals that have desirable characteristics in order to increase the chances of producing offspring with those characteristics. It was noted even as far back as ancient times that if a fast male horse was bred with a fast female horse, most of the offspring would be fast.
Another example of early biotechnology would be the intentional pollination of specific crops that are more disease resistant and yield better fruition, while purposely not pollinating other crops lacking those desired characteristics.
Historically this method of biotechnology was limited to controlling what type of particular male specimen bred with a particular female specimen in an attempt to procure favorable genetic characteristics in the resulting offspring. In many ways, these practices were an early form of eugenics.
Genetic engineering is similar to biotechnology in that there is an alteration of an organism’s characteristics. In contrast to biotechnology, the process of genetic engineering denotes the intentional alteration of the actual DNA by using applications of new scientific technology that make changes at a molecular level. This means that a change is made in the actual genetic constitution of a cell by introducing, modifying, or eliminating specific genes by applying modern molecular-biologic techniques.
Another distinction is that biotechnology has traditionally been applied to agriculture for improving food products and livestock, whereas genetic engineering has more applications in medicine and anthropology. However, modern biotechnology has integrated genetic-engineering techniques as opposed to just utilizing breeding strategies to achieve those improvements. Due to the fact that biotechnology currently applies genetic-engineering techniques, the two terms are now frequently used interchangeably.
An alternative way to view the effects that biotechnology and genetic engineering could have on a modern population requires the natural manipulation of individuals through human intervention (using eugenics and euthenics or proliferagenics). The desired or beneficial genetic results can now be accelerated with genetic engineering.
From a historical perspective, humankind long ago began to alter the process of natural selection of animals and plants to yield beneficial results. Now, with the advent of genetic engineering, humankind has the ability to accelerate that process even more. In fact, one can speculate that humankind may eventually possess control over its own evolution.
The possibility that humankind may have direct control over its own evolution, by using genetic engineering and DNA nanotechnology, is known as emerging teleology. Emerging teleology is the theory that scientists can direct evolution by using genetic engineering and DNA nanotechnology—a technique that uses molecular recognition to create self-assembling branched DNA complexes, which in turn yields the engineering of functional systems at a molecular level. This concept of emerging teleology was first proposed by philosopher and anthropologist H. James Birx in 1991.
In conclusion, we have to ask ourselves, what is genetic engineering expected to accomplish for humankind? Or what has genetic engineering accomplished for humankind already? As mentioned earlier, understanding DNA can potentially help anthropologists to better understand the genetic relationships among species. Currently, several genetic-engineering techniques are already in use. Modern genetic-engineering applications include the use of genetically modified cells or microorganisms that can accomplish three major benefits:
Cells or organisms can be engineered to producemedically beneficial substances. The most common example of this is the production of insulin. In 1987, the FDA approved the use of the first genetically engineered vaccine, which was used for Hepatitis B.
Genetically modified organisms can be engineered thatwill help in the study of human diseases. An example of this is the use of “knockout mice,” which has helped scientists to understand diseases like cancer.
Gene therapy allows the possibility of curing geneticallyinherited diseases by making corrections to the genetic defect at the level of the gene responsible. This can be achieved by inserting the correct gene(s) or by deleting the defective gene(s).
Although these three major benefits offer the potential to help millions of people—and already have—controversy will ultimately arise over the direct, nonmedical application of genetic engineering to enhance normal physiological functions in humans.
Genomics is the study of the genetic makeup of a species. A genome project of a species is a comprehensive identification and classification of a species’s genetic makeup. Genome projects of several microorganisms have been completed including many viral and bacterial genomes (e.g., Haemophilus influenza and Mycoplasma genitalium genomes were sequenced and completed in 1995). In addition, the Mouse Genome Project was completed in 1996 and the Human Genome Project was completed in 2003. Currently, other primate genome projects are underway, including the Chimpanzee Genome Project and the Neanderthal Genome Project.
In order to understand and conceptualize how understanding the DNA molecule and genetic engineering will impact many areas, including medicine and anthropology, one needs to first appreciate the history leading up to this marvelous technology. In addition, we need to stop and think about how the DNA molecule was discovered and what new technology enabled humankind to accomplish that important discovery. Finally, we need to be aware of the ideas that were proposed to be responsible for the phenomenon of inheritance before the discovery of the DNA molecule.
Early Concepts of Inheritance
Before the DNA molecule was discovered, there were only ideas and theories about heredity and inheritance. The most enduring dogma was the idea of “pangenesis,” which held that all of the cells throughout the human body shed gemmules. These gemmules were believed to be able to collect in the reproductive organs periodically before fertilization and reproduction.
The term pangenesis came from the Greek word pan, meaning whole or encompassing, and genesis/genos, meaning birth/origin. Pangenesis was found in Greek writings in the 5th century BCE and was advocated (and in some ways espoused) by Hippocrates (460–370 BCE). This idea was accepted by fellow Greek thinkers Plato (428–347 BCE) and Aristotle (384–322 BCE). However, Aristotle later attempted to refute pangenesis with his idea of entelechy.
Aristotle proposed the concept of entelechy to explain the manner in which an organism inherits and expresses its traits, which according to this idea are determined by a “vital inner force.” He also noted the idea of “having one’s end within,” meaning that an organism’s essential potential can be actualized by its own vital inner force, or entelechy. Aristotle also believed that this vital force was possessed by males in their semen and that females merely possessed the raw material to be formed.
Pangenesis and entelechy were both prevalent and accepted as facts throughout the Middle Ages by great thinkers such as Albertus Magnus (1193–1280), his student Thomas Aquinas (1225–1274), and Roger Bacon (1220–1294). In the later part of the Middle Ages, a physician named Paracelsus (1493–1541), also known by the name Philippus Theophrastus Aureolus Bombastus von Hohenheim, proposed that semen was actually an extract of the human body, which contained all of the organs in what he called an “ideal form.” He believed that this was the biological link between parent and offspring. He was close.
Jean-Baptiste de Lamarck (1744–1829) proposed a theory that he called inheritance of acquired characters through use and disuse. In his theory, he proposed that changes in an organism’s physiology (over the course of its life span) were acquired and modified through the use of a particular function and then became a permanent and adaptable modification in what he called the germ-line. According to Lamarck, this modification was impressed on the parent form and then transmitted to the offspring, who would, as a result of this process, express this modification as a permanent characteristic that could be altered subsequently through use or disuse.
The acceptance of pangenesis and gemmules appeared as a provisional hypothesis by Charles Darwin (1809–1882) in his publication On the Origin of Species (1859), and later again in The Variation of Animals and Plants Under Domestication (1868). However, Darwin was unaware of the DNA molecule (which was not yet discovered) or of the works of Gregor Mendel (which were published during Darwin’s lifetime, and received but never read by him); therefore Darwin continued to comprehend his theory of evolution according to those concepts of his time— pangenesis and gemmules.
Thus, before any scientific explanation could account for the phenomenon of inheritance (or evolution), there were several unfounded ideas that were accepted. These ideas were mainly pangenesis, gemmules, and entelechy. Later theories such as the use and disuse of acquired characteristics were proposed and gained some popularity, but no theoretical model existed that could scientifically or mathematically account for how characteristics were inherited.
Gregor Mendel: The Father of Genetics
Gregor Johann Mendel (1822–1884) was a monk and a mathematician, and known as “the father of genetics” because his seminal works inspired others to study the phenomenon of inheritance. In 1857, he began conducting experiments using pea plants, Pisum sativum. He bred particular plants together and then he meticulously recorded the characteristics of the resulting offspring.
Mendel’s term character was a description of what we now call a phenotype. Typical characters that Mendel studied and measured were the height of the plants and the color of the pea plant’s flowers. Each character possessed different traits; for example, height was measured as tall, normal, or short; and color was measured as white, pink, or red. Therefore, traits were different varieties of phenotype (i.e., the measurable or observable characteristics of the plants).
Mendel’s experiments demonstrated that the traits of a character were distributed in a mathematically predictable pattern. He used these mathematically predictable patterns to devise two important laws known as Mendel’s laws, which he called the law of segregation and the law of independent assortment.
In general, the first law, which was the Mendelian law of segregation (of genetic factors), was hypothesized by Mendel to mean that each trait (e.g., height or color) must have two “factors.” Mendel would later call these factors “alleles.” One factor, or allele, was inherited from each parent, one from the mother and one from the father. Although two alleles are inherited, only one of the alleles was expressed, and therefore, according to Mendel, they were segregated. Today it is known that gametes are sperm and egg cells, which combine their genetic material during fertilization.
Mendel did not know the underlying biological process in cell replication and division at that time. However, it is now known that during the cell cycle, the DNA replicates itself and divides, yielding two identical cells, each with two sets of chromosomes, known as diploids. This process is known as mitosis. In addition, a specialized version of mitosis takes place with the production of the gametes, in which the gametes, known as haploids, have one set of chromosomes each. This process is known as meiosis. When the two separate gametes (or haploids) are joined during fertilization—one from the mother and one from the father—to form a zygote, the alleles (i.e., the DNA) then recombine.
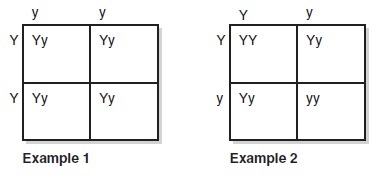
During the course of his experiments, Mendel found that each allele was either dominant or recessive for a specific trait. He elaborated that there were three possibilities. First, if the two alleles were both dominant, then the trait inherited was considered to be homozygous dominant (AA). Second, if the two alleles were both recessive, then the inherited trait was considered to be homozygous recessive (aa). Third, if the two alleles were different, one dominant and one recessive, then the inherited trait was considered to be heterozygous (Aa), or a hybrid. The homozygous dominant, homozygous recessive, and heterozygous combinations could be crossbred and those results could be used to mathematically predict the probability of what type of offspring would result.
The Punnett square was devised by British geneticist Reginald Punnett (1875–1967), who published the first textbook on genetics, Mendelism (1905). He used these Punnett squares to predict the mathematical probability of the outcome of a particular breeding experiment. The results of the Punnett square could be used to predict the probability of possible genotypes of the offspring in a particular cohort given the genotype of the maternal allele and the makeup of the paternal allele.
Mendel’s second law, the Mendelian law of independent assortment (of genetic factors), is where he hypothesized that the inheritance pattern of one trait does not affect the inheritance pattern of another trait (i.e., they assort independently). He justified this with his concept that alleles segregate during gamete formation and then recombine independently of one another. He was incorrect in this assumption. It is now known that there is a multigene interaction and what is known as the blending of inherited traits. This was proven in the early 1900s by Thomas Hunt Morgan (1915/1978) and his colleagues in experiments involving fruit flies.
In essence, Mendel’s second law worked with pea plants because they are much simpler organisms, genetically, than mammals. In addition, the characteristics that he was measuring were not complicated. However, Mendel himself speculated that these laws may only apply to certain species, but he didn’t know why, because the DNA molecule had not been discovered yet. This is the reason why Mendel and others at his time could only study what was being expressed genetically. They did not understand or appreciate the genetic material itself.
In Example 1, a trait that is homozygous dominant (YY) is crossed with a trait that is homozygous recessive (yy). This example yields 100% heterozygous/ hybrid offspring (Yy). In Example 2, two hybrid traits are crossed. This example yields 50% heterozygous offspring, 25% homozygous dominant offspring, and 25% homozygous recessive offspring. This is a classical and simplified example of Punnett squares.
In addition to the two laws that Mendel devised, there are three other elements that made his work significant. First, he demonstrated the value of conducting controlled experiments. Second, he was a mathematician and applied mathematics to analyze and interpret his data. Third, he published his results, which is probably the most significant of all because his findings were not widely acknowledged during his time. However, his works were rediscovered after his death and had a profound effect on the study of inheritance and genetics. His work was of particular significance because this was the first successful mathematical model that had been proposed to explain inheritance.
Hugo DeVries: The Mutation Theory of Evolution
Hugo Marie DeVries (1848–1935) was a Dutch botanist and is considered to be one of the first geneticists. He is known for his mutation theory of evolution, which was chiefly influenced by Gregor Mendel’s laws of heredity, which he rediscovered in the 1890s, and Charles Darwin’s theory of evolution.
DeVries’s (1905/2007) mutation theory of evolution speculated that new varieties of a species could appear in sudden, single jumps as opposed to slowly changing over time. His theory proposed that differences in an organism’s phenotype could change rapidly from one generation to the next; this also became known as saltationism. He based this theory on his experiments, which involved hybridizing plants. One particular observation was made by DeVries during these experiments that influenced and compelled his mutation theory of evolution. Occasionally an offspring appeared that had different characteristics than both the parents and was also different from the other offspring. Based on this finding, he postulated that new varieties of species could appear in nature spontaneously. By this, he in essence proposed that a mutated gene could equal a new species (i.e., mutation equals speciation). This was opposed to Darwin’s theory of gradualism.
DeVries’s mutation theory of evolution was supplanted in the late 1930s by modern evolutionary synthesis, initiated by Julian Huxley (1887–1975). Huxley first introduced this theory in his book Evolution: The Modern Synthesis (1942). At this time, he attempted to rationalize a unification of several biological specialties (e.g., genetics, systematics, morphology, cytology, botany, paleontology, and ecology) in order to postulate a more rational account of evolution. Julian Huxley’s work was stimulated by population genetics and served to clear up confusion and miscommunication between specialties existing at that time. In addition, modern evolutionary synthesis defended the notion that Mendelian genetics was more consistent with Darwin’s gradualism (and natural selection), as opposed to DeVries’s hypothesis of the mutation theory.
The mutation theory of evolution proposed by DeVries had nothing to do with what we currently acknowledge as genetic mutations. The current definition of a mutation is the process by which a gene undergoes a structural change to create a different form of the original allele, which results in a completely new allele. Therefore, spontaneous changes can occur in the DNA that can (but sometimes do not) cause changes in an organism’s physiology. This change does not give rise to the sudden appearance of a new species; rather it can produce a modification of the erstwhile species. This was later supported by genetic research done on white-eyed and red-eyed fruit flies by Thomas Morgan and colleagues (1915/1978).
DeVries was known for another accomplishment that arose from his experiments when he speculated that the inheritance of specific traits of an organism occured through a transfer of particles, which he termed pangenes (derived from the word pangenesis). The term pangenes was shortened 20 years later by Wilhelm Johannsen (1857–1927) to genes. The term gene is currently defined as a basic unit of inheritance.
There was some debate that surrounded the “rediscovery” of Mendel’s work. In DeVries’s publication on the topic of inheritance, he mentioned Mendel in a footnote but took credit for the concept of particles of inheritance with his idea of pangenes. It was Carl Erich Correns (1864–1933), a German botanist and geneticist, who pointed out Mendel’s priority, which DeVries eventually publicly acknowledged.
As it turned out, Carl Corren was a student of Karl Wilhelm von Nageli (1817–1891), a famous Swiss botanist, who had corresponded with Mendel regarding his findings years earlier. Corren was familiar with Mendel’s work as a result of this association. An even stranger twist to this was that when Nageli and Mendel were collaborating, Nageli had actually discouraged Mendel from doing any future work studying genetics, for what he considered religious and ethical reasons.
Morgan and Muller: The First Genetic Experiments
Thomas Morgan (1866–1945) was a geneticist who performed experiments on fruit flies (Drosophila melanogaster). He chose to conduct experiments on fruit flies because they required few resources, reproduced quickly, had observable characteristics that could be measured, and had only four chromosomes, which made them ideal for genetic research.
As a result of his experiments in the “fruit-fly lab,” Morgan established that genes were arranged in a line on what is known as a chromosome, which is present in every living cell. Since genes were believed to be responsible for inheritance and were now shown to exist on chromosomes, this became known as the chromosomal theory of inheritance, which had been alluded to prior to Morgan but had not been supported scientifically. He also noted that there was recombination of inherited characteristics resulting from the exchange of genes between two chromosomes of a pair, which he called “crossing over.” This of course disproved Mendel’s second law of independent assortment.
Morgan collaborated with three of his very important students: Hermann Muller, Alfred Sturtevant, and Calvin Bridges, all of whom continued performing genetic research on fruit flies. Collectively, from around 1908 to 1914, they were able to establish that chromosomes carry genes, those genes are distinct physical objects that are arranged on the chromosomes, the genes also could change place on the chromosomes, the genes could be mutated, and those mutated genes could be reliably inherited in future generations.
Morgan’s experimental proof that genes were discrete physical objects carried on chromosomes and they govern the patterns of inheritance was of major significance. Prior to this, the gene was a speculation with no scientific evidence to support it. Morgan’s research also illustrated that the sex of a species was inherited just as all other characteristics are inherited. He became aware that it was the chromosomal differences between the sperm and egg cells that correlated with the determination of gender. This was proven by his famous experiments with white-eyed male fruit flies and red-eyed female fruit flies.
A significant discovery, made by Hermann Muller (1890– 1967), was that mutations could be caused by exposure to high-energy radiation. This technique enabled them to perform those significant genetic experiments, and to give validity to the chromosomal theory of heredity. Hermann Muller received a Noble Prize for physiology and medicine for his discovery that X-rays induced mutations. He was also the first to visualize genes as the origin of life. The reason he believed this was because genes (or chromosomes) can replicate themselves. He further speculated that all of natural selection and evolution acted at the level of the gene.
Prior to Morgan and Muller, the first proof that chromosomes carried hereditary material came from American physician and geneticist Walter Sutton (1877–1916), based on his research on grasshopper cells. Sutton was the first to speculate that the Mendelian laws could be applied to the chromosomes at a cellular level, which is now known as the Boveri-Sutton chromosome theory. However, it was Morgan’s genetic research that provided enough reproducible scientific data to support the chromosomal theory of heredity, which became generally accepted by around 1915 (even though some geneticists, such as William Bateson, continued questioning it until about 1921).
The Discovery of the DNA Molecule
In the early 1920s, it was generally accepted that genes were arranged on chromosomes and that this is how the inheritance of characteristics arose. However, no one was sure what chromosomes were chemically made of or how they worked.
In 1928, a British scientist named Frederick Griffith (1871–1941), who was influenced by Mendel’s hypothesis of units of inheritance, theorized that a molecule of inheritance must exist. He began conducting experiments on Streptococcus pneumonia and proposed that an inheritance molecule existed and could be passed on from one bacterium to another by a process called transformation. Griffith’s research on transformation proved how an inheritance molecule could be transferred from one bacterium to another; however, Griffith never discovered what the inheritance molecule was. Nevertheless, his work in turn inspired others to continue looking.
During this time, it was known that genes were arranged on chromosomes responsible for the phenomena of inheritance, but no one was able to prove their makeup. This dispute narrowed down to proteins, lipids, carbohydrates, and nucleic acids. The popular belief was that the inheritance molecule was protein because there were more proteins in existence, whereas only four nucleic acids were known (later a fifth nucleotide would be discovered in RNA). Some postulated that it was proteins and nucleic acids that made up the inheritance molecule, but there was no scientific proof to support any of these arguments.
Friedrich Miescher (1844–1895) discovered nucleic acids in 1868, while studying white blood cells. He called them nuclein because they were located in the nucleus, but no proof existed to support the fact that nucleic acids were responsible for the inheritance of characteristics.
In the early 1940s, a scientist named Oswald Avery (1877–1955) rediscovered Griffith’s work on transformation. Avery had the advantage of newer technology and advances in cellular biology. Avery had begun to conduct experiments that selectively destroyed different components (carbohydrates, proteins, lipids, and deoxyribonucleic acids) of a virulent bacterium, which he injected into a mouse. If the mouse died, he concluded that the bacterium had maintained its virulence (i.e., it was able to replicate its virulence). During his experiments, he found the bacteria were able to maintain their virulence when the carbohydrates, proteins, or lipids were destroyed. However, the bacteria were unable to be virulent when their deoxyribonucleic acids were destroyed. Therefore, Avery was the first scientist to prove that the genetic material responsible for inheritance was composed of nucleic acids.
Avery’s findings were very significant because they proved that genes, which are made out of nucleic acids (i.e., deoxyribonucleic acids or DNA), are responsible for the genetic inheritance of all organisms’ characteristics. However, at this time, no one knew what DNA’s structure was or how it functioned.
In 1952, Erwin Chargaff (1905–2002) published results based on his experiments involving the isolation of nucleic acids from three microorganisms: Serratia marcescens, Bacillus schatz, and Hemophilus influenza type C. He was able to separate the nucleic acids using a technique called adsorption chromatography. He discovered that DNA was composed of two purines, adenine (A) and guanine (G), and two pyrimidines, thymine (T) and cytosine (C).
In addition, Chargaff also pointed out that in any section of DNA, the number of A residues was always equal the number of T residues and that the number of C residues were always equal to the number of G residues. This became know as Chargaff’s rule. Later, Watson and Crick (1953) would correctly propose that A and T actually pair together and that G and C pair together (due to hydrogen bonding), which is known as Watson-Crick base pairing. By analyzing the chemical structures of these molecules, Watson and Crick pointed out that A and T both have two hydrogen bonds available, which is why they pair together. C and G have three hydrogen bonds available, which is the reason they pair together. Therefore, Watson and Crick were able to find the molecular explanation of Chargaff’s rule (A=T and C=G), but they went a step further with Watson-Crick base pairing to explain why this is true.
Shortly after Chargaff was making his discovery, another significant discovery was being made by scientists Maurice Wilkins (1916–2004) and Rosalind Franklin (1920–1958). Their research illustrated that the DNA molecule had a helical shape and was made up of two strands that were connected by ladderlike rungs. They were able to prove this by studying crystallized X-ray patterns of DNA.
On April 25, 1953, Watson and Crick published an article proposing a molecular structure of DNA. They had incorporated the findings of Chargaff, Wilkins, and Franklin, as well as their own, to propose that the helical strands were the sugar-phosphate backbone and that the ladderlike rungs were pairs of nucleotides (A=T and G=C). Therefore, Watson and Crick established that the molecular structure of DNA was in fact a double helix. This was significant because they were then able to explore and propose a model to explain how DNA worked.
It should be pointed out that the structure of DNA was discovered based on the research and results of many scientists. Watson and Crick definitely made this significant discovery, but they gained much insight from the works of Chargaff, Wilkins, and Franklin.
Chromosomes: Compact DNA
A chromosome is a long, single piece of DNA that contains several genes; in some species 10 to 40 genes and in other species thousands or more genes can be present in just one chromosome. In eukaryotes, the chromosomes are organized structures that consist of DNA and special structural proteins called histones that wind, coil, and compact large DNA sequences so that they fit efficiently in the nucleus. The chromosome does not always stay condensed, but periodically relaxes and uncoils for replication and for the transcription of proteins. Topoisomerase II is a DNA-nicking-closing enzyme that allows the uncoiling of the DNA supercoils during DNA replication and translation.
In prokaryotic cells, the DNA is either organized in clusters with no nucleus or into small circular DNA molecules called plasmids, which do not contain histones. In viral genomes, very simple chromosomes are found and can be made out of DNA or RNA, which are short, linear or circular chromosomes that usually lack structural proteins.
In all animals, DNA in the chromosomes is packed by histones into globular aggregates known as a nucleosomes. The amino-acid sequence of histones shows almost 100% homology across all species, which illustrates their importance in maintaining chromosomal integrity, structure, and function. In addition, it is now known that the genes that code for histones have no introns.
The DNA strand is wound up and packed with eight histones to form a nucleosome, or what is sometimes called “beaded strings.” These units are further coiled into what is called a solenoid, which contains five to six nucleosomes. The solenoids are then condensed into a chromatin fiber, which has histone H1 holding the core together. The chromatin fiber then folds into a series of loops that are held together by a central scaffold (made of nonhistone chromosomal protein), and this configuration is called a looped fiber. The looped fiber is then coiled to form the fully condensed heterochromatin of the chromosomes.
The coiled and condensed heterochromatin pairs up with an identical copy of itself, and each of the two are referred to as a chromatid. Two identical chromatids are attached to each other by a centromere. The centromere divides both chromatids into a long arm and a short arm. During cell division, microtubules attach to the centromere and align the chromosomes in the center of the dividing cell. The chromosomes are then split, yielding two identical cells—each with its own set of chromosomes. This process is known as mitosis.
All four arms of the chromosome (two long arms and two short arms) have a specialized cap known as a telomere, which has several functions (e.g., preventing the ends from sticking together). The chromosomes also show a distribution of two types of bands. G-bands are A-T rich regions and R-bands are G-C rich regions.
DNA Structure: The Double Helix
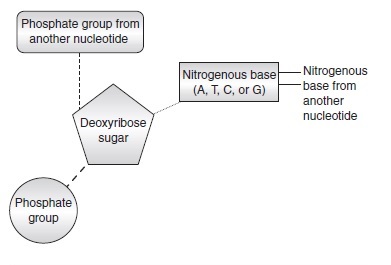
As mentioned earlier, the DNA molecule is composed of two purines (A and G) and two pyrimidines (T and C), and all four are nitrogenous bases. These nitrogenous bases are attached to a deoxyribose sugar, which is attached to a phosphate group to form a nucleotide.
In DNA, a nucleotide is any of the four nitrogenous bases attached to a deoxyribose sugar, which, as explained, is attached to a phosphate group. Because there are four different nitrogenous bases (A, T, G, and C) in DNA, there are four different nucleotides. The deoxyribose sugar can bond with a phosphate group from another nucleotide to form a chain. The nitrogenous base portion of the nucleotide can bond with the nitrogenous base from another nucleotide.
Nucleotides attach side by side to make long strands of DNA. They are able to attach in this fashion by the phosphate group of one nucleotide to the deoxyribose sugar of another nucleotide. This strand is formed in what is known as the 5 prime to 3 prime direction and opposite of this strand is a complementary chain which goes in the 3 prime to 5 prime direction. The original strand is attached to the complementary strand by the hydrogen bond discussed earlier: A=T and C=G. Therefore if the original strand is
5 prime-ATGCTC-3 prime,
the complementary stand is
3 prime-TACGAG-5 prime.
When Watson and Crick proposed the structure of the DNA molecule, they stated that the molecule was a double helix held together by ladderlike projections. The backbone of the helix is the deoxyribose sugar and phosphate group. The ladderlike projections are the base pairs A=T, G=C, T=A, and C=G.
DNA Replication
One of the phenomenal characteristics of the DNA molecule is that it not only stores genetic information but replicates itself. This process is simply known as replication. Replication starts when the double strand is opened up by a helicase enzyme, which exposes the base sequences. While the base pairs are exposed along the template strand, a new strand of DNA (a complementary strand) is synthesized by DNA polymerase.
Replication occurs continuously from the origin of one strand, called the leading strand, which follows the 3 prime to 5 prime direction. The other strand on the DNA molecule replicated is called the lagging strand and does not replicate continuously, but rather in small sections (~100– 200 bases), which are called Okazaki fragments. These fragments are linked together by DNA ligase. The leading strand replicates a complementary strand with DNA polymerase delta, while the lagging strand makes a complementary strand using DNA polymerase alpha.
The process of replication results in two identical copies (called daughter duplexes) of the original strand of DNA. Each daughter duplex contains one parental strand from the original DNA molecule and one newly synthesized strand. This is known as a semiconservative model. In 1958, Matthew Meselson and Franklin Stahl used a scientific technique with radio-labeled nitrogen bases to prove that the DNA molecule replicates using a semiconservative model.
In healthy cells, there is a set of postreplication-repair enzymes and base-mismatch proofreading systems. These systems remove and replace mistakes made during replication (e.g., a wrong base being inserted into a growing strand). Occasionally, a change in the nucleotide sequence takes place; this is known as a mutation.
In 1977, two scientists, Richard Roberts and Phil Sharp, discovered that there were many regions in the DNA that did not code for anything. Roberts and Sharp called these noncoding interruptions introns (short for intervening sequences), and the sections that are coding regions are referred to as exons. They also found that mRNA, which was thought to be an exact copy of a transcribed section of DNA during protein synthesis, was actually missing these intron regions.
Introns are believed by some to be “junk DNA” or filler sequences. However, others believe that the extra sequences may stabilize the DNA molecule, or that the introns may be genetic remnants of evolution (vestigial DNA) and may have been expressed in the past but now lies dormant. In addition, it is conceivable that introns may have a function that presently eludes us.
The RNA Molecule
RNA (ribonucleic acid) is a small, single-stranded nucleic acid that is involved in protein synthesis. Single-stranded RNA (and in rare cases double-stranded RNA) are also found in viruses. Besides being single stranded, RNA differs from DNA in two other important ways. First, DNA contains deoxyribose sugar in its backbone, whereas RNA contains ribose sugar. Secondly, in RNA there is no thymine; rather it is replaced with a different nitrogenous base called uracil, which pairs with A on the DNA molecule during protein synthesis (U=A), just as thymine does.
In the early 1980s, Thomas Cech did a significant amount of research on RNA. At that time it was believed that only proteins could act as biological catalysts. Cech was able to prove that RNA could function as a biological catalyst as well. He even discovered what he called ribozymes (later classified as species of RNA), which take part in the synthesis of mRNA, tRNA, and rRNA. Currently nine types of RNA have been identified:
Heterogeneous nuclear RNA (hnRNA) is transcribed directly from DNA by an enzyme called RNA polymerase. This form of RNA contains all the coding regions (exons) and noncoding regions (introns). Then, hnRNA is processed to yield mRNA for protein synthesis.
Messenger RNA (mRNA) is the modified version of hnRNA, which has had all of the introns removed, and possesses only the coding regions, which contain a code (the triplet code or codons) that is used for transcribing proteins.
Transfer RNA (tRNA) is transcribed from coding sequences on the DNA molecule by RNA polymerase III. This type of RNA possesses an anticodon on one of its ends, which matches a particular section of mRNA. On the other end, tRNA has an amino acid attached. In a basic sense, tRNA serves as an adaptor between mRNA and amino acids during protein synthesis.
Ribosomal RNA (rRNA) exists as several species of rRNA, which are categorized by their sedimentation coefficients that are recorded in Svedberg units (S). A ribosome is composed of two subunits: a large subunit (5S, 5.8S, and 28S) and a small subunit (18S). The ribosome’s function involves holding mRNA in place while the corresponding tRNA attaches amino acids together during protein synthesis.
Small nuclear RNA (snRNA) is found in RNA-protein complexes called spliceosomes. Their function is to remove introns from hnRNA to produce mRNA. In the disease systemic lupus erythematus, the body produces antibodies to snRNA molecules.
Small nucleolar RNA (snoRNA) functions in site-specific base modifications in rRNA and snRNA. These modifications include methylation and pseudouridylation.
Signal recognition particle RNA functions by recognizing particular signal sequences on some proteins and assists in transporting them outside the cell, a process known as exocytosis.
Micro-RNA (miRNA) is believed to control the
translation of structural genes. They are proposed to do this by binding to the complementary sequences in the 3 prime untranslated regions of the mRNA.
Mitochondrial RNA replicates and transcribes independently of the other nuclear DNA and RNA. However, mitochondrial DNA exists as a double-stranded loop (or circle) with an outer, heavy strand and an inner, light strand. Both strands are transcribed by mitochondrial-specific RNA polymerase to produce 37 separate mitochondrial RNA species (mitochondrial rRNA, mitochondrial tRNA, and mitochondrial mRNA).
Many scientists believe that RNA existed before DNA. This is mostly because small forms of RNA can support life (e.g., a virus). However, a virus needs to infect other cells to replicate itself and this is why viruses are known as “obligate intracellular parasites.” Small species of RNA (explained above) are also able to perform biologic activities independently (e.g., they are responsible for protein synthesis from strands of DNA). However, the DNA molecule is a far more stable repository for genetic information and it produces RNA. Therefore, the question of how RNA can exist without DNA to produce it arises. Finally, there is the possibility that both molecules arose at the same time, forming a symbiotic relationship.
Transcription: DNA to RNA
The question now arises, how does DNA make RNA? Transcription is the process by which DNA makes a copy of a section of itself; that copy is RNA and is used for protein synthesis. In the DNA molecule, there are genes known as structural genes that code for proteins. Transcription begins when protein transcription factors attach to a promoter site on the DNA molecule. Next, RNA polymerase Pol II attaches to the transcription factors and then “unzips” the double helix. The complex of transcription factors and RNA polymerase Pol II move downstream (3 prime to 5 prime) along the template strand of the DNA, unzipping it as it moves forward and reconnecting the back portion of the double helix, and forming what is called a transcription bubble. During this process, nucleotides are linked together to form a complementary RNA copy of the coding strand of DNA. This is an exact copy of the DNA called hnRNA.
The hnRNA molecule is modified into mRNA, through ribonucleoprotein complexes called spliceosomes, which are several snRNA molecules that remove introns from hnRNA. The new mRNA molecule is then transported from the nucleus to the cytoplasm, where it will be used to make a peptide or peptides, which are used to make proteins and enzymes.
Translation: Protein Synthesis
Translation is the process in which a strand of mRNA in conjunction with tRNA and rRNA produces peptides and polypeptides. The old central dogma of molecular biology was that DNA makes mRNA, and mRNA makes proteins.
The current theme is that DNA makes hnRNA, and that becomes mRNA (with the help of snRNA), which works with tRNA and rRNA to make polypeptides that are used to make proteins.
On a strand of mRNA, nucleotides pair up in sets of three (e.g., AUG and AAA, which are called triplet codons or codons). Each codon corresponds to an amino acid (e.g., GCA = alanine). There are 64 possible combinations of codons, but several codons represent the same amino acid (e.g., GCA, GCC, GCU, and GCG all represent alanine). Three of the codons—UAA, UAG, and UGA— represent a “stop” signal on the mRNA. AUG represents methionine, which is a “start” signal. The codons make up what is known as the genetic code. It works on the basis of tRNA, which contains and anticodon on one end and an amino acid on the other end.
A strand of mRNA is composed of a start signal (AUG), a coding region of codons, and a stop signal. Translation takes place in the cytoplasm within the endoplasmic reticulum. This process takes place in three main steps:
Initiation: During this phase, the small rRNA subunit (which contains initiation factors) and tRNA, with the methionine (MET) amino acid, both attach to the start signal (AUG) on the mRNA. Then the large rRNA subunit attaches to the mRNA. When the small and large subunits are attached together they are referred to as a ribosome.
Elongation: After initiation is complete and the first tRNA is attached to the strand of mRNA, a second tRNA attaches to the mRNA on the next codon. The second tRNA will correspond to that codon (e.g., the mRNA codon ACG would have tRNA with the anticodon [UGC] and the amino acid threonine [THR] attached). The existing MET amino acid on the mRNA would then form a bond to THR. This bond is a peptidyl transferase reaction, which creates a peptide bond between MET and THR. After that, a third, fourth (and possibly more) amino acids will be connected in this fashion, yielding an elongated chain of amino acids. This process continues throughout the entire coding message of the mRNA molecule.
Termination: In this final phase, elongation continues until a stop codon is reached and enters into the ribosome (rRNA large and small subunits). When this takes place, a release factor disconnects the amino acid chain (called a peptide or polypeptide), and the ribosome splits into a small and large subunit, both of which separate from the mRNA molecule.
After translation is completed, posttranslational modification occurs, which involves the removal of methionine and peptide cleavage.
DNA Sequencing
DNA sequencing is a scientific method for determining the order of the nucleotide bases in an unknown strand of DNA. The original method was devised in the early 1970s by Walter Gilbert and Allan Maxam, and called MaxamGilbert sequencing. Their method was very labor-intensive and involved the use of hazardous chemicals. In 1975, Frederick Sanger developed a quicker, more reliable, and less hazardous method of DNA sequencing called the Sanger method or chain-termination method. This method involves the use of dideoxynucleotides (ddATP, ddTTP, ddCTP, and ddGTP), which are different from normal nucleotides in that they lack a hydroxyl group. Because they lack a hydroxyl group, they interrupt and stop the normal sequence being produced in the complementary strand from the template DNA, which causes a termination in the chain. This termination takes place at that dideoxynucleotide’s spot (A, T, C, or G). This method is sometimes called the dideoxynucleotide DNA sequencing method, or chaintermination sequencing.
Utilizing this technology, a strand of unknown DNA can be taken, amplified using PCR (PCR is a process that rapidly replicates a piece of DNA), and sequenced. The single-stranded DNA of unknown sequence is used as the template and a complementary strand is made using radioactively labeled nucleotides. Next, the radioactively labeled complementary strand is placed in four separated mixes, each containing DNA polymerase and one of each of the four dideoxynucleotides. The four separate mixes are then run through a polyacrylamide of gel electrophoresis in four separate rows, which separates the small fragments of DNA. These four rows of fragments correspond to the particular dideoxynucleotide used. From this, a deduced sequence of the original template strand can be made. Currently a method using automated sequencing, which uses fluorescent markers instead of radioactively labeled markers, is used.
The groundbreaking technology of PCR and DNA sequencing made sequencing a genome a reality. Without this technology, the Human Genome Project would have taken several decades to complete or may have even been unattainable. DNA sequencing also has applications in diagnostic testing and forensics. It can also be used to identify a specific pathogenic mutation that causes a particular genetic disease.
The Human Genome Project: Living in the Postgenomic Era
The Human Genome Project (HGP) was completed in 2003. It had originated as an international project initiated in 1990 by the U.S. Department of Energy and the National Institute of Health. This project had six major goals:
To identify all 20,000 to 25,000 genes in the human genome.
To determine all of the sequences of the chemical basepairs that constitute the entire human genome. The approximate number of chemical pairs is estimated at around 3 billion. It is known that there is a large amount of repetition of these base pairs, and therefore an exact number of chemical base pairs at this time can only be estimated.
To store all of this information and make it available in databases.
To make improvements on computer-based tools for data analysis of biological problems. The field that currently deals with these issues is called bioinformatics.
To transfer these related technologies to private biotechnology and genetic engineering sectors to stimulate further research and product development.
To address the legal, social, and ethical issues that will appear as a result of the completion of the HGP and also the application of genetic engineering.
The completion of the HGP is significant for the field of anthropology because it will improve the study of topics such as germ-line mutations and assist in determining our genetic relationship with Cro-Magnons and Neanderthals, as well as establish the relationship between those two species. The Neanderthal Genome Project was launched in 2006 and upon its completion the Cro-Magnon Genome Project is likely to ensue.
With the completion of the HGP, there are many anticipated improvements in anthropology, medicine, energy, and the environment. However, many ethical and legal concerns will arise as well.
The Origin of Genetic Engineering
The first experiments involving genetic-engineering techniques were made possible by seminal works of three individuals: Paul Berg, Stanely Cohen, and Herbert Boyer. All three scientists were separately working on research and experiments involving DNA. Eventually, they collaborated, using all of their techniques to coordinate the very first experiments involving removal of a gene from one species and inserting it into the genome of another species.
During the years 1972 to 1973, Paul Berg at Stanford University was the first scientist to complete a successful gene splicing experiment. This research involved the removal of a gene from a viral genome called Simian Virus 40 (SV40), which was a monkey virus. He was initially interested in studying a particular gene because he found that SV40 could cause cancer in mice. The advantage of studying a viral genome was that it was very small— approximately a few hundred genes. This allowed him to easily identify and isolate this gene. He then attached this gene to the DNA of a lambda virus (known as a biological vector), which would then insert this gene into another cell. This was the very first time that a gene or genetic material from one organism, in this case a virus, was removed and spliced into the DNA of another organism, in this case a second virus. The new DNA, which had its original DNA along with the spliced DNA, would continue to function as normal and is known as recombinant DNA.
Recombinant DNA is the artificial or synthetic production of DNA, engineered by combining one or more strands of DNA from one source and attaching it to the strand of DNA of another source. This process yields a novel strand of DNA, known as recombinant DNA, that would normally not have existed. The recombinant DNA can then function normally, replicating itself and producing its sequenced products as all other DNA normally does.
Stanely Cohen was another scientist at Stanford University. His initial research was investigating how the genes in plasmids could make bacteria develop resistance to antibiotics. He implemented techniques allowing him to remove a plasmid, which was a small ring of DNA, from one bacterium and insert it into another bacterium. Once the plasmid was inside the other bacterium it could then produce the products that it normally made in the original bacterium. This process happens naturally between bacteria and was originally observed by Fredrick Griffith, who called it called transformation. However, Cohen was able to intentionally and selectively make this process take place.
Herbert Boyer, a scientist at the University of California, was doing research on a bacterium called Escherichia coli (or E. coli), which is normally found in the human intestine. His research involved the use of restriction endonucleases (RE), which were originally discovered by Werner Arber, Daniel Nathans, and Hamilton Smith (they received a Nobel Prize in 1978 for isolating RE). It was discovered that bacteria produce RE to defend themselves against viruses, which work by snipping viral DNA into smaller pieces rendering the virus ineffective. Today there are over 800 RE that are used in laboratories for gene splicing and the production of recombinant DNA. The RE attach to very specific sites on the DNA and can be used to isolate and remove specific sections of DNA. After this technique was refined, Boyer later went on to genetically engineer human insulin, which was the first genetically engineered product approved by the FDA in 1978.
In 1973, the first animal gene was cloned, using the techniques refined by Berg, Cohen, and Boyer. Using Boyer’s RE, Cohen’s technique for removing plasmids, and Berg’s splicing techniques, they were then able to successfully remove and fuse a segment of DNA, which contained a gene from a frog (Xenopus) with the DNA of the bacterium E. coli.
In a basic sense, the frog gene was removed using RE, then spliced into a plasmid, and then inserted into E. coli. After the resulting DNA was inserted into E. coli, the frog gene was transcribed, producing a specific frog protein that was not previously produced by E. coli. This was the very first time that an animal’s gene was removed, inserted into a bacterial genome, and the product of that animal gene successfully produced.
The transfer of DNA from one organism into another organism is possible because DNA is universal among all organisms and cells on this planet. This means that the DNA in a bacterial cell is made up of the same components as the DNA in a human cell. The organism (E. coli) that successfully receives DNA from another organism (the frog gene) is known as a transgenic organism.
Modern Genetic Engineering
The fundamental steps in genetic engineering include the isolation of the DNA, the amplification of the DNA, and the transfer of that DNA into another cell. It is a very complicated process, but a simplification has been made here in order to establish an understanding of the process.
The DNA section of interest is called donor DNA and needs to be isolated from the rest of the DNA. This is done using restriction enzymes, which cut up the DNA into fragments. The restriction enzymes are very specific and cut the DNA at very specific points. Therefore, the DNA of interest can be located and removed.
After the desired section of DNA is isolated, it then needs to be amplified because the amount originally acquired is usually not enough to be effectively transferred. The donor DNA is amplified by a process called the polymerase chain reaction (PCR), invented by Kary Mullis. PCR is a process that rapidly replicates a piece of DNA by using Taq DNA polymerase.
Finally, the isolated and amplified DNA needs to be introduced into the host cell. This is accomplished with biological vectors and nonbiological vectors. Biological vectors are either plasmids or viruses, which were used in the original genetic engineering experiments by Berg and colleagues. Nonbiological vectors include electrochemical poration, biolistics, microinjections, and recombinasemediated cassette exchange (RMCE).
As mentioned, the DNA in all organisms and cells is made out of the same material (nucleotides and sugar phosphates). This is why it is possible to transfer DNA from one organism’s cells into another organism’s cells and this is also why DNA is able to produce its products normally within the new cell after this process is complete.
There are two types of genetic modifications; one involves the addition of genetic material and the other involves the deletion of genetic material or the products it expresses. Deletion is done in one of two ways: knockout and antisense genes.
Gene therapy is classified in one of two ways:
Germ-line gene therapy: This is a genetic modification done on the sperm or the egg (germ cells), which are known as a haploids because they only contain one set of chromosomes, whereas all other cells in the body (somatic cells) contain two identical sets of chromosomes (two chromatids connected by a centromere). When this type of gene therapy occurs, the defective genes are no longer inherited (i.e., the genetic change is passed on from one generation to the next).
Non-germ-line gene therapy: This is a genetic modification that is performed on the somatic cells as opposed to the germ cells. This is also called somatic gene therapy. When this type of gene therapy occurs the genetic disease can still be inherited by future generations. This is because the DNA from somatic cells is altered and these cells are not used for reproduction; therefore the defective genetic material in the haploid germ cells will continue to be passed on to future generations.
In addition to modifying germ cells and somatic cells, the techniques of genetic engineering can also be used to genetically clone species. Cloning is when two (and sometimes more) individuals or cells are produced from one genome.
On July 5, 1996, two scientists, Ian Wilmut and Keith Campbell, cloned the first animal from an adult somatic cell by using a technique called nuclear transfer. The animal was a ewe they named “Dolly.” This showed that one cell could be removed from the body of an animal and be used to re-create a second, identical individual animal.
Individualized Medicine
Other projected use of genetic engineering is the possibility of individualized or genetic medicine. Individualized medicine is a futuristic style of medicine in which treatment will be tailored to the unique genetic needs of the patient. This is also known as personalized medicine. There are two major fields involved with the development of individualized medicine—pharmacogenetics and pharmacogenomics. Pharmacogenetics is an aspect of genetic medicine that studies the genetic sensitivity and differential response of a medication for a patient population. Pharmacogenomics is another aspect that is geared toward the manufacturing of pharmaceuticals with methods of genetic engineering.
In the near future, these two fields will change the way medicine is practiced. It is conceivable that during a typical office visit less time could be spent on deciphering somatic complaints and performing a physical exam, and more time on examining the genetics of the patient.
DNA Consciousness
There is the possibility that the DNA molecule may in fact have a form of consciousness of its own, known as DNA consciousness or molecular/chemical consciousness (Grandy, 2006b, 2009a). This form of consciousness would of course be very different from neurological consciousness or human consciousness. In fact, DNA consciousness may underlie our very own conscious process.
This is a realistic possibility considering certain families of gene clusters; Hox and Pax genes are responsible for and oversee the development of our neurological consciousness. If those genes are altered or deleted, neurological consciousness does not develop.
Other ideas that support DNA consciousness are that the DNA molecule replicates itself, produces proteins freely, communicates chemically with other parts of the cell, and interacts with the external environment of the cell. It performs all of these functions independently. In addition, it is the first known molecule to discover itself (i.e., through Homo sapiens sapiens).
Genetic-engineering techniques may help us to explore this area by enabling scientists to explore how DNA interacts with itself, other molecules, and the environment; how it is able to freely self-replicate, and how it knows when and when not to produce certain products.
Future Directions
The future applications of genetic engineering are numerous indeed. Most of the immediate impact will be seen in the fields of anthropology and medicine. In medicine, there will be improvements in clinical therapeutics and individualized medicine. This will improve life spans and harness the potential to halt or reverse the aging process.
In anthropology, the completion of genome projects will assist in establishing genetic relationships between humankind and other species. In addition to studying our evolution, we could potentially control our evolution. Therefore, emerging teleology could become a reality.
The potential to alter human genomes could create the first transgenic Homo sapiens and provide the appearance of new species on this planet and elsewhere, a concept known as transhumanism. This could also give rise to new species such as Homo sapiens futurensis (the human of the future as proposed by Birx) or Homo sapiens genomicus (the transgenic human as proposed by Grandy).
It is also conceivable that genetic engineering could potentially equip our species with genes that could improve our ability to survive in outer space. This could give rise to Homo sapiens extraterrestrialis. During space travel, there is also the likelihood of encountering alien microorganisms as well as new types of diseases and aliments secondary to space exposure (Grandy, 2009d). This would open a new area of space medicine.
Ethical questions and fears will arise as well. We should be very cautious while considering the modification of our genome because we only understand a small fraction of the interworkings of the DNA molecule. Currently, scientists do not know how altering or modifying a gene in a genome as complicated as the human genome could affect us or future generations. Other ethical concerns will be raised; for example, what are good genes and what are bad genes? Who will make that determination? Originally, nature was in charge of deciding these issues. However, humankind began circumventing natural selection long ago without being prepared to address these questions.
In addition, our environment is not as dangerous (in a predatory sense) as it once was, and advances in medicine have increased human life spans while also allowing individuals—who would normally have died and not passed on their DNA to future generations—to survive and pass on inferior genes. This has given rise to a weaker gene pool or a failure to improve the species (Grandy, 2009c). Genetic engineering could potentially be a remedy to this situation. However, questions will arise over the nonmedical use of genome improvement.
With all of these possibilities on the horizon, we should always stop to remember the many great scientists and their pioneering research that made this a possibility. We should also keep our own humanity in mind as we attempt to tamper with something that we are only beginning to understand.
Bibliography:
Birx, H. J. (1991). Interpreting evolution: Darwin & Teilhard de Chardin. Amherst, NY: Prometheus Books.
Chargaff, E. (1952). On the deoxypentose nucleic acids from several microorganisms. Biochim et Biophys Aeta, 9,
Chow, L. T., Roberts, J. M., Lewis, J. B., & Broker, T. R. (1977). A map of cytoplasmic RNA transcripts from lytic adenovirus type 2, determined by electron microscopy of RNA: DNA hybrids. Cell, 11(4), 819–836.
Darwin, C. (2000). Amherst, NY: Prometheus Books. (Original work published 1887)
DeVries, H. (2007). Species and varieties: Their origin by mutation (Kindle ed.). New York: Evergreen Review. (Original work published 1905)
Galton, F. (1990). Hereditary genius: An inquiry into its laws and consequences. New York: Peter Smith. (Original work published 1869)
Grandy, J. (2006a). Bioinformatics. In H. J. Birx (Ed.), Encyclopedia of anthropology (Vol. 1, pp. 362–363). Thousand Oaks, CA: Sage.
Grandy, J. (2006b). DNA molecule. In H. J. Birx (Ed.), Encyclopedia of anthropology (Vol. 2, pp. 753–756). Thousand Oaks, CA: Sage.
Grandy, J. (2006c). Euthenics. In H. J. Birx (Ed.), Encyclopedia of anthropology (Vol. 2, pp. 873–875). Thousand Oaks, CA: Sage.
Grandy, J. (2006d). Human Genome Project. In H. J. Birx (Ed.), Encyclopedia of anthropology (Vol. 3, pp. 1223–1226). Thousand Oaks, CA: Sage.
Grandy, J. (2006e). RNA molecule. In H. J. Birx (Ed.), Encyclopedia of anthropology (Vol. 5, pp. 2026–2027). Thousand Oaks, CA: Sage.
Grandy, J. (2009a). Consciousness. In H. J. Birx (Ed.), Encyclopedia of time (Vol. 1, pp. 212–216). Thousand Oaks, CA: Sage.
Grandy, J. (2009b). DNA molecule. In H. J. Birx (Ed.), Encyclopedia of time (Vol. 1, pp. 333–335). Thousand Oaks, CA: Sage.
Grandy, J. (2009c). Dying and death. In H. J. Birx (Ed.), Encyclopedia of time (Vol. 1, pp. 352–355). Thousand Oaks, CA: Sage.
Grandy, J. (2009d). History of medicine. In H. J. Birx (Ed.), Encyclopedia of time (Vol. 2, pp. 842–845). Thousand Oaks, CA: Sage.
Henig, R. M. (2001). The monk in the garden: The lost and found genius of Gregor Mendel, the father of genetics. New York: Mariner Books.
Morgan, T. (1978). The mechanisms of Mendelian heredity. New York: Holt, Rinehart & Winston. (Original work published 1915)
Pritchard, D., & Korf, B. (2008). Medical genetics at a glance (2nd ed.). Malden, MA: Blackwell.
Siegetsleitner,A. (2006). Genetic engineering. In H. J. Birx (Ed.), Encyclopedia of anthropology (Vol. 3, pp.1036–1041). Thousand Oaks, CA: Sage.
Watson, J. (1977). The double helix: A personal account of the discovery of the structure of DNA. NewYork: Mentor Books.
Watson, J., & Crick, F. (1953). Molecular structure of nucleic acids. Nature, 171(4356), 737–738.
Wilkins, M. (1953). Crystallinity in sperm heads: Molecular structure of nucleoprotein in Vivo. Biochim et Biophys Aeta, 10,
Yount, L. (2000). Biotechnology and genetic engineering. NewYork: Facts on File.