
View sample Semantic Similarity Research Paper. Browse other research paper examples and check the list of research paper topics for more inspiration. If you need a religion research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our custom writing services for professional assistance. We offer high-quality assignments for reasonable rates.
Semantic similarity refers to similarity based on meaning as opposed to form. The term is used widely throughout cognitive psychology and related areas such as psycholinguistics, memory, reasoning, and neuropsychology. For example, semantically similar words are confusable with each other, and can prime each other, with the consequence that verbal memory performance is heavily dependent on similarity of meaning. In the context of reasoning, people draw inductive inferences on the basis of semantic similarity, for example, inferring that properties of cows are more likely to be true of horses than to be true of hedgehogs (Heit 2001)
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
But what is semantic similarity? In experimental work, semantic similarity is often estimated directly from participants’ explicit judgments. However, there are several advantages to representing semantic similarity within a standardized framework or model. These advantages include the greater consistency and other known mathematical properties that can be imposed by a formal model, and the possible benefits of data reduction and the extraction of meaningful dimensions or features of the stimuli being analyzed. The history of research concerning semantic similarity can be captured in terms of the succession of models that have been applied to this topic. The models themselves can be divided into generic models of similarity and a number of more specialized models aimed at particular aspects of semantic similarity.
1. General Models of Similarity
Although the following accounts are meant to address similarity in general terms, they can be readily applied to semantic similarity. The two classical, generic approaches to modeling similarity are spatial models of similarity and Tversky’s (1977) contrast model. More recently, structured approaches have addressed limitations of both of these classical accounts.
1.1 Spatial Representations
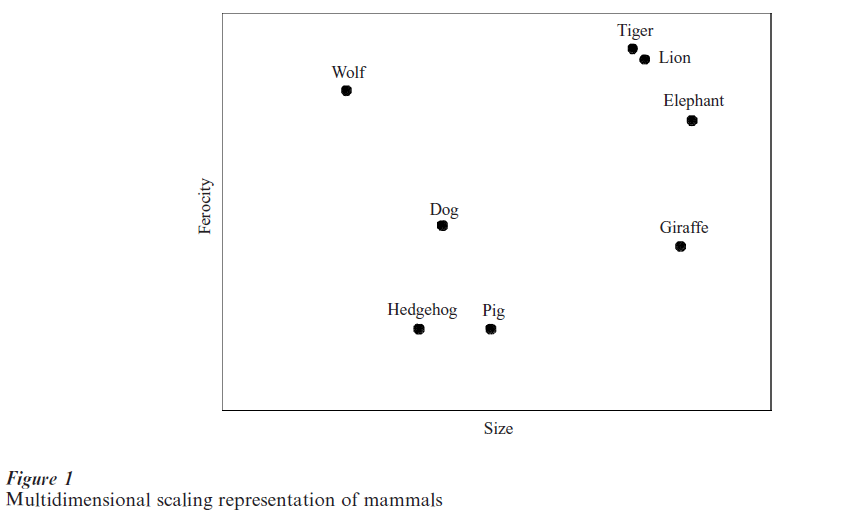
Spatial models seek to represent similarity in terms of distance in a psychological space (Shepard 1980). An item’s position is determined through its coordinate values along the relevant dimensions; nearby points thus represent similar items, whereas distant items are psychologically very different. For example, a spatial representation of mammal categories might represent different animals on dimensions of size and ferocity, with lions and tigers being close on both of these dimensions (Fig. 1). The relevant space is derived using the technique of multidimensional scaling (MDS), a statistical procedure for dimensionality reduction. MDS works from experimental participants’ judgments, typically in matrices of proximity data such as pairwise confusions or similarity ratings between items. Spatial models have been used widely for visualization purposes and as the heart of detailed cognitive models, e.g., of categorization and recognition memory (Nosofsky 1991). Less widely used are related statistical procedures such as hierarchical clustering (Shepard 1980) although they have also been used in the context of semantic similarity.
1.2 The Contrast Model
The traditional alternative to spatial models is Tversky’s (1977) contrast model. This account was developed to address perceived limitations of spatial models which bring these into conflict with behavioral data (but also see Nosofsky 1991). Chief among these are violations of the so-called metric axioms that underlie any spatial scheme, such as asymmetries in human similarity judgments that are not well captured by spatial distance which should be symmetrical. For example, people judged the similarity of North Korea to China to be greater than the similarity of China to North Korea. In the contrast model (Eqn. (1)), the similarity between items a and b is a positive function of the features common to both items and a negative function of the distinctive features of a and also the distinctive features of b. Each of these three feature sets is governed by a weighting parameter which allows the model to capture asymmetries according to the nature of a particular task. According to the focusing hypothesis, greater attention is given to distinctive features of the first item in a comparison than of the second item, hence α > β. When China is more familiar than North Korea, having more known distinctive features, then the similarity from China to North Korea should be lower than the similarity of North Korea to China.
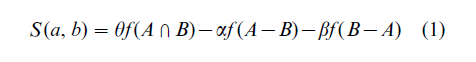
Although applications of the contrast model to the modeling of specific cognitive tasks are fewer than those of spatial models, an application to semantic similarity can be found in Ortony (1979), who applied the model to distinctions between literal and metaphorical similarity.
1.3 Structured Representations
Despite the efforts aimed at establishing the superiority of either the contrast model or spatial models, it has been argued that both approaches share a fundamental limitation in that they define similarity based on oversimplified kinds of representations: points in space or feature sets. Arguably most theories of the representation of natural objects, visual textures, sentences, etc., assume that these cannot be represented in line with these restrictions. Instead, they seem to require structured representations: complex representations of objects, their parts and properties, and the interrelationships between them. Descriptions such as SIBLING-OF (Linus, Lucy) and SIBLING-OF (Lucy, Linus) cannot be translated in an obvious way to either lists of features or points in space that represent the similarity between these two items as well as their differences from BROTHER-OF (Linus, Lucy). (See also Fodor and Pylyshyn (1988) for a critique of attempts in connectionist networks to represent relational structure in a featural framework.)
The perceived need for accounts of similarity to work with structured representations has given rise to the structural alignment account (see Markman (2001) for an overview) which has its roots in research on analogical reasoning. Structural alignment operates over structured representations such as frames consisting of slots and fillers. The comparison process requires that at least some of the predicates, that is relations such as ABOVE (x, y ), are identical across the comparison. These identical predicates are placed in correspondence. The alignment process then seeks to build maximal structurally consistent matches between the two representations.
Structural alignment has been implemented in a variety of computational models (e.g., Falkenhainer et al. 1990, Goldstone and Medin 1994) that have been used to capture behavioral data, especially similarity judgments and analogical reasoning. Experimental results have supported an important prediction of the structural alignment account, that there will be a greater impact of alignable differences compared with nonanalignable differences. Nonalignable differences between two representations are elements of one object that have no correspondence in the other. In contrast, alignable differences refer to representational elements that have corresponding roles in the two representations but fail to match exactly. For example, imagine two tables, one with a flower on top and the other with a bowl on top in addition to a chair beneath it. Comparing the two scenes, flower vs. bowl would be an alignable difference, whereas the chair would be a nonalignable difference.
2. Specialized Models Of Semantic Similarity
2.1 Semantic Differentials
Leaving behind generic models of similarity, semantic similarity has also been captured through a variety of specially built models and approaches. The first of these is Osgood et al.’s (1957) semantic differential. This approach used psychometric techniques to compute the psychological distance between concepts. Participants were required to rate concepts on 10–20 bipolar scales for a set of semantically relevant dimensions, such as positive–negative, feminine– masculine. The ratings of words on these dimensions would essentially form their coordinates in semantic space. The approach is thus related to spatial models of similarity with the difference primarily in the way that the semantic space is derived. Whereas models based on multidimensional scaling require pairwise proximity data for all concepts of interest, the semantic differential approach requires that all concepts of interest are rated on all relevant dimensions. Therefore, the semantic differential method suffers from the difficulty that the relevant dimensions must be stipulated in advance. Still, semantic differentials have been widely used, largely because the data are straightforward to collect, analyze, and interpret.
2.2 Semantic Networks And Featural Models
Osgood et al.’s work motivated the semantic feature model of Smith et al. (1974) which addressed how people verify statements such as ‘a robin is a bird’ and ‘a chicken is a bird,’ considering the defining and characteristic features of these concepts. Verifying the latter statement would be slower owing different characteristic features for chicken vs. bird. The semantic feature model was developed in contrast to Collins and Quillian’s (1969) semantic network model. In this model semantic meaning is captured by nodes that correspond to individual concepts. These nodes are connected by a variety of links representing the nature of the relationship between the nodes (such as an IS-A link between robin and bird). Semantic similarity (or distance) is captured in terms of the number of links that must be traversed to reach one concept from another. Although the semantic network model was a groundbreaking attempt at capturing structured relations, it still suffered from some problems. For example, the model correctly predicts that verifying ‘a robin is an animal’ is slower than verifying ‘a robin is a bird’ owing to more links being traversed for the first statement. However, this model does not capture typicality effects such as the difference between robin and chicken.
2.3 High-Dimensional Context Spaces
Osgood et al.’s semantic differential can also be seen as a predecessor of contemporary corpus-derived measures of semantics and semantic similarity. For example, Burgess and Lund’s (1997) hyperspace analogue to language model (HAL) learns a highdimensional context from large-scale linguistic corpora that encompass many millions of words of speech or text. The model tracks lexical co-occurrences throughout the corpus and from these derives a highdimensional representational space. The meaning of a word is conceived of as a vector. Each element of this vector corresponds to another word in the model, with the value of an element representing the number of times that the two words co-occurred within the discourse samples that constitute the corpus. For example, the vector for dog will contain an element reflecting the number of times that the word ‘bone’ was found within a given range of words in the corpus. These vectors can be viewed as the coordinates of points (individual words) in a high-dimensional semantic space. Semantic similarity is then a matter of distance between points in this space.
Several other such usage-based models have been proposed to date; similar in spirit to HAL, for example, is Landauer and Dumais’s (1997) latent semantic analysis. The basic approach might be seen to be taking to its logical consequence Wittgensteir’s famous adage of ‘meaning as use.’ Its prime advantage over related approaches such as spatial models of similarity and the semantic differential lies in the ability to derive semantics and thus measures of semantic similarity for arbitrarily large numbers of words without the need for any especially collected behavioral data. The ability of these models to capture a wide variety of phenomena, such as results in semantic priming and effects of semantic context on syntactic processing, has been impressive.
2.4 Connectionist Approaches
The final approach to semantic similarity to be discussed shares with these context-based models a statistical orientation, but connectionist modeling has been popular particularly in neuropsychological work on language and language processing. In connectionist models, the semantics of words are represented as patterns of activations, or banks of units representing individual semantic features. Semantic similarity is then simply the amount of overlap between different patterns, hence these models are related to the spatial accounts of similarity. However, the typically nonlinear activation functions used in these models allow virtually arbitrary re-representations of such basic similarities. The representation schemes utilized in these models tend to be handcrafted rather than derived empirically as in other schemes such as multidimensional scaling and high-dimensional context spaces. However, it is often only very general properties of these semantic representations and the similarities between them that are crucial to a model’s behavior, such as whether these representations are ‘dense’ (i.e., involve the activation of many semantic features) or ‘sparse,’ so that the actual semantic features chosen are not crucial. For example, this distinction between dense and sparse representation has been used to capture patterns of semantic errors associated with acquired reading disorders (Plaut and Shallice 1993) and also patterns of category specific deficits following localized brain damage (Farah and McClelland 1991).
3. Conclusion
There is a wide variety of models of semantic similarity available. Underlying this array of approaches is a fundamental tension that is as yet unresolved. Many of the models reviewed can be classed as loosely spatial in nature. These models have all been applied extensively to behavioral data, yet there are fundamental limitations to spatial approaches with respect to their representational capacity, made clear by the successes of the contrast model and the structural alignment approach. The behavioral evidence that relational structure is important to similarity seems particularly compelling. This leaves this area of research with two contrasting and seemingly incompatible strands of models, each of which successfully relates to experimental data. It is possible only to speculate on how this contradiction might ultimately be resolved. One possibility is that spatial models and structured representations capture different aspects or types of semantic similarity: one automatic, precompiled, effortless, and in some ways shallow, and one the result of more in-depth, or line, or metacognitive processing. Such a distinction between types of processing of similarity would be compatible with the success of models based on, for example, context spaces in capturing phenomena such as semantic priming, and the success of models such as those based on structural alignment in capturing phenomena such as analogy, or the understanding of novel concept combinations. Whether such a distinction will take shape or whether there will one day be a single, all-encompassing account remains for future research.
Bibliography:
- Burgess C, Lund K 1997 Modeling parsing constraints with high-dimensional context space. Language and Cognitive Processes 12: 177–210
- Collins A M, Quillian M R 1969 Retrieval time from semantic memory. Journal of Verbal Learning and Verbal Behavior 8: 240–7
- Falkenhainer B, Forbus K D, Gentner D 1990 The structuremapping engine: Algorithm and examples. Artial Intelligence 41: 1–63
- Farah M J, McClelland J L 1991 A computational model of semantic memory impairment: Modality-specificity and emergent category-specificity. Journal of Experimental Psychology: General 120: 339–57
- Fodor J, Pylyshyn Z 1988 Connectionism and cognitive architecture: A critical analysis. Cognition 28: 3–71
- Goldstone R L, Medin D L 1994 The time course of comparison. Journal of Experimental Psychology: Learning, Memory, and Cognition 20: 29–50
- Heit E 2001 Properties of inductive reasoning. Psychonomic Bulletin and Review 7: 569–92
- Landauer T K, Dumais S T 1997 A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review 104: 211–40
- Markman A B 2001 Structural alignment, similarity, and the internal structure of category representations. In: Hahn U, Ramscar M (eds.) Similarity and Categorization. Oxford University Press, Oxford, UK
- Nosofsky R M 1991 Stimulus bias, asymmetric similarity and classification. Cognitive Psychology 23: 94–140
- Ortony A 1979 Beyond literal similarity. Psychological Review 86: 161–80
- Osgood C E, Suci G J, Tannenbaum P H 1957 The Measurement of Meaning. University of Illinois Press, Urbana, IL
- Plaut D C, Shallice T 1993 Deep dyslexia: A case study of connectionist neuropsychology. Cognitive Neuropsychology 10: 377–500
- Shepard R N 1980 Multidimensional scaling, tree-fitting, and clustering. Science 210: 390–7
- Smith E E, Shoben E J, Rips L J 1974 Structure and process in semantic memory: A featural model for semantic decisions. Psychological Review 81: 214–41
- Tversky A 1977 Features of similarity. Psychological Review 84: 327–52
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality