
View sample educational and psychological intervention research paper. Browse research paper examples for more inspiration. If you need a psychology research paper written according to all the academic standards, you can always turn to our experienced writers for help. This is how your paper can get an A! Feel free to contact our writing service for professional assistance. We offer high-quality assignments for reasonable rates.
The problems that are faced in experimental design in the social sciences are quite unlike those of the physical sciences. Problems of experimental design have had to be solved in the actual conduct of social-sciences research; now their solutions have to be formalized more efficiently and taught more efficiently. Looking through issues of the Review of Educational Research one is struck time and again by the complete failure of the authors to recognize the simplest points about scientific evidence in a statistical field. The fact that 85 percent of National Merit Scholars are first-born is quoted as if it means something, without figures for the over-all population proportion in small families and over-all population proportion that is first-born. One cannot apply anything one learns from descriptive research to the construction of theories or to the improvement of education without having some causal data with which to implement it (Scriven, 1960, p. 426).
Academic Writing, Editing, Proofreading, And Problem Solving Services
Get 10% OFF with 24START discount code
Education research does not provide critical, trustworthy, policy-relevant information about problems of compelling interest to the education public. A recent report of the U.S. Government Accounting Office (GAO, 1997) offers a damning indictment of evaluation research. The report notes that over a 30-year period the nation has invested $31 billion in Head Start and has served over 15 million children. However, the very limited research base available does not permit one to offer compelling evidence that Head Start makes a lasting difference or to discount the view that it has conclusively established its value. There simply are too few high-quality studies available to provide sound policy direction for a hugely important national program. The GAO found only 22 studies out of hundreds conducted that met its standards, noting that many of those rejected failed the basic methodological requirement of establishing compatible comparison groups. No study using a nationally representative sample was found to exist (Sroufe, 1997, p. 27).
Reading the opening two excerpts provides a sobering account of exactly how far the credibility of educational research is perceived to have advanced in two generations. In what follows, we argue for the application of rigorous research methodologies and the criticality of supporting evidence. And, as will be developed throughout this research paper, the notion of evidence—specifically, what we are increasingly seeing as vanishingevidenceofevidence—iscentraltoourconsiderable dismay concerning the present and future plight of educational research, in general, and of research incorporating educational and psychological treatments or interventions, in particular. We maintain that “improving the ‘awful reputation’of education research” (Kaestle, 1993; Sroufe, 1997) begins with efforts to enhance the credibility of the research’s evidence.
Improving the quality of intervention research in psychology and education has been a primary goal of scholars and researchers throughout the history of these scientific disciplines. Broadly conceived, intervention research is designed to produce credible (i.e., believable, dependable; see Levin, 1994) knowledge that can be translated into practices that affect (optimistically, practices that improve) the mental health and education of all individuals.Yet beyond this general goal there has always been disagreement about the objectives of intervention research and the methodological and analytic tools that can be counted on to produce credible knowledge. One purpose of this research paper is to review some of the controversies that have befallen psychological and educational intervention research.Asecond, and the major, purpose of this research paper is to suggest some possibilities for enhancing the credibility of intervention research.At the very least, we hope that our musings will lead the reader to consider some fundamental assumptions of what intervention research currently is and what it can be.
Contemporary Methodological Issues: A Brief Overview
Although there is general consensus among researchers that intervention research is critical to the advancement of knowledge for practice, there is fundamental disagreement about the methodologies used to study questions of interest. These include such issues as the nature of participant selection, differential concerns for internal validity and external validity (Campbell & Stanley, 1966), the desirability or possibility of generalization, the appropriate experimental units, and data-analytic techniques, among others that are discussed later in this research paper.
Evidence-Based Treatments and Interventions
Of the major movements in psychology and education, few have stirred as much excitement or controversy as have recent efforts to produce evidence-based treatments. With its origins in medicine and clinical-trials research, the evidencebased movement spread to clinical psychology (see Chambless & Ollendick, 2001, for a historical overview; Hitt, 2001) and, more recently, to educational and school psychology (Kratochwill & Stoiber, 2000; Stoiber & Kratochwill, 2000). At the forefront of this movement has been the so-called quantitative/experimental/scientific methodology featured as the primary tool for establishing the knowledge base for treatment techniques and procedures. This methodology has been embraced by the American Psychological Association (APA) Division 12 (Clinical Psychology) Task Force on EvidenceBased Treatments (Weisz & Hawley, 2001). According to the Clinical Psychology Task Force criteria for determination of whether a treatment is evidence based, quantitative groupbased and single-participant studies are the only experimental methodologies considered for a determination of credible evidence.
The School Psychology Task Force, sponsored byAPADivision 16 and the Society for the Study of School Psychology, has also developed criteria for a review of interventions (see Kratochwill & Stoiber, 2001). In contrast to their clinical psychology colleagues’ considerations, those of the School Psychology Task Force differ in at least two fundamental ways. First, the quantitative criteria involve a dimensional rating of various designs, including criteria of their internal validity, statistical conclusion, external validity, and construct validity. Thus, the evidence associated with each dimension is based on a Likert-scale rating and places responsibility on the consumer of the information for weighing and considering the support available for various interventions under consideration. Table 22.1 provides sample rating criteria for group-based interventions from the Procedural and Coding Manual for Review of Evidence-Based Interventions (Kratochwill & Stoiber, 2001).

A second feature that distinguishes the School Psychology Task Force considerations from previous evidence-based efforts is the focus on a broad range of methodological strategies to establish evidence for an intervention. In this regard, the School Psychology Task Force has developed criteria for coding qualitative methods in intervention research. At the same time, a premium has been placed on quantitative methodologies as the primary basis for credible evidence for interventions (see Kratochwill & Stoiber, 2000; Kratochwill & Stoiber, in press). The higher status placed on quantitative methods is not shared among all scholars of intervention research methodology and sets the stage for some of the ongoing debate, which is described next.
Quantitative Versus Qualitative Approaches
What accounts for the growing interest in qualitative methodologies? Recently, and partly as a function of the concern for authentic environments and contextual cognition (see Levin & O’Donnell, 1999b, pp. 184–187; and O’Donnell & Levin, 2001, pp. 79–80), there has been a press for alternatives to traditional experimental methodologies in educational research. Concerns for external validity, consideration of the complexity of human behavior, and the emergence of sociocultural theory as part of the theoretical fabric for understanding educational processes have also resulted in the widespread adoption of more qualitative methods. In terms of Krathwohl’s (1993) distinctions among description, explanation, and validation (summarized by Jaeger & Bond, 1996, p. 877), the primary goals of educational research, for example, have been to observe and describe complex phenomena (e.g., classroom interactions and behaviors) rather than to manipulate treatments and conduct confirming statistical analyses of the associated outcomes.
Tab. 22.1
For the past 10 years or so, much has been written about differing research methodologies, the contribution of educational research to society, and the proper functions and purposes of scientific research (e.g., Doyle & Carter, 1996; Kaestle, 1993; Labaree, 1998; O’Donnell & Levin, 2001). Some of these disputes have crystallized into the decade-long debate about quantitative and qualitative methodologies and their associated warrants for research outcomes—a debate, we might add, that is currently thriving not just within education but within other academic domains of the social sciences as well (e.g., Azar, 1999; Lipsey & Cordray, 2000). As has been recently pointed out, the terms qualitative and quantitative are oversimplified, inadequate descriptors of the methodological and data-analytic strategies associated with them (Levin & Robinson, 1999).
The reasons for disagreements between quantitative and qualitative researchers are much more than a debate about the respective methodologies. They are deeply rooted in beliefs about the appropriate function of scientific research. Criticism of quantitative methodologies has often gone hand in hand with a dismissal of empiricism. Rejection of qualitative methodologies has often centered on imprecision of measurement, problems with generalizability, and the quality and credibility of evidence. Failures to resolve, or even to address, the issue of the appropriate research function have resulted in a limiting focus in the debate between qualitative and quantitative orientations that trivialize important methodological distinctions and purposes. Unfortunately, the debate has often been ill conceived and unfairly portrayed, with participants not recognizing advances that have been made in both qualitative and quantitative methodologies in the last decade. The availability of alternative methodologies and data-analytic techniques highlights a key issue among researchers regarding the rationale for their work and the associated direction of their research efforts. Wittrock (1994) pointed out the need for a richer variety of naturalistic qualitative and quantitative methodologies, ranging from case studies and observations to multivariate designs and analyses.
In addition, arguments about appropriate methodology have often been confused with a different argument about the nature of scholarship. Beginning with Ernest Boyer’s (1990) book, Scholarship Reconsidered: Priorities of the Professoriate, institutions of higher education have sought ways to broaden the concept of scholarship to include work that does not involve generating new knowledge. This debate is often confused with the methodological debate between the respective advocates of qualitative and quantitative approaches, but an important feature of this latter debate is that it focuses on methods of knowledge generation (see also Jaeger, 1988).
Research Methodology and the Concept of Credible Evidence
Our purpose here is not to prescribe the tasks, behaviors, or problems that researchers should be researching (i.e., the topics of psychological and educational-intervention research). Some of these issues have been addressed by various review groups (e.g., National Reading Panel, 2000), as well as by task forces in school and clinical psychology. As Calfee (1992) noted in his reflections on the field of educational psychology, researchers are currently doing quite well in their investigation of issues of both psychological and educational importance. As such, what is needed in the future can be characterized more as refining rather than as redefining the nature of that research. For Calfee, refining means relating all research efforts and findings in some way to the process of schooling by “filling gaps in our present endeavors” (p. 165). For us, in contrast, refining means enhancing the scientific integrity and evidence credibility of intervention research, regardless of whether that research is conducted inside or outside of schools.
Credible Versus Creditable Intervention Research
We start with the assertion, made by Levin (1994) in regard to educational-intervention research, that a false dichotomy is typically created to distinguish between basic (laboratorybased) and applied (school-based) research. (a) What is the dichotomy? and (b) Why is it false? The answer to the first question addresses the methodological rigor of the research conducted, and which can be related to the concept of internal validity, as reflected in the following prototypical pronouncement: “Applied research (e.g., school-based research) and other real-world investigations are inherently complex and therefore must be methodologically weaker, whereas laboratory research can be more tightly controlled and, therefore, is methodologically stronger.”
In many researchers’ minds, laboratory-based research connotes “well controlled,” whereas school-based research connotes “less well controlled” (see Eisner, 1999, for an example of this perspective). The same sort of prototypical packaging of laboratory versus classroom research is evident in the National Science Foundation’s (NSF) 1999 draft guidelines for evaluating research proposals on mathematics and science education (Suter, 1999). As is argued in a later section of this research paper, not one of these stated limitations is critical, or even material, as far as conducting scientifically sound applied research (e.g., classroom-based research) is concerned.
The answer to the second question is that just because different research modes (school-based vs. laboratory-based) have traditionally been associated with different methodological-quality adjectives (weaker vs. stronger, respectively), that is not an inevitable consequence of the differing research venues (see also Levin, 1994; Stanovich, 1998, p. 129). Laboratory-based research can be methodologically weak and school-based research methodologically strong. As such, the methodological rigor of a piece of research dictates directly the credibility (Levin, 1994) of its evidence, or the trustworthiness (Jaeger & Bond, 1996) of the research findings and associated conclusions (see also Kratochwill & Stoiber, 2000). Research credibility should not be confused with the educational or societal importance of the questions being addressed, which has been referred to as the research’s creditability (Levin, 1994). In our view (and consistent with Campbell & Stanley’s, 1966, sine qua non dictum), scientific credibility should be first and foremost in the educational research equation, particularly when it comes to evaluating the potential of interventions (see also Jaeger & Bond, 1996, pp. 878–883).
With the addition of both substantive creditability and external validity standards (to be specified later) to scientifically credible investigations, one has what we believe to be the ideal manifestation of intervention research. That ideal surely captures Cole’s (1997, p. 17) vision for the future of “both useful research and research based on evidence and generalizability of results.” For example, two recent empirical investigations addressing the creditable instructional objective of teaching and improving students’ writing from fundamentally different credible methodological approaches, one within a carefully controlled laboratory context (Townsendetal.,1993)andtheothersystematicallywithinthe context of actual writing-instructed classrooms (Needels & Knapp, 1994), serve to punctuate the present points. Several examples of large-scale, scientifically credible research studies with the potential to yield educationally creditable prescriptions are provided later in this research paper in the context of a framework for conceptualizing different stages of intervention research.
Components of CAREful Intervention Research
In our view, credible evidence follows from the conduct of credible research, which in turn follows directly from Campbell and Stanley’s (1966) methodological precepts. The essence of both scientific research and credible research methodology can in turn be reduced to the four components of what Levin (1997b) and Derry, Levin, Osana, Jones, and Peterson (2000) have referred to as CAREful intervention research: Comparison, Again and again, Relationship, and Eliminate. In particular, it can be argued that evidence linking an intervention to a specified outcome is scientifically convincing if (a) the evidence is based on a Comparison that is appropriate (e.g., comparing the intervention with an appropriate alternative or nonintervention condition); (b) the outcome is produced by the intervention Again and again (i.e., it has been “replicated,” initially across participants or observations in a single study and ultimately through independently conducted studies); (c) there is a direct Relationship (i.e., a connection or correspondence) between the intervention and the outcome; and (d) all other reasonable competing explanations for the outcome can be Eliminated (typically, through randomization and methodological care). Succinctly stated: If an appropriate Comparison reveals Again and again evidence of a direct Relationship between an intervention and a specified outcome, while Eliminating all other competing explanations for the outcome, then the research yields scientifically convincing evidence of the intervention’s effectiveness.
As might be inferred from the foregoing discussion, scientifically grounded experiments (including both group-based and single-participant varieties) represent the most commonly accepted vehicle for implementing all four CAREful research components. At the same time, other modes of empirical inquiry, including quasi experiments and correlational studies, as well as surveys, can be shown to incorporate one or more of the CAREful research components. In fact, being attuned to these four components when interpreting one’s data is what separates careful researchers from not-so-careful ones, regardless of their preferred general methodological orientations.
The Concept of Evidence
Good Evidence Is Hard to Find
If inner-city second graders take piano lessons and receive exercises that engage their spatial ability, will their mathematics skills improve? Yes, according to a newspaper account of a recent research study (“Piano lessons, computer may help math skills,” 1999). But maybe no, according to informed consumers of reports of this kind, because one’s confidence in such a conclusion critically depends on the quality of the research conducted and the evidence obtained from it. Thus, how can we be confident that whatever math-skill improvements were observed resulted from students’practicing the piano and computer-based spatial exercises, rather than from something else? Indeed, the implied causal explanation is that such practice served to foster the development of certain cognitive and neurological structures in the students, which in turn improved their mathematics skills: “When children learn rhythm, they are learning ratios, fractions and proportions. . . . With the keyboard, students have a clear visual representation of auditory space.” (Deseretnews.com, March 15, 1999, p. 1). Causal interpretations are more than implicit in previous research on this topic, as reflected by the authors’ outcome interpretations and even their article titles—for example, “Music Training Causes Long-Term Enhancement of Preschool Children’s Spatial-Temporal Reasoning” (Rauscher et al., 1997).
In the same newspaper account, however, other researchers offered alternative explanations for the purported improvement of musically and spatially trained students, including the enhanced self-esteem that they may have experienced from such training and the positive expectancy effects communicated from teachers to students. Thus, at least in the newspaper account of the study, the evidence offered to support the preferred cause-and-effect argument is not compelling. Moreover, a review of the primary report of the research (Graziano, Peterson, & Shaw, 1999) reveals that in addition to the potential complicators just mentioned, a number of methodological and statistical concerns seriously compromise the credibility of the study and its conclusions, including nonrandom assignment of either students or classrooms to the different intervention conditions, student attrition throughout the study’s 4-month duration, and an inappropriate implementation and analysis of the classroombased intervention (to be discussed in detail in a later section). The possibility that music instruction combined with training in spatial reasoning improves students’ mathematics skill is an intriguing one and one to which we personally resonate. Until better controlled research is conducted and more credible evidence presented, however, the possibility must remain just that—see also Winner and Hetland’s (1999) critical comments on this research, as well as the recent empirical studies by Steele, Bass, and Crook (1999) and by Nantais and Schellenberg (1999).
In both our graduate and undergraduate educational psychology courses, we draw heavily from research, argument, and critical thinking concepts presented in three wonderfully wise and well-crafted books, How to Think Straight about Psychology (Stanovich, 1998), Statistics as Principled Argument (Abelson, 1995), and Thought and Knowledge: An Introduction to Critical Thinking (Halpern, 1996). Anyone who has not read these beauties should. And anyone who has read them and applied the principles therein to their own research should more than appreciate the role played by oldfashioned evidence in offering and supporting an argument, whether that argument is in a research context or in an everyday thinking context. In a research context, a major theme of all three books—as well as of the Clinical Psychology and School Psychology Task Forces—is the essentiality of providing solid (our “credible”) evidence to support conclusions about causal connections between independent and dependent variables. In terms of our present intervention research context and terminology, before one can attribute an educational outcome to an educational intervention, credible evidence must be provided that rules in the intervention as the proximate cause of the observed outcome, while at the same time ruling out alternative accounts for the observed outcome.
If all of this sounds too stiff and formal (i.e., too academic), and maybe even too outmoded (Donmoyer, 1993; Mayer, 1993), let us restate it in terms of the down-to-earth advice offered to graduating seniors in a 1998 university commencement address given by Elizabeth Loftus, an expert on eyewitness testimony and then president of the American Psychological Society:
There’s a wonderful cartoon that appeared recently in Parade Magazine. . . . Picture this: mother and little son are sitting at the kitchen table. Apparently mom has just chided son for his excessive curiosity. The boy rises up and barks back, “Curiosity killed what cat? What was it curious about? What color was it? Did it have a name? How old was it?” I particularly like that last question. . . . [M]aybe the cat was very old, and died of old age, and curiosity had nothing to do with it at all. . . . [M]y pick for the one advice morsel is simple: remember to ask the questions that good psychological scientists have learned to ask: “What’s the evidence?” and then, “What EXACTLY is the evidence?” (Loftus, 1998, p. 27)
Loftus (1998, p. 3) added that one of the most important gifts of critical thinking is “knowing how to ask the right questions about any claim that someone might try to foist upon you.” In that regard, scientific research “is based on a fundamental insight—that the degree to which an idea seems true has nothing to do with whether it is true, and the way to distinguish factual ideas from false ones is to test them by experiment” (Loftus, 1998, p. 3). Similarly, in a recent popular press interview (Uchitelle, 1999), economist Alan Krueger argued for continually challenging conventional wisdom and theory with data: “The strength of a researcher is not in being an advocate, but in making scientific judgments based on the evidence. And empirical research teaches us that nothing is known with certainty” (p. C10). Stanovich (1998), in advancing his fanciful proposition that two “little green men” that reside in the brain control all human functioning, analogizes in relation to other fascinating, though scientifically unsupported, phenomena such as extrasensory perception, biorhythms, psychic surgery, facilitated communication, and so on, that “one of the most difficult things in the world [is to] confront a strongly held belief with contradictory evidence” (p. 29).
That intervention researchers are also prone to prolonged states of “evidencelessness” has been acknowledged for some time, as indicated in the following 40-year-old observation:
A great revolution in social science has been taking place, particularly throughout the last decade or two. Many educational researchers are inadequately trained either to recognize it or to implement it. It is the revolution in the concept of evidence. (Scriven, 1960, p. 426)
We contend that the revolution referred to by Scriven has not produced a corresponding revelation in the field of intervention research even (or especially) today. Consider, for example, the recent thoughts of the mathematics educator Thomas Romberg (1992) on the matter:
The importance of having quality evidence cannot be overemphasized. . . . The primary role of researchers is to provide reliability evidence to back up claims. Too many people are inclined to accept any evidence or statements that are first presented to them urgently, clearly, and repeatedly. . . . Aresearcher tries to be one whose claims of knowing go beyond a mere opinion, guess, or flight of fancy, to responsible claims with sufficient grounds for affirmation. . . . Unfortunately, as any journal editor can testify, there are too many research studies in education in which either the validity or the reliability of the evidence is questionable. (Romberg, 1992, pp. 58–59)
In the pages that follow, we hope to provide evidence to support Scriven’s (1960) and Romberg’s (1992) assertions about the noticeable lacks of evidence in contemporary intervention research.
The Evidence of Intervention Research
The ESP Model
Lamentably, in much intervention research today, rather than subscribing to the scientific method’s principles of theory, hypothesis-prediction, systematic manipulation, observation, analysis, and interpretation, more and more investigators are subscribing to what might be dubbed the ESP principles of Examine, Select, and Prescribe. For example, a researcher may decide to examine a reading intervention. The researcher may not have well-defined notions about the specific external (instructional) and internal (psychological) processes involved or about how they may contribute to a student’s performance. Based on his or her (typically, unsystematic) observations, the researcher selects certain instances of certain behaviors of certain students for (typically, in-depth) scrutiny. The researcher then goes on to prescribe certain instructional procedures, materials and methods, or smallgroup instructional strategies that follow from the scrutiny.
We have no problem with the examine phase of such research, and possibly not even with the select phase of it, insofar as all data collection and observation involve selection of one kind or another. We do, however, have a problem if this type of research is not properly regarded for what it is: namely, preliminary-exploratory, observational hypothesis generating. Certainly in the early stages of inquiry into a research topic, one has to look before one can leap into designing interventions, making predictions, or testing hypotheses. To demonstrate the possibility of relationships among variables, one might also select examples of consistent cases. Doing so, however, (a) does not comprise sufficient evidence to document the existence of a relationship (see, e.g., Derry et al., 2000) and (b) can result in unjustified interpretations of the kind that Brown (1992, pp. 162–163) attributed to Bartlett (1932) in his classic study of misremembering. With regard to the perils of case selection in classroom-intervention research, Brown (1992) properly noted that
there is a tendency to romanticize research of this nature and rest claims of success on a few engaging anecdotes or particularly exciting transcripts. One of the major methodological problems is to establish means of conveying not only the selective and not necessarily representative, but also the more important general, reliable, and repeatable. (p. 173)
In the ESP model, departure from the researcher’s originally intended purposes of the work (i.e., examining a particular instance or situation) is often forgotten, and prescriptions for practice are made with the same degree of excitement and conviction as are those based on investigations with credible, robust evidence. The unacceptability of the prescribe phase of the ESP research model goes without saying: Neither variable relationships nor instructional recommendations logically follow from its application. The widespread use of ESP methodology in intervention research and especially in education was appropriately admonished 35 years ago by Carl Bereiter in his compelling case for more empirical studies of the “strong inference” variety (Platt, 1964) in our field:
Why has the empirical research that has been done amounted to so little? One reason . . . is that most of it has been merely descriptive in nature. It has been a sort of glorified “people-watching,” concerned with quantifying the characteristics of this or that species of educational bird. . . . [T]he yield from this kind of research gets lower year by year in spite of the fact that the amount of research increases. (Bereiter, 1965, p. 96)
Although the research names have changed, the problems identified by Bereiter remain, and ESP methodology based on modern constructs flourishes.
The Art of Intervention Research: Examples From Education
If many intervention research interpretations and prescriptions are not based on evidence, then on what are they based? On existing beliefs? On opinion? Any semblance of a model of research yielding credible evidence has degenerated into a mode of research that yields everything but. We submit as a striking example the 1993 American Education Research Association (AERA) meeting in Atlanta, Georgia. At this meeting of the premier research organization of our educators, the most promising new developments in educational research were being showcased. Robert Donmoyer, the meeting organizer, wanted to alert the world to the nature of those groundbreaking research developments in his final preconference column in the Educational Researcher (the most widely distributed research-and-news publication of AERA):
Probably the most radical departures from the status quo can be found in sessions directly addressing this year’s theme, The Art and Science of Educational Research and Practice. In some of these sessions, the notion of art is much more than a metaphor. [One session], for example, features a theater piece constructed from students’ journal responses to feminist theory; [another] session uses movement and dance to represent gender relationships in educational discourse; and [another] session features a demonstration—completewithaviolinandpianoperformance— of the results of a mathematician and an educator’s interdisciplinary explorations of how music could be used to teach mathematics. (Donmoyer, 1993, p. 41)
Such sessions may be entertaining or engaging, but are they presenting what individuals attending a conference of a professional research organization came to hear? The next year, in a session at the 1994 AERA annual meeting in New Orleans, two researchers were displaying their wares in a joint presentation: Researcher A read a poem about Researcher B engaged in a professional activity; Researcher B displayed a painting of Researcher A similarly engaged. (The details presented here are intentionally sketchy to preserve anonymity.) Artistic? Yes, but is it research? Imagine the following dialogue: “Should the Food and Drug Administration approve the new experimental drug for national distribution?” “Definitely! Its effectiveness has been documented in a poem by one satisfied consumer and in a painting by another.”
These perceptions of a scientific backlash within the research community may pertain not just to scientifically based research, but to science itself. In their book The Flight From Science and Reason, Gross, Levitt, and Lewis (1997) included 42 essays on the erosion of valuing rationalism in society. Among the topics addressed in these essays are the attacks on physics, medicine, the influence of the arguments against objectivity in the humanities, and questions about the scientific basis of the social sciences. Thus, the rejection of scientifically based knowledge in education is part of a larger societal concern. Some 30 years after making his case for strong-inference research in education (Bereiter, 1965), Carl Bereiter (1994) wrote the following in a critique of the current wave of postmodernism thought among researchers and educators alike:
This demotion of science to a mere cognitive style might be dismissed as a silly notion with little likelihood of impact on mainstream educational thought, but I have begun to note the following milder symptoms in otherwise thoroughly mainstream science educators: reluctance to call anything a fact; avoidance of the term misconception (which only a few years ago was a favorite word for some of the same people); considerable agonizing over teaching the scientific method and over what might conceivably take its place; and a tendency to preface the word science with Eurocentric, especially among graduate students. (Bereiter, 1994, p. 3)
What is going on here? Is it any wonder that scholars from other disciplines, politicians, and just plain folks are looking at educational research askew?
Labaree (1998) clearly recognized the issue of concern:
Unfortunately, the newly relaxed philosophical position toward the softness of educational knowledge . . . can (and frequently does) lead to rather cavalier attitudes by educational researchers toward [a lack of] methodological rigor in their work. As confirmation, all one has to do is read a cross-section of dissertations in the field or of papers presented at educational conferences. For many educational researchers, apparently, the successful attack on the validity of the hard sciences in recent years has led to the position that softness is not a problem to be dealt with but a virtue to be celebrated. Frequently, the result is that qualitative methods are treated less as a cluster of alternative methodologies than as a license to say what one wants without regard to rules of evidence or forms of validation. (Labaree, 1998, p. 11)
In addition to our having witnessed an explosion of presentations of the ESP, anecdotal, and opinion variety at the “nouveau research” AERA conferences (including presentations that propose and prescribe instructional interventions), we can see those modes of inquiry increasingly being welcomed into the academic educational research community— and even into journals that include “research” as part of their title:
When I first began presiding over the manuscript review process for Educational Researcher, for example, I received an essay from a teacher reflecting on her practice. My initial impulse was to reject the piece without review because the literary genre of the personal essay in general and personal essays by teachers in particular are not normally published in research journals. I quickly reconsidered this decision, however, and sent the paper to four reviewers with a special cover letter that said, among other things: “. . . The Educational Researcher has published pieces about practitioner narratives; it makes sense, therefore, to consider publishing narrative work . . . I will not cavalierly reject practitioners’narratives and reflective essays.” . . . [I]n my cover letter, I did not explicitly invite reviewers to challenge my judgment (implicit in my decision to send work of this kind out for review) that the kind of work the manuscript represented—if it is of high quality—merits publication in a research journal. In fact, my cover letter suggested this issue had already been decided. (Donmoyer, 1996, pp. 22–23)
We do not disregard the potential value of a teacher’s reflection on experience. But is it research? On what type of research-based evidence is it based? We can anticipate the reader dismissing Donmoyer’s (1996) comments by arguing that the Educational Researcher is not really a scholarly research journal, at least not exclusively so. It does, after all, also serve a newsletter function for AERA. In fact, in the organization’s formative years (i.e., in the 1940s, 1950s, and 1960s) it used to be just that, a newsletter. Yet, in Donmoyer’s editorial, he was referring to the Features section, a researchbased section of the Educational Researcher, and he clearly regarded the contents of that section, along with the manuscripts suitable for it, in scholarly research terms. What is not research may soon be difficult, if not impossible, to define. In the 1999 AERA meeting session on research training, there was no clear definition of what research is.
Additional Forms of Contemporary Intervention Research Evidence
In this section we single out for critical examination three other methods of empirical inquiry, along with their resulting forms of evidence, which are thriving in psychological and educational intervention research today. These are the case study, the demonstration study, and the design experiment.
The Case Study
Case study research—consisting of the intensive (typically longitudinal) study and documentation of an individual’s “problem” of interest, along with the (typically unsystematic) introduction of various intervention agents designed to address the problem—is not a new methodology in psychology and education. Examples can be observed throughout the history of these disciplines. Although limitations of the case study have been known for some time (see Kazdin, 1981; Kratochwill, 1985), it continues to flourish in intervention research. It is not the use of case study research that is problematic, but rather the claims and generalizations for practice that result from this methodology. An illustration of its application in research on treatment of children’s disorders will alert the reader to case study concerns.
Considerable research has been conducted focusing on the treatment of posttraumatic stress disorder (PTSD) in adults, but treatment of children has not been as extensive. Nevertheless, children are very likely to experience PTSD; the disorder can be diagnosed in young children and needs to be treated. Although several treatments might be considered, eye movement desensitization and reprocessing (EMDR) therapy (Cocco & Sharp, 1993) seems to be getting increased attention as a particularly effective treatment for stressrelated problems in children (see Greenwald, 1999). But does EMDR qualify as an evidence-based treatment of PTSD in children? In a recent review of research in that area (Saigh, in press), only one study could be found that offered empirical support for this form of therapy.
EMDR typically involves asking the person to imagine a traumatic experience while at the same time visually tracking the finger movements of the psychologist. While this activity is going on, the child may be instructed to state negative and positive statements about him- or herself, with an emphasis on coping. In a case study in this area, Cocco and Sharpe (1993) used a variant of EMDR through an auditory procedure for treatment of a 4-year, 9-month-old child who was assaulted. Following the assault, the child was reported to experience nightmares, bed-wetting, carrying a toy gun, and sleeping in his parents’bed. During the therapy the child was told to imagine the event and track the therapist’s finger movements. In addition, the child was asked to draw a picture of the assailants and a picture of a superhero for the treatment sessions. An auditory procedure was used in which the therapist clicked his finger at the rate of 4 clicks per second for 12 s. At the same time, the child was asked to look at the picture he had drawn and then to verbalize what the hero was doing to the assailants as the therapist clicked his fingers. It was reported that the child stabbed the picture while verbalizing that he was killing the assailants. The treatment was considered successful in that the child no longer experienced nightmares, no longer wet his bed, and did not need to sleep with his parents or carry a toy gun. At a six-month follow-up, however, the child was reported to wet the bed and sleep in his parents’ bed.
Tab. 22.2
What can be concluded from this case study? In our opinion, very little, if anything. In fact, the desperate clinician looking for an effective treatment might be misled into assuming that EMDR is an effective procedure for this childhood disorder when, in fact, more tightly controlled and replicated (i.e., CAREful) research would suggest effective alternatives. Among the variety of treatment procedures available for children experiencing PTSD, behavior-therapy techniques have emerged as among the most successful, based on clinical research (Saigh, Yasik, Oberfield, & Inamdar, 1999). In particular, flooding therapy, a procedure investigated in a series of controlled single-participant research studies with replication of findings across independent participants (e.g., Saigh, 1987a, 1987b, 1987c, 1989), has emerged as an effective treatment for this serious disorder.
Again, our negative view of case studies is related to the generalizations that are often made for practice. Within a proper context, case-study research may be useful in generating hypotheses for future well-controlled investigations (Kratochwill, Mott, & Dodson, 1984). Moreover, not all case studies are alike on methodological dimensions, and the researcher using these methods has available options for improving the inference that can be drawn from such studies. Table 22.2 shows some of the methodological features that suggest levels of inference (varying from high to low) that can be applied to both design of case studies and interpretation of data from these investigations (see also Kazdin, 1998). Nevertheless, case studies fall into the “demonstration study” category (to be discussed next) and differ from another oftenconfused “single case” design, the systematically implemented and controlled single-participant study, in which replication and (in many instances) intervention randomization are central features (see Kratochwill & Levin, 1992).

The Demonstration Study
Two ubiquitous examples of demonstration studies in educational contexts include (a) an instructional intervention that is introduced within a particular classroom (with or without a nonintervention comparison classroom) and (b) an out-of-classroom special intervention program that is provided to a selected group of students. The critical issue here (which will be revisited shortly) is that with only one classroom receiving special instruction or only one group participating in a special program, it is not possible to separate the effects of the intervention or the program from the specific implementation of it.
Levin and Levin (1993) discussed interpretive concerns associated with the evidence derived from a demonstration study in the context of evaluating the outcomes of an academic retention program. They are encompassed in three CAREful-component questions rolled into one: Was the program effective?With an emphasis on “effective,” one can ask, “Relative to what?” for in many program evaluation studies frequently lacking is an appropriate Comparison (either with comparable nonprogram students or with participants’ preprogram data). With an emphasis on “the,” one can ask, “Do you mean this single implementation of the program?” for generalization to other program cohorts or sites is not possible without an Again and again replication component. Finally, with an emphasis on “program,” one can ask, “Can other, nonprogram-related, factors account for the observed outcomes?” for without program randomization and control, one cannot readily Eliminate other potential contributors to the effects. Levin, Levin, and Scalia’s (1997) report of a college retention program for academically at-risk minority students provides an example of a demonstration study. Like our previous case study example, because of the uncontrolled nature of the study and the one-time implementation of the program, any of the documented positive outcomes associated with program participants cannot be regarded as either scientifically credible or generalizable to other implementations of the program. In that sense, then, and as Levin et al. (1997, pp. 86–87) pointed out, a report of their particular program and its outcomes can indicate only what happened under a unique and favorable set of circumstances. It clearly is not an indication of what to expect if a similar program were to be implemented by others with other college students elsewhere.
The Design Experiment
Also considered here is the classroom-based design experiment, originally popularized by Collins (1992) and by Brown (1992) and welcomed into the educational research community by Salomon (1995, p. 107) and by various researchfunding agencies (e.g., Suter, 1999). In design experiments research is conducted in authentic contexts (e.g., in actual classrooms, in collaboration with teachers and other school personnel), and the experiment is not fixed in the traditional sense; rather, instructional-design modifications are made as desired or needed.
On closer inspection, one discovers that from a strict terminological standpoint, design experiments neither have a design nor are experiments. In particular, in conventional research usage, design refers to a set of pre-experimental plans concerning the specific conditions, methods, and materials to be incorporated in the study. In a design experiment, however, any components may be altered by the researcher or teacher as the investigation unfolds, as part of “flexible design revision” (Collins, 1992): “It may often be the case that the teacher or researchers feel a particular design is not working early in the school year. It is important to analyze why it is not working and take steps to fix whatever appears to be the reason for failure” (p. 18).
Similarly, in conventional research terminology, experiment refers to situations in which participants are randomly assigned to the two or more systematically manipulated and controlled conditions of a study (e.g., Campbell & Stanley, 1966). In a design experiment, however (and as will be expanded upon shortly), appropriate randomization and control are conspicuously absent, which, in turn, does not permit a credible attribution of outcomes to the intervention procedures under investigation. Take, for example, Collins’s (1992) description of a hypothetical design experiment (with numbers in square brackets added for identification in the subsequent paragraph):
Our first step would be to observe a number of teachers, and to choose two who are interested in trying out technology to teach students about the seasons, and who are comparably effective [1], but use different styles of teaching: for example, one might work with activity centers in the classroom and the other with the entire class at one time [2]. Ideally, the teachers should have comparable populations of students [3]. . . .Assuming both teachers teach a number of classes, we would ask each to teach half her classes using the design we have developed [4]. In the other classes, we would help the teacher design her own unit on the seasons using these various technologies [5], one that is carefully crafted to fit with her normal teaching style [6]. (Collins, 1992, p. 19).
From this description, it can be seen that in a design experiment there are numerous plausible alternative explanations for the observed outcomes that compete with the intervention manipulation of interest. Consider the following components of Collins’ hypothetical study:
Regarding [1], how can “comparably effective” teachers be identified, let alone defined? In [2], teachers differing in “teaching style” differ in countless other ways as well; one, for example, might have brown hair and the other gray, which could actually be an age or years-of-experience proxy. Regarding [3], again, how are student populations “comparable,” and how are they defined to be so? For [4] through [6], assuming that the two teachers could both teach their respective classes in precisely the prescribed manner (a tall assumption for a within-teacher instructional manipulation of this kind) and that individualized teacher-style “crafting” could be accomplished (another tall assumption), any result of such a study would represent a confounding of the intervention manipulation and specific teacher characteristics (as alluded to in [2]), so nothing would be learned about the effects of the instructional manipulations per se. Even worse, in the rest of Collins’s (1992, p. 19) example, the described instructional manipulation contains no less than seven sequentially introduced technology components. Consequently, even if teacher effects could be eliminated or accounted for, one would still have no idea what it was about the intervention manipulation that produced any outcome differences. Was it, for example, that students became more engaged by working on the computer, more attuned to measurement and data properties and accuracy by collecting information and entering it into a spreadsheet, more self-confident by interacting with students from other locations, more proficient writers through book production, and so on? There is no way of telling, and telling is something that a researcher-as-intervention-prescriber should want, and be able, to do.
The design experiment certainly has its pros and cons. Those who regard intervention research’s sole purpose as improving practice also often regard research conducted in laboratory settings as decontextualized and irrelevant to natural contexts (see Kazdin, 1998). In contrast, the design experiment is, by definition, classroom based and classroom targeted. On the other side of the ledger, design experiments can be criticized on methodological grounds, as well as on the basis of design experimenters’ potential to subordinate valuable classroom-instructional time to the (typically lengthy and incompletely defined) research agenda on the table. In our view, design experiments can play an informative role in preliminary stages of intervention research as long as the design experimenter remembers that the research was designed to be “preliminary” when reporting and speculating about a given study’s findings. For a true personal anecdote of how researchers sometimes take studies of this kind and attempt to sneak them “through the back door” (Stanovich, 1999) into credible-research journals, see Levin and O’Donnell (2000).
In fact, design experiments and other informal classroombased studies are incorporated into the model of intervention research that we propose in a later section. On a related note, we heartily endorse Brown’s (1992, pp. 153–154) research strategy of ping-ponging back and forth between classroombased investigations and controlled laboratory experiments as a “cross-fertilization between settings” (p. 153) for developing and refining contextually valid instructional theories (see also Kratochwill & Stoiber, 2000, for a similar view of research in school psychology). The reader must again be reminded, however, that scientifically credible operations (chiefly, randomization and control) are not an integral part of a design experiment, at least not as Collins (1992) and Brown (1992) have conceptualized it.
Summary
For much intervention research as it is increasingly being practiced today, we are witnessing a movement away from CAREful research principles, and even away from preliminary research models principally couched in selected observations and questionable prescriptions. Rejection of the scientific method and quantitative assessment may be leading to inadequate graduate training in rigorous research skills that are valued by many academic institutions and funding agencies. At the same time, it should not be forgotten that even qualitatively oriented researchers are capable of engaging in mindless mining of their data as well. Vanessa Siddle Walker (1999) recently distinguished between data and good data, which, in our current terminology, translates as, “Not all evidence is equally credible.”
Just as in other fields informed by bona fide empirical inquiry, in psychology and education we must be vigilant in dismissing “fantasy, unfounded opinion, ‘common sense,’ commercial advertising claims, the advice of ‘gurus,’testimonials, and wishful thinking in [our] search for the truth” (Stanovich,1998,p.206).Casestudies,demonstrationstudies, and design experiments have their place in the developmental stages of intervention research, as long as the researchers view such efforts as preliminary and adopt a prescriptionwithholding stance when reporting the associated outcomes. We cannot imagine, for example, well-informed researchers and consumers taking seriously instructional prescriptions from someone who proudly proclaims: “Let me tell you about the design experiment that I just conducted. . . .”
In the next section we offer some additional reflections on the character of contemporary intervention research. In so doing, we provide suggestions for enhancing the scientific integrity of intervention research training and the conduct of intervention research.
Enhancing the Credibility of Intervention Research
Psychological/Educational Research Versus Medical Research
Very high standards have been invoked for intervention outcome research in medicine. The evidence-based intervention movement was initiated in medical research in the United Kingdom and embraced more recently by clinical psychology (Chambless & Ollendick, 2001).An editorial in the New England Journal of Medicine spelled out in very clear and certain terms the unacceptability of admitting anecdotes, personal testimony, and uncontrolled observations when evaluating the effectiveness of a new drug or medical treatment:
If, for example, the Journal were to receive a paper describing a patient’s recovery from cancer of the pancreas after he had ingested a rhubarb diet, we would require documentation of the disease and its extent, we would ask about other, similar patients who did not recover after eating rhubarb, and we might suggest trying the diet on other patients. If the answers to these and other questions were satisfactory, we might publish a case report—not to announce a remedy, but only to suggest a hypothesis that should be tested in a proper clinical trial. In contrast, anecdotes about alternative remedies (usually published in books and magazines for the public) have no such documentation and are considered sufficient in themselves as support for therapeutic claims. Alternative medicine also distinguishes itself by an ideology that largely ignores biologic mechanisms, often disparages modern science, and relies on what are purported to be ancient practices and natural remedies. . . . [H]ealing methods such as homeopathy and therapeutic touch are fervently promoted despite not only the lack of good clinical evidence of effectiveness, but the presence of a rationale that violates fundamental scientific laws—surely a circumstance that requires more, rather than less, evidence. (Angell & Kassirer, 1998, p. 839)
Angell and Kassirer (1998) called for scientifically based evidence, not intuition, superstition, belief, or opinion. Many would argue that psychological research and educational intervention research are not medical research and that the former represents an inappropriate analog model for the latter.Wedisagree. Both medical research and psychological/educational research involve interventions in complex systems in which it is difficult to map out causal relationships. Reread the Angell and Kassirer (1998) excerpt, for example, substituting such words as “child” or “student” for “patient,” “amelioration of a conduct disorder or reading disability” for “recovery from cancer of the pancreas,” “ingested a rhubarb diet” for “ingested a rhubarb diet,” and so on. Just as medical research seeks prescriptions, so does psychological and educational research; and prescription seeking should be accompanied by scientifically credible evidence to support those prescriptions (see, e.g., the recent report of the National Research Council, 2001). Furthermore, as former AERA president Michael Scriven poignantly queried in his contemplation of the future of educational research, “Why is [scientifically credible methodology] good enough for medical research but not good enough for educational research? Is aspirin no longer working?” (Scriven, 1997, p. 21).
Moreover, the kinds of researchable questions, issues, and concerns being addressed in the medical and psychological/ educational domains are clearly analogous: Is one medical (educational) treatment better than another? Just as aspirin may have different benefits or risks for different consumers, so may an instructional treatment. And just as new medical research evidence may prove conventional wisdom or traditional treatments incorrect (e.g., Hooper, 1999), the same is true of educational research evidence (e.g., U.S. Department of Education, 1986; Wong, 1995). Citing the absence, to date, of research breakthroughs in psychology and education (in contrast to those that can be enumerated in medicine) is, in our view, insufficient cause to reject the analogy out of hand.
It is possible that many people’s initial rejection of the medical model of research as an apt analogue for psychological/educational research results from their incomplete understanding of what constitutes medical research. In the development of new drugs, clinical trials with humans proceed through three phases (NIH, 1998). In Phase I clinical trials research is conducted to determine the best delivery methods and safe dosage levels (including an examination of unwanted side effects) of a drug. Phase II clinical trials address the question of whether the drug produces a desired effect. Phase III trials compare the effects of the new drug against the existing standards in the context of carefully controlled randomized experiments. Thus, although medical research includes various forms of empirical inquiry, it culminates in a randomized comparison of the new drug with one or more alternatives to determine if, in fact, something new or better is being accomplished (see, e.g., the criteria from the Clinical Psychology Task Force for a similar view). A recent example of this work is the evaluation of the effects of Prozac on depressionincomparisontootherantidepressants.Thephasesof clinical trials described here roughly parallel the stages in the model of educational research that we now propose.
A Stage Model of Educational/Psychological Intervention Research
Our vision of how to close one of intervention research’s undamental credibility gaps, while at the same time better informing practice, is presented in Figure 22.1’s stage model of educational/psychological intervention research. In contrast to currently popular modes of intervention-research inquiry and reporting, the present conceptualization (a) makes explicit different research stages, each of which is associated with its own assumptions, purposes, methodologies, and standards of evidence; (b) concerns itself with research credibility through high standards of internal validity; (c) concerns itself with research creditability through high standards of external validity and educational/societal importance; and, most significantly, (d) includes a critical stage that has heretofore been missing in the vast majority of intervention research, namely, a randomized classroom trials link (modeled after the clinical trials stage of medical research) between the initial development and limited testing of the intervention and the prescription and implementation of it. Alternatively, Stage 3 could be referred to as an instructional trials stage or, more generically, as an educational trials stage. To simplify matters, for the remainder of the paper we continue to refer to Stage 3 as the randomized classroom trials stage of credible intervention research studies.
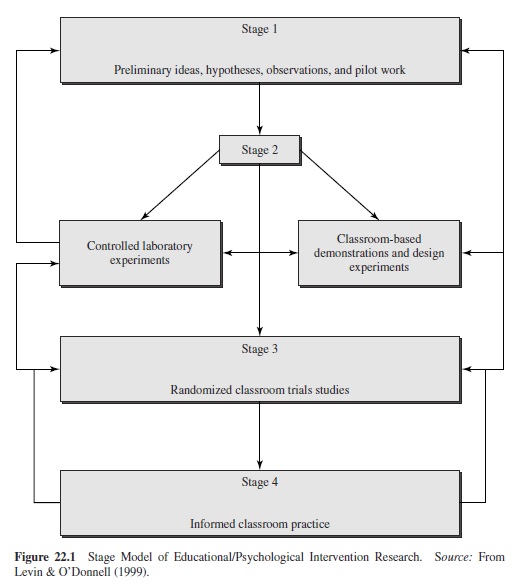
Stages 1 and 2 of the Figure 22.1 model are likely very familiar to readers of this research paper, as studies in those traditions comprise the vast majority of intervention research as we know it. In addition, throughout the paper we have provided details of the two Stage 2 components of the model in our consideration of the research-first (controlled laboratory experiments) versus practice-first (case studies, demonstrations, and design experiments) perspectives. Both controlled laboratory experiments and applied studies are preliminary, though in different complementary senses. The former are preliminary in that their careful scrutiny of interventions lacks an applied-implementation component, whereas the latter are preliminary in that their intervention prescriptions are often not founded on scientifically credible evidence. Stage 1 and Stage 2 studies are crucial to developing an understanding of the phenomena that inform practice (Stage 4) but that first must be rigorously, complexly, and intelligently evaluated in Stage 3. Failure to consider possibilities beyond Stages 1 and 2 may result in a purposelessness to research, a temptation never to go beyond understanding a phenomenon and determining whether it is a stable phenomenon with genuine practice implications. The accumulation of applied, scientifically credible evidence is precisely the function of the randomized classroom trials stage (Stage 3, highlighted in Figure 22.1) of the model. As in medical research, this process consists of an examination of the proposed treatment or intervention under realistic, yet carefully controlled, conditions (e.g., Angell & Kassirer, 1998).
“Realistic conditions” refer to the specific populations and contexts about which one wishes to offer conclusions regarding treatment efficacy (i.e., external validity desiderata). In medical research the conditions of interest generally include humans (rather than animals), whereas in psychological and educational research the conditions of interest generally include children in community settings and school classrooms (rather than isolated individuals). In addition, in both medical and psychological/educational contexts, the interventions (e.g., drugs or instructional methods, respectively) must be administered in the appropriate fashion (dosage levels or instructional integrity, respectively) for a long enough duration for them to have effect and to permit the assessment of both the desired outcome (e.g., an improved physical or socialacademic condition, respectively) and any unwanted side effects (adverse physical, cognitive, affective, or behavioral consequences). In a classroom situation, an appropriately implemented instructional intervention of at least one semester, or even one year, in duration would be expected to satisfy the “long enough” criterion.
“Carefully controlled conditions” refer to internally valid experiments based on the random assignment of multiple independent “units” to alternative treatment-intervention conditions. Again, in medical research the randomized independent units are typically humans, whereas in educational intervention research the randomized independent units are frequently groups, classrooms, or schools (Levin, 1992, 1994). As with medical research, careful control additionally involves design safeguards to help rule out contributors to the effects other than the targeted intervention, such as including appropriate alternative interventions, incorporating blind and doubleblind intervention implementations (to the extent possible) so that child, teacher, therapist, and researcher biases are eliminated, and being responsive to all other potential sources of experimental internal invalidity (Campbell & Stanley, 1966; Shadish, Cook, & Campbell, 2002).
The randomized classroom trials stage of this model is sensitive to each of the earlier indicated CAREful research components, in that (a) the inclusion of alternative interventions (including appropriately packaged standard methods or placebos) permits meaningful Comparison when assessing the effects of the targeted intervention; (b) the use of multiple independent units (both within a single study and, ideally, as subsequent replication studies) permits generalization through the specified outcomes being produced Again and again; and (c) with across-unit randomization of interventions (and assuming adequate control and appropriate implementation of them), whatever Relationship is found between the targeted intervention and the specified outcomes can be traced directly to the intervention because (d) with such randomization, control, and implementation, one is better able to Eliminate all other potential explanations for the outcomes.
The randomized classroom trials stage of our proposed model possesses a number of critical features that are worth mentioning. These features represent the best of what CAREfully controlled and well-executed laboratory-based research has to offer applied and clinical research. First and foremost here is the inclusion of multiple units (or in single-participant research designs, multiple phases and within-phase observations per unit; see, e.g., Kratochwill & Levin, 1992) that are randomly assigned to receive either the targeted intervention or an acceptable alternative. For example, when classrooms are the units of analysis, the use of multiple independent classrooms is imperative for combating evidence-credibility concerns arising from both methodological and statistical features of the research. Each of these will be briefly considered here (for additional discussion, see Campbell & Boruch, 1975; Levin, 1985, 1992, 1994; Levin & Levin, 1993).
Methodological Rigor
Consider some examples from educational research to contextualize our perspectives on methodological rigor. In a typical instructional intervention study, the participants in one classroom receive new instructional methods or materials (including combinations of these, multicomponent versions, and systemic curricular innovations), whereas those in another classroom receive either alternative or standard instructional methods/materials/curricula. One does not have to look very hard to find examples of this type of study in the intervention research literature, as it is pervasive. The aforementioned Graziano et al. (1999) training study is an example of this methodological genre. The problem with such studies is that any resultant claims about intervention-produced outcomes are not credible because whatever effects are observed can be plausibly attributed to a myriad of other factors not at all connected with the intervention. In studies where there is only one classroom/teacher per intervention, for example, any potential intervention effects are inextricably confounded with classroom/teacher differences—even if “equivalence” can be demonstrated on a pretest. If students are not randomly assigned to classrooms and classrooms to interventions, intervention effects are confounded with selection biases as well. Indeed, as far as credible evidence is concerned, a reasonable case can be made that a “one classroom per intervention” study is just that—an individual case. Accordingly, one-classroomper-intervention cases fall into our earlier discussion of intervention research that in actuality is a classroom-based demonstration.
With the addition of sequential modifications of the instructional intervention, the previously discussed design experiment also resembles the one-classroom-per-intervention prototype.Minorvariationsofthatprototypeincludeassigning a couple classrooms to each intervention condition (e.g., Brown, 1992) or having one or a few teachers alternately implement both interventions in a few classrooms (e.g., Collins, 1992). Unfortunately, methodological and statistical concerns (related to nonrandomization; contaminating teacher, student, classroom, and researcher effects; and inappropriate units of analysis, among others), analogous to the ones raised here, are associated with such variations as well. Recent methodological and statistical developments out of the behavior-analytic and clinical research traditions do, however, have the potential to enhance the scientific credibility of the oneor-few-classrooms-per-intervention study (e.g., Koehler & Levin, 1998; Kratochwill & Levin, 1992; Levin & Wampold, 1999) and, therefore, should be given strong consideration in classroom-based and other intervention studies.
Unfortunately, adding the sequential intervention-modification strategy of design experiments serves only to add confounding variables to the interpretive mix.Although some may regard confounding the effect of an intervention with other variables to be acceptable in a design experiment—“Our interventions are deliberately designed to be multiply confounded” (Brown, 1992, p. 167)—confoundings of the kind described here clearly are not acceptable in the classroom trials stage of educational intervention research. In Stage 3 of the model, the random assignment of multiple classrooms or other intact groups to interventions serves to counteract this methodological concern; for actual research examples, see Byrne and Fielding-Barnsley (1991); Duffy et al. (1987); and Stevens, Slavin, and Farnish (1991).
Consistent with the earlier presented Comparison component of CAREful research, the need for including appropriate comparison classrooms (or other aggregates) is of paramount importance in the Stage 3 model. As Slavin (1999) forcefully pointed out in response to a critic advocating the documentation of an intervention’s effectiveness not by a comparison with a nonintervention control condition but through the presentation of what seem to be surprising outcomes in the intervention condition,
An experimental-control comparison between well-matched (or, ideally, randomly assigned) participants is to be able to provide powerful evidence for or against a causal relationship [attributable to the intervention], because the researcher establishes the experimental and control groups in advance, before the results are known, and then reports relative posttests or gains. In contrast, [the critic’s] search for “surprising” scores or gains begins after the fact, when the results are already known. This cannot establish the effect of a given program on a given outcome; any of a thousand other factors other than the treatment could explain high scores in a given school in a given year. . . . If an evaluation has data on 100 schools implementing a given program but only reports on the 50 that produced the most positive scores, it is utterly meaningless. In contrast, a comparison of 10 schools to 10 well-matched control schools provides strong evidence for or against the existence of a program impact. If that experimental-control comparison is then replicated elsewhere in a series of small but unbiased studies, the argument for a causal relationship is further strengthened. (Slavin, 1999, pp. 36–37)
Slavin’s hypothetical example should evoke readers’ memories of the perils and potential for deception that are inherent in the examine aspect of the ESP model of educational intervention research. The example also well illustrates the adapted adage: A randomized experiment is worth more than 100 school demonstrations!
Analytic Appropriateness
Early and often in the history of educational research, much has been written on the inappropriateness of researchers’statistically analyzing the effects of classroom-implemented interventions as though the interventions had been independently administered to individual students (e.g., Barcikowski, 1981; Levin, 1992; Lindquist, 1940; Page, 1965; Peckham, Glass, & Hopkins, 1969). That is, there is a profound mismatch between the units of intervention administration (groups, classrooms) and the units of analysis (children, students) and conducting child/student-level statistical analyses in such situations typically results in a serious misrepresentation of both the reality and the magnitude of the intervention effect. [As an interesting aside, units of analysis is another term with a specific statistical meaning that is now being casually used in the educational research literature to refer to the researcher’s substantive grain-size perspective: the individual student, the classroom collective, the school, the community, etc. (see, e.g., Cobb & Bowers, 1999, pp. 6–8).] Consider, for example, a hypothetical treatment study in which one classroom of 20 students receives a classroom management instructional intervention and another classroom of 20 students receives standard classroom protocol. It is indisputably incorrect to assess the intervention effect in that study on the basis of a conventional student-level t test, analysis of variance, chi-square test, or other statistical procedures that assume that 40 independently generated student outcomes comprise the data. Analyzing the data in that fashion will produce invalid results and conclusions.
Even today, most “one group per intervention” (or even “a couple groups per intervention”) researchers continue to adopt units-inappropriate analytic practices, in spite of the earlier noted cautions and evidence that such practices lead to dangerously misleading inferences (e.g., Graziano et al., 1999). In a related context, Muthen (1989, p. 184) speculated on the reason for researchers’ persistent misapplication of statistical procedures: “The common problem is that measurement issues and statistical assumptions that are incidental to the researchers’conceptual ideas become stumbling blocks that invalidate the statistical analysis.”
In the randomized classroom trials stage of the model, the critical units-of-analysis issue can be dealt with through the inclusion of multiple randomized units (e.g., multiple classrooms randomly assigned to intervention and control conditions) in conjunction with the application of statistical models that are both appropriate and sensitive to the applied implementation nature of the experiment (e.g., Bryk & Raudenbush, 1992; Levin, 1992). In the medical and health fields, group-randomized intervention trials (Braun & Feng, 2001) have been referred to as cluster randomization trials (e.g., Donner & Klar, 2000), with the corresponding pitfalls of inappropriate statistical analyses well documented. The number of multiple units to be included in a given study is not a specified constant. Rather, that number will vary from study to study as a function of substantive, resource, and unit-based statistical power considerations (e.g., Barcikowski, 1981; Levin, 1997a; Levin & Serlin, 1993), as well as of the scope of curricular policy implications associated with the particular intervention. In addition, appropriate statistical methods to accompany multiple-baseline and other “few units per intervention” single-participant designs (alluded to earlier) are now available (see, e.g., Koehler & Levin, 1998; Levin & Wampold, 1999; Marascuilo & Busk, 1988; Wampold & Worsham, 1986).
Two additional critical features of the randomized classroom trials stage should also be indicated.
Intervention-Effect Robustness
The use of multiple randomized units in the randomized classroom trials stage permits legitimate intervention-effect generalizations across classrooms, teachers, and students— something that is not legitimate in the prototypical intervention study. With the additional feature of random selection of groups or classrooms within a school, district, or other population, statistical analyses that permit even grander generalizations are possible (e.g., Bryk & Raudenbush, 1992), a desirable and defining characteristic of Slavin’s (1997) proposed design competition for instructional interventions. (A design competition should not be confused with a design experiment, as has already occurred in the literature. The critical attributes of the former have been discussed earlier in this article; those of the latter are discussed in a following section.) Finally, replication of the randomized classroom trials stage of the model, across different sites and with different investigators, increases one’s degree of confidence in the reality, magnitude, and robustness of the intervention effect. In summary, each of the just-mentioned sampling augmentations of the randomized classroom trials stage can be considered in relation to enhancing the research’s external validity.
Interaction Potential
The randomized classroom trials stage lends itself not just to generalization, but also to specificity, in the form of determining whether a particular intervention is better suited to certain kinds of groups, classrooms, teachers, or students than to others. With one-unit-per-intervention and conventional analyses, investigating intervention-by-characteristics interactions is not possible, or at least not possible without the methodological shortcomings and statistical assumption violations mentioned earlier. Just as different drugs or medical treatments may be expected to affect different patients differently, different classroom interventions likely have different effects on students differing in academic ability, aptitude, motivational levels, or demographic characteristics.The same would be expected of instructional interventions delivered by teachers with different personal and teaching characteristics. That is, one size may not fit all (Salomon & Almog, 1998, p. 224), but that assumption can readily be incorporated into, and investigated in, the randomized classroom trials stage of intervention research (e.g., Bryk & Raudenbush, 1992; Levin, 1992; Levin & Peterson, 1984); for an actual research example, see Copeland (1991). Included in this analytic armament areadaptationsforstudyinginterventionbyoutcome-measure interactions, changes in intervention effectiveness over time, and other large- or small-scale classroom-based multivariate issues of interest (see also Levin & Wampold, 1999).
What Is Random in Randomized Classroom Trials Studies?
It is important to clarify exactly what needs to be random and controlled to yield scientifically credible unit-based evidence, for we have witnessed substantial confusion among intervention researchers concerning how to meet standards of internal, as opposed to external, validity in such studies. Reiterating that high internal validity alone is what makes an empirical study scientifically credible, we point out that in randomized classroom trials research,
- Classrooms and teachers do not need to be randomly selected.
- Participants do not need to be randomly assigned to classrooms.
- The only aspect that must be random is the assignment of candidate units (e.g., groups, classrooms, schools) to the differentinterventionconditions,eitheracrossallunitsorin a matched-unit fashion. By “candidate,” we are referring to all units for which there is a priori agreement to be included in the study, which implies accepting the fact that there is an equal chance of the candidates’being assigned to any of the study’s specified intervention conditions. A “wait-list” or “crossover” arrangement (e.g., Levin, 1992; Shadish, Cook, & Campbell, 2002) can also be implemented as a part of the nontargeted-intervention units’assignment.
- Scientifically credible studies based on whole unit random assignment operations can be performed on targeted participant subgroups. For example, classrooms containing students both with and without learning disabilities could be randomly assigned to intervention conditions, with the focus of the study’s interventions being on just the former student subgroup.
- When either out-of-classroom or unobtrusive withinclassroom interventions can be administered, withinclassroom blocked random assignment of participants to intervention conditions represents a scientifically credible strategy—for an actual research example, see McDonald, Kratochwill, Levin, and Youngbear Tibbits (1998).
- Even if units are initially assigned to interventions randomly (as just indicated), terminal conditions-composition differences resulting from participant or group attrition can undermine the scientific credibility of the study (see, e.g., the Graziano et al., 1999, training study). In such cases, analyses representing different degrees of conservatism should be provided, with the hope of obtaining compatible evidence.
An important addendum is that statistical adjustments and controls (e.g., analysis of covariance, path models) do not represent acceptable substitutes for situations in which random assignment of classrooms to intervention conditions cannot be effected. Although this point has been underscored by statisticians and methodologists for many years (e.g., Elashoff, 1969; Huitema, 1980), educational researchers continue to believe that sophisticated statistical tools can resurrect data from studies that are inadequately designed and executed. Muthen (1989) aptly reminded us of that in quoting Cliff (1983):
[Various multivariate] methods have greatly increased the rigor with which one can analyze his correlational data, and they solve many statistical problems that have plagued this kind of data. However, they solve a much smaller proportion of the interpretational . . . problems that go with such data. These interpretational problems are particularly severe in those increasingly common cases where the investigator wishes to make causal interpretations of his analyses. (Muthen, 1989, p. 185)
When random assignment of units to interventions has been used, however, the concurrent application of analysis of covariance or other multivariate techniques is entirely appropriateandmayprovetobeanalyticallyadvantageous(e.g.,Levin & Serlin, 1993); for actual research examples, see Torgesen, Morgan, and Davis (1992) and Whitehurst et al. (1994).
Summary
Conducting randomized classroom trials studies is not an easy task. We nonetheless claim that: (a) randomized experiments are not impossible (or even impractical) to conduct, so that (b) educational researchers must begin adding these to their investigative repertoires to enhance the scientific credibility of their research and research-based conclusions. Classroom-based research (and its resultant scientific credibility) can also be adversely affected by a variety of real-world plagues, including within-classroom treatment integrity, between-classroom treatment overlap, and construct validity, as well as other measurement issues (e.g., Cook & Campbell, 1979; Nye, Hedges, & Konstantopoulos, 1999). In addition, a variety of external validity caveats—superbly articulated in a persuasive treatise by Dressman (1999)—must be heeded when attempting to extrapolate educational research findings to educational policy recommendations. There can be no denying that in contrast to the independent and dependent variables of the prototypical laboratory experiment, the factors related to school or classroom outcomes are complex and multidimensional. Yet, others have argued compellingly that to understand the variables (and variable systems) that have implications for social policy, randomized experiments should, and can, be conducted in realistic field settings (e.g., Boruch, 1975; Campbell & Boruch, 1975). Here we present a similar argument for more carefully controlled classroombased research on instructional interventions and on other educational prescriptions.
Implementing a Randomized Classroom Trials Study
Is there a need for either smaller or larger scale randomized intervention studies? Have any instructional interventions advanced to the point where they are ready to be evaluated in well-controlled classroom trials? Or, as was alluded to earlier, are such implementation-and-evaluation efforts the sole property of medical research’s clinical trials? Yes, yes, and no, respectively, and the time is ripe to demonstrate it.
A similar research sequence could be followed in moving beyond classroom description, laboratory research, and oneunit-per-intervention studies to help settle the whole-language versus phonemic-awareness training wars in reading instruction (e.g., Pressley & Allington, 1999), to prescribe the most effective classroom-based reading-comprehension techniques (e.g., Pressley et al., 1992), to investigate issues related to optimal instructional media and technologies (e.g., Salomon & Almog, 1998), and the like—the list goes on and on. That is, there is no shortage of randomized classroom-intervention research leads to be explored, in virtually all content domains that promote cognitive or behavioral interventions. (Beyond the classroom, school and institutional trials experiments can help to bolster claims about intervention efforts at those levels.) In addition to a perusal of the usual scholarly syntheses of research, all one needs do is to take a look at something such as What Works (U.S. Department of Education, 1986) for research-based candidates with the potential to have a dramatic positive impact on instructional outcomes, classroom behavior, and general cognitive development. Randomized classroom trials research can provide the necessary credible and creditable evidence for that potential.
Commitment of Federal Funds to Randomized Classroom Trials Research
The notions we have been advancing are quite compatible with Stanovich’s (1998, pp. 54–55, 133–135) discussions of the importance of research progressing from early to later stages, producing, respectively, weaker and stronger forms of causal evidence. The notions are also in synchrony with the final evaluative phase of Slavin’s (1997) recommended design competitions, in which an agency identifies educational problems and research bidders submit their plans to solve them. With respect to that evaluative phase (which roughly corresponds to our randomized classroom trials stage), Slavin (1997) wrote,
Ideally, schools for the third-party evaluations would be chosen at random from among schools that volunteered to use the program being evaluated. For example, schools in a given district might be asked to volunteer to implement a new middle school model. This offer might be made in 5 to 10 districts around the country: some urban, some suburban, some rural, some with language-minority students, some large schools, some small ones, and so on. Fifty schools might be identified. Twenty-five might be randomly assigned to use the program and 25 to serve as controls (and to implement their current programs for a few more years). Control schools would receive extra resources, partly to balance those given to the experimental schools and partly to maintain a level of motivation to serve as control groups. (p. 26)
The random assignment of volunteering schools to the program and control conditions, along with the allocation of additional resources to the control schools, exhibits a concern for the research’s internal validity (see, e.g., Levin & Levin, 1993). Additionally, the random sampling of schools exhibits a concern for the research’s external validity and also permits an investigation of program effectiveness as a function of specific school characteristics. Multiple high-quality randomized school or classroom trials studies of this kind would do much to improve both public and professional perceptions of the low-quality standards that accompany educational research today (e.g., McGuire, 1999; Sabelli & Kelly, 1998; Sroufe, 1997). Incorporating and extending the knowledge base provided by smaller scale Stage 2 empirical studies (e.g., Hedges & Stock, 1983), the decade-long Tennessee Project STAR randomized classroom experiment investigating the effects of class size on student achievement (e.g., Nye et al., 1999) is a prominent example of scientifically credible research that has already begun to influence educational policy nationwide (“Research finds advantages,” 1999). The same can be said of the Success for All randomized schools experiments investigating the effects of systemic reform on student academic outcomes in schools serving traditionally low-achieving student populations (e.g., Slavin, Madden, Dolan, & Wasik, 1996). Of less recent vintage, an illustration of a scientifically credible intervention with educational creditability is Harvard Project Physics, a randomized schools experiment based on a national random sample, in which an innovative high school physics curriculum was carefully implemented and evaluated (e.g., Walberg & Welch, 1972).
Are federal funding agencies willing to support randomized classroom trials ventures? Such ventures appear to be exactly what at least some agencies want, if not demand:
At one end of the continuum, research is defined by researcher questions that push the boundaries of knowledge.At the other end of the continuum, research is defined by large-scale and contextualexperiments,definedbyimplementationquestionsthatframe robust applications. . . . What is needed now, and what NSF is actively exploring, is to move ahead simultaneously at both extremes of the continuum. Basic learning about the process of learning itself—innovative R&D in tackling increasingly complex content and in the tools of science and mathematics education—informs and must be informed by applied, robust, large-scale testbed implementation research. (Sabelli & Kelly, 1998, p. 46)
Thus, in contrast to detractors’ periodic assertions that the medical research model does not map well onto the educational research landscape, we assert that randomized classroom trials studies have much to recommend themselves.
Additional Comments
We conclude this section with five comments. First, we do not mean to imply that randomized classroom trials studies are appropriate for all areas of intervention research inquiry, for they most certainly are not (see, e.g., Eisner, 1999). Systematic observation, rich description, and relationship documentation, with no randomized classroom component, may well suffice for characterizing many classroom processes and behaviors of both practical and theoretical consequence. For the prescription of instructional interventions (e.g., alternative teaching methods, learning strategies, curricular materials) and other school- or other system–based innovations, however, randomized classroom trials studies could go a long way toward responding to former Assistant Secretary of Education McGuire’s (1999) call for rigorous educational research that “readily inform[s] our understanding of a number of enduring problems of practice” (p. 1).
Second, randomized classroom trials studies can be carried out on both smaller and larger scales, depending on one’s intended purposes and resources. The critical issues here are (a) realistic classroom-based interventions that are (b) administered to multiple randomized classrooms. Scientifically credible classroom-based intervention research does not invariably require an inordinate number of classrooms per intervention condition, such as the 50 schools alluded to by Slavin (1997) in the final stage of his aforementioned design competition scenario. Initially, an intervention’s potential might be evaluated with, say, three or four classrooms randomly assigned to each intervention condition. Even with that number of multiple classrooms (and especially when combined with classroom stratification, statistical control, and the specification of relevant within-classroom characteristics), classroombased statistical analyses can be sensibly and sensitively applied to detect intervention main effects and interactions of reasonable magnitudes (e.g., Barcikowski, 1991; Bryk & Raudenbush, 1992; Levin, 1992; Levin & O’Donnell, 1999a; Levin & Serlin, 1993). This statement may come as surprise to those who are used to conducting research based on individuals as the units of treatment administration and analysis. With classrooms as the units, the ability to detect intervention effects is a function of several factors, including the number of classrooms per intervention condition, the number of students per classroom, and the degree of within-classroom homogeneity (both apart from and produced by the intervention; see, e.g., Barcikowski, 1981). Each of these factors serves to affect the statistical power of classroom-based analyses.After an intervention’s potential has been documented through small, controlled, classroom-based experiments (and replications) of the kind alluded to here, more ambitious, larger scale, randomized trials studies based on randomly selected classrooms or schools, consistent with Slavin’s (1997) design competition notions, would then be in order.
Third, if we are to understand the strengths, weaknesses, and potential roles of various modes of empirical inquiry (e.g., observational studies, surveys, controlled laboratory experiments, design experiments), we need an overall model to represent the relationships among them. For Figure 22.1 to be such a model, one must believe that it is possible to have a generalized instructional intervention that can work in a variety of contexts. Testing the comparative efficacy of such an intervention would be the subject of a Stage 3 randomized classroom trials investigation. A substantive example that readily comes to mind is tutoring, an instructional strategy that has been shown to be effective in a variety of student populations and situations and across time (see, e.g., Cohen, Kulik, & Kulik, 1982; O’Donnell, 1998). For those who believe that interventions can only be population and situation specific, a unifying view of the reciprocal contributions of various research methodologies is difficult to promote.
Fourth, along with acknowledging that the classroom is typically a nest of “blooming, buzzing confusion” (Brown, 1992, p. 141), it should also be acknowledged that in the absence of Figure 22.1’s Stage 3 research, the confusion will be in a researcher’s interpreting which classroom procedures or features produced which instructional outcomes (if, indeed, any were produced at all). In that regard, we reiterate that randomized classroom trials research is equally applicable and appropriate for evaluating the effects of singlecomponent, multiple-component, and systemic intervention efforts alike. With the randomized classroom trials stage, at least a researcher will be able to attribute outcomes to the intervention (however tightly or loosely defined) rather than to other unintended or unwanted characteristics (e.g., teacher, classroom, or student effects).
Finally, and also in reference to Brown’s (1992, p. 141) “blooming, buzzing confusion” comments directed at classroom-based research, we note that not all research on teaching and learning is, or needs to be, concerned with issues of teaching and learning in classrooms. Consider, for example, the question of whether musical knowledge and spatial ability foster the development of students’ mathematical skills. Answering that question does not require any classroom-based intervention or investigation. In fact, addressing the question in classroom contexts, and certainly in the manner in which the research has been conducted to date (e.g., Graziano et al., 1999; Rauscher et al., 1997), may serve to obfuscate the issue more than resolve it. Alternatively, one need not travel very far afield to investigate the potential of individually based interventions for ameliorating children’s psychological and conduct disorders. Controlled large-scale assessments of the comparative effectiveness of various drug or behavioral therapies could be credibly managed within the randomized classroom (or community) trials stage of the Figure 22.1 model (see, e.g., COMMIT Research Group, 1995; Goode, 1999; Peterson, Mann, Kealey, & Marek, 2000; Wampold et al., 1997). Adapting Scriven’s (1997, p. 21) aspirin question here, is the individual administration of therapeutic interventions applicable only for treating medical, and not educational, problems?
Closing Trials Arguments
So, educational intervention research, whither goest thou? By the year 2025, will educational researchers still regard such methodologies as the ESP investigation, the demonstration study, and the design experiment as credible evidence producers and regard the information derived from them as “satisficing” (Simon, 1955)? Or are there enough among us who will fight for credible evidence-producing methodologies, contesting incredible claims in venues in which recommendations based on intervention “research” are being served up for either public or professional consumption?
A similar kind of soul searching related to research purposes, tools, and standards of evidence has been taking place in other social sciences academic disciplines as well (e.g., Azar, 1999; Thu, 1999; Weisz & Hawley, 2001). Grinder (1989) described a literal fallout observed in the field of educational psychology as a result of researchers’ perceived differences in purposes: In the 1970s and 1980s many researchers chose to withdraw from educational psychology and head in other disciplinary directions. In the last decade or so we have seen that sort of retreat in at least two kindred professional organizations to the AERA. Perceiving the American Psychological Association as becoming more and more concerned with clinical and applied issues, researchers aligned with the scientific side of psychology helped to form the American Psychological Society (APS). Similarly, International Reading Association researchers and others who wished to focus on the scientific study of reading rather than on reading practitioners’ problems founded a professional organization to represent that focus, the Society for the Scientific Study of Reading. Will history repeat itself, once again, in educational research?
Our message is a simple one: When it comes to recommending or prescribing educational, clinical, and social interventions based on research, standards of evidence credibility must occupy a position of preeminence. The core of the investigative framework we propose here is not new. Many educational researchers and methodologists concerned with the credibility of research-derived evidence and prescriptions have offered similar suggestions for years, if not decades: Harken back to Bereiter’s (1965) trenchant analysis of the situation. Why, then, do we believe it important, if not imperative, for us to restate the case for scientifically credible intervention research at this time? Perhaps it is best summarized in a personal communication received from the educational researcher Herbert Walberg (May 11, 1999): “Live long enough and, like wide ties, you come back in style—this in a day when anecdotalism is the AERA research method of choice.” A frightening state of affairs currently exists within the general domain of educational research and within its individual subdomains. It is time to convince the public, the press, and policy makers alike of the importance of credible evidence derived from CAREfully conducted research, delineating the characteristics critical to both its production and recognition. In this research paper we have taken a step toward that end by first attempting to convince educational/psychological intervention researchers of the same.
Bibliography:
- Abelson, R. P. (1995). Statistics as principled argument. Mahwah, NJ: Erlbaum.
- Angell, M., & Kassirer, J. P. (1998). Alternative medicine: The risks of untested and unregulated remedies. New England Journal of Medicine, 339, 839–841.
- Azar, B. (1999). Consortium of editors pushes shift in child research method. APA Monitor, 30(2), 20–21.
- Barcikowski, R. S. (1981). Statistical power with group mean as the unit of analysis. Journal of Educational Statistics, 6, 267–285.
- Bartlett, F. C. (1932). Remembering: A study in experimental and social psychology. Cambridge, England: Cambridge University Press.
- Bereiter, C. (1965). Issues and dilemmas in developing training programs for educational researchers. In E. Guba & S. Elam (Eds.), Thetrainingandnurtureofeducationalresearchers(pp.95–110). Bloomington, IN: Phi Delta Kappa.
- Bereiter, C. (1994). Implications of postmodernism for science, or, science as progressive discourse. Educational Psychologist, 29, 3–12.
- Boruch, R. F. (1975). On common contentions about randomized field experiments. In R. F. Boruch & H. W. Riecken (Eds.), Experimental testing of public policy (pp. 107–145). Boulder, CO: Westview Press.
- Boyer, E. L. (1990). Scholarship reconsidered: Priorities of the professoriate. Princeton, NJ: Carnegie Foundation.
- Braun, T. M., & Feng, Z. (2001). Optimal permutation tests for the analysis of group randomized trials. Journal of the American Statistical Association, 96, 1424–1432.
- Brown, A. L. (1992). Design experiments: Theoretical and methodological challenges in creating complex interventions in classroom settings. Journal of the Learning Sciences, 2, 141–178.
- Bryk, A. S., & Raudenbush, S. W. (1992). Hierarchical linear models. Newbury Park, CA: Sage.
- Byrne, B., & Fielding-Barnsley, R. (1991). Evaluation of a program to teach phonemic awareness to young children. Journal of Educational Psychology, 83, 451–455.
- Calfee, R. (1992). Refining educational psychology: The case of the missing links. Educational Psychologist, 27, 163–175.
- Campbell, D. T., & Boruch, R. F. (1975). Making the case for randomized assignment to treatments by considering the alternatives: Six ways in which quasi-experimental evaluations in compensatory education tend to underestimate effects. In C.A. Bennett & A.A.Lumsdaine(Eds.),Evaluationandexperiment:Somecritical issues in assessing social programs (pp. 195–296). New York: Academic Press.
- Campbell, D. T., & Stanley, J. C. (1966). Experimental and quasiexperimental designs for research. Chicago: Rand-McNally.
- Chambless, D. L., & Ollendick, T. H. (2001). Empirically supported psychological interventions: Controversies and evidence. Annual Review of Psychology, 52, 685–716.
- Cliff, N. (1983). Some cautions concerning the application of causal modeling methods. Multivariate Behavioral Research, 18, 115– 126.
- Cobb, P., & Bowers, J. (1999). Cognitive and situated learning perspectives in theory and practice. Educational Researcher, 28(2), 4–15.
- Cocco, N., & Sharpe, L. (1993). An auditory variant of eyemovement desensitization in a case of childhood posttraumatic stress disorder. Journal of Behaviour Therapy and Experimental Psychiatry, 24, 373–377.
- Cohen, P. A., Kulik, J. A., & Kulik, C. C. (1982). Educational outcomes from tutoring: A meta-analysis of findings. American Educational Research Journal, 19, 237–248.
- Cole, N. S. (1997). “The vision thing”: Educational research and AERA in the 21st century: Pt. 2. Competing visions for enhancing the impact of educational research. Educational Researcher, 26(4), 13, 16–17.
- Collins, A. (1992). Toward a design science of education. In E. Scanlon & T. O’Shea (Eds.), New directions in educational technology (pp. 15–22). New York: Springer-Verlag.
- COMMIT Research Group. (1995). Community intervention trial for smoking cessation (COMMIT). American Journal of Public Health, 85, 183–192.
- Copeland, W. D. (1991). Microcomputers and teaching actions in the context of historical inquiry. Journal of Educational Computing Research, 7, 421–454.
- Derry, S., Levin, J. R., Osana, H. P., Jones, M. S., & Peterson, M. (2000). Fostering students’ statistical and scientific thinking: Lessons learned from an innovative college course. American Educational Research Journal, 37, 747–773.
- Donner, A., & Klar, N. (2000). Design and analysis of cluster randomization trials in health research. New York: Oxford University Press.
- Donmoyer,R.(1993).Yes,butisitresearch?EducationalResearcher, 22(3), 41.
- Donmoyer, R. (1996). Educational research in an era of paradigm proliferation: What’s a journal editor to do? Educational Researcher, 25(2), 19–25.
- Doyle, W., & Carter, K. (1996). Educational psychology and the education of teachers: A reaction. Educational Psychologist, 31, 23–28.
- Dressman, M. (1999). On the use and misuse of research evidence: Decoding two states’ reading initiatives. Reading Research Quarterly, 34, 258–285.
- Duffy, G. R., Roehler, L. R., Sivan, E., Rackliffe, G., Book, C., Meloth, M. S., Vavrus, L. G., Wesselman, R., Putnam, J., & Bassiri, D. (1987). Effects of explaining the reasoning associated with using reading strategies. Reading Research Quarterly, 22, 347–368.
- Eisner, E. (1999). Rejoinder: A response to Tom Knapp. Educational Researcher, 28(1), 19–20.
- Elashoff, J. D. (1969). Analysis of covariance: A delicate instrument. American Educational Research Journal, 6, 381–401.
- Goode, E. (1999, March 19). New and old depression drugs are found equal. New York Times, A1, A16.
- Graziano, A. B., Peterson, M., & Shaw, G. L. (1999). Enhanced learning of proportional math through music training and spatialtemporal training. Neurological Research, 21, 139–152.
- Greenwald, R. (1999). Eye movement desensitization and reprocessing (EMDR) in child and adolescent psychotherapy. Northvale, NJ: Jason Aronson.
- Grinder, R. E. (1989). Educational psychology: The master science. In M. C. Wittrock & F. Farley (Eds.). The future of educational psychology: The challenges and opportunities (pp. 3–18). Hillsdale, NJ: Erlbaum.
- Gross, P. R., Levitt, N., & Lewis, M. W. (1997). The flight from science and reason. Baltimore: Johns Hopkins University Press.
- Halpern, D. F. (1996). Thought & knowledge: An introduction to critical thinking (3rd ed.). Mahwah, NJ: Erlbaum.
- Hedges, L. V., & Stock, W. (1983). The effects of class size: An examination of rival hypotheses. American Educational Research Journal, 20, 63–85.
- Hitt, J. (2001, December 9). Evidence-based medicine. In “The year in ideas,” New York Times Magazine (Section 6).
- Hooper, J. (1999). A new germ theory. Atlantic Monthly, 283(2), 41–53.
- Huitema, B. E. (1980). The analysis of covariance and alternatives. New York: Wiley.
- Jaeger, R. M. (Ed.). (1988). Complementary methods for research in education. Washington, DC: American Educational Research Association.
- Jaeger, R. M., & Bond, L. (1996). Quantitative research methods and design. In D. C. Berliner & R. C. Calfee (Eds.), Handbook of educational psychology (pp. 877–898). New York: Macmillan.
- Kaestle, C. F. (1993). The awful reputation of education research. Educational Researcher, 22(1), 23–31.
- Kazdin, A. E. (1981). Drawing valid inferences from case studies. Journal of Consulting and Clinical Psychology, 49, 183–192.
- Kazdin, A. E. (1998). Research design in clinical psychology (3rd ed.). Boston: Allyn & Bacon.
- Koehler, M. J., & Levin, J. R. (1998). Regulated randomization: A potentially sharper analytical tool for the multiple-baseline design. Psychological Methods, 3, 206–217.
- Krathwohl, D. R. (1993). Methods of educational and social science: An integrated approach. White Plains, NY: Longman.
- Kratochwill, T. R. (1985). Case study research in school psychology. School Psychology Review, 14, 204–215.
- Kratochwill, T. R., & Levin, J. R. (Eds.). (1992). Single-case research design and analysis: New developments for psychology and education. Hillsdale, NJ: Erlbaum.
- Kratochwill, T. R., Mott, S. E., & Dodson, C. L. (1984). Case study and single-case research in clinical and applied psychology. In A. S. Bellack & M. Hersen (Eds.), Research methods in clinical psychology (pp. 55–99). New York: Pergamon
- Kratochwill, T. R., & Stoiber, K. C. (2000). Empirically supported interventions and school psychology: Pt. 2. Conceptual and practical issues. School Psychology Quarterly, 15, 233–253.
- Kratochwill, T. R., & Stoiber, K. C. (Eds.). (2001). Procedural and coding manual for review of evidence-based interventions. Task Force on Evidence-Based Interventions in School Psychology. Division 16 of the American Psychological Association and the Society for the Study of School Psychology. Available from Thomas R. Kratochwill, School Psychology Program, 1025 West Johnson St., University of Wisconsin-Madison, Madison, WI 53706–1796.
- Kratochwill, T. R., & Stoiber, K. C. (in press). Evidence-based interventions in school psychology: Conceptual foundations of the Procedural and Coding Manual of Division 16 and the Society for the Study of School Psychology Task Force. School Psychology Quarterly.
- Labaree, D. F. (1998). Educational researchers: Living with a lesser form of knowledge. Educational Researcher, 27(8), 4–12.
- Levin, J. R. (1985). Some methodological and statistical “bugs” in research on children’s learning. In M. Pressley & C. J. Brainerd (Eds.), Cognitive learning and memory in children (pp. 205– 233). New York: Springer-Verlag.
- Levin, J. R. (1992). On research in classrooms. Mid-Western Educational Researcher, 5, 2–6, 16.
- Levin, J. R. (1994). Crafting educational intervention research that’s both credible and creditable. Educational Psychology Review, 6, 231–243.
- Levin, J. R. (1997a). Overcoming feelings of powerlessness in aging researchers: A primer on statistical power in analysis of variance designs. Psychology and Aging, 12, 84–106.
- Levin, J. R. (1997b, March). Statistics in research and in the real world. Colloquium presentation, Department of Psychology, University of California, San Diego.
- Levin, J. R., & Levin, M. E. (1993). Methodological problems in research on academic retention programs for at-risk minority college students. Journal of College Student Development, 34, 118–124.
- Levin, J. R., & O’Donnell, A. M. (1999a). Educational research’s credibility gaps, in closing. Issues in Education: Contributions from Educational Psychology, 5, 279–293.
- Levin, J. R., & O’Donnell, A. M. (1999b). What to do about educational research’s credibility gaps? Issues in Education: Contributions from Educational Psychology, 5, 177–229.
- Levin, J. R., & O’Donnell, A. M. (2000). Three more cheers for credible educational research! Issues in Education: Contributions from Educational Psychology, 6, 181–185.
- Levin, J. R., & Peterson, P. L. (1984). Classroom aptitude-by-treatment interactions: An alternative analysis strategy. Educational Psychologist, 19, 43–47.
- Levin, J. R., & Robinson, D. H. (1999). Further reflections on hypothesis testing and editorial policy for primary research journals. Educational Psychology Review, 11, 143–155.
- Levin, J. R., & Serlin, R. C. (1993, April). No way to treat a classroom: Alternative units-appropriate statistical strategies. Paper presented at the annual meeting of the American Educational Research Association, Atlanta, GA.
- Levin, J. R., & Wampold, B. E. (1999). Generalized single-case randomization tests: Flexible analyses for a variety of situations. School Psychology Quarterly, 14, 59–93.
- Levin, M. E., Levin, J. R., & Scalia, P. A. (1997). What claims can a comprehensive college program of academic support support? Equity & Excellence in Education, 30, 71–89.
- Lindquist, E. F. (1940). Sampling in educational research. Journal of Educational Psychology, 31, 561–574.
- Lipsey, M. W., & Cordray, D. S. (2000). Evaluation methods for social intervention. Annual Review of Psychology, 51, 345– 375.
- Loftus, E. (1998). Who is the cat that curiosity killed? APS Observer, 11(9), 3, 27.
- Marascuilo, L. A., & Busk, P. L. (1988). Combining statistics for multiple-baseline AB and replicated ABAB designs across subjects. Behavioral Assessment, 10, 1–28.
- Mayer, R. E. (1993). Outmoded conceptions of educational research. Educational Researcher, 22,
- McDonald, L., Kratochwill, T., Levin, J., & Youngbear Tibbits, H. (1998, August). Families and schools together: An experimental analysis of a parent-mediated intervention program for at-risk American Indian children. Paper presented at the annual meeting of the American Psychological Association, San Francisco.
- McGuire, K. (1999). 1999 request for proposals. Washington, DC: U.S. Department of Education, Office of Educational Research and Improvement.
- Muthen, B. (1989). Teaching students of educational psychology new sophisticated statistical techniques. In M. C. Wittrock & F. Farley (Eds.). The future of educational psychology: The challenges and opportunities (pp. 181–189). Hillsdale, NJ: Erlbaum.
- Nantais, K. M., & Schellenberg, E. G. (1999). The Mozart effect: An artifact of preference. Psychological Science, 10, 370–373.
- National Institutes of Health. (1998). Taking part in clinical trials: What cancer patients need to know (NIH Publication No. 984250). Washington, DC: Author.
- National Reading Panel. (2000). Report of the National Reading Panel: Teaching children to read: An evidence-based assessment of the scientific research literature on reading and its implications for reading instruction: Reports of the subgroups. Rockville, MD: NICHD Clearinghouse.
- National Research Council. (2001). Scientific inquiry in education (R. J. Shavelson & L. Towne, Eds). Washington, DC: National Academy Press.
- Needels, M. C., & Knapp, M. S. (1994). Teaching writing to children who are underserved. Journal of Educational Psychology, 86, 339–349.
- Nye, B., Hedges, L. V., & Konstantopoulos, S. (1999). The effects of small classes on academic achievement: The results of the Tennesseeclasssizeexperiment.Unpublishedmansuscript,Tennessee State University.
- O’Donnell, A. M. (1998, February). Peer tutoring: A review of the research on an enduring instructional strategy. Colloquium presentation, Center for Assessment, Instruction, and Research, Fordham University, New York.
- O’Donnell, A. M., & Levin, J. R. (2001). Educational psychology’s healthy growing pains. Educational Psychologist, 36, 73–82.
- Page, E. B. (1965, February). Recapturing the richness within the classroom. Paper presented at the annual meeting of the American Educational Research Association, Chicago.
- Peckham, P. D., Glass, G. V., & Hopkins, K. D. (1969). The experimental unit in statistical analysis. Journal of Special Education, 3, 337–349.
- Peterson, A. V., Jr., Mann, S. L., Kealey, K. A., & Marek, P. M. (2000). Experimental design and methods for school-based randomized trials: Experience from the Hutchinson Smoking Prevention Project (HSPP). Controlled Clinical Trials, 21, 144–165.
- Piano lessons, computer may help math skills. (1999, March 15). Deseret News.
- Platt, J. R. (1964). Strong inference. Science, l46, 347–353.
- Pressley, M., & Allington, R. (1999). What should reading instructional research be the research of? Issues in Education: Contributions From Educational Psychology, 5, 1–35.
- Pressley, M., El-Dinary, P. B., Gaskins, I., Schuder, T., Bergman, L., Almasi, J., & Brown, R. (1992). Beyond direct explanation: Transactional instruction of reading comprehension strategies. Elementary School Journal, 92, 513–555.
- Rauscher, F. H., Shaw, G. L., Levine, L. J., Wright, E. L., Dennis, W. R., & Newcomb, R. L. (1997). Music training causes longterm enhancement of preschool children’s spatial-temporal reasoning. Neurological Research, 19, 2–8.
- Research finds advantages in classes of 13 to 17 pupils. (1999, April 30). New York Times, A23.
- Romberg, T. A. (1992). Perspectives on scholarship and research methods. In D. A. Grouws (Ed.), Handbook of research on mathematics teaching and learning (pp. 49–64). New York: Macmillan.
- Sabelli, N. H., & Kelly, A. E. (1998). The NSF Learning and Intelligent Systems research initiative: Implications for educational research and practice. Educational Technology, 38(2), 42–46.
- Saigh, P. A. (1987a). In vitro flooding of an adolescent’s posttraumatic stress disorder. Journal of Clinical Child Psychology, 16, 147–150.
- Saigh, P. A. (1987b). In vitro flooding of a 6-year-old boy’s posttraumatic stress disorder. Behaviour Research and Therapy, 24, 685–689.
- Saigh, P. A. (1989). The development and validation of the Children’s Posttraumatic Stress Disorder Inventory. International Journal of Special Education, 4, 75–84.
- P. A. (in press). The cognitive-behavioral treatment of childadolescent posttraumatic stress disorder. In S. E. Brock & P. Lazarus (Eds.), Best practices in school crisis prevention and intervention. Bethesda, MD: National Association of School Psychologists.
- Saigh, P. A., Yasik, A. E., Oberfield, R. A., & Inamdar, S. C. (1999). Behavioral treatment of child-adolescent posttraumatic stress disorder. In P. A. Saigh & J. D. Bremner (Eds.), Posttraumatic stress disorder: A comprehensive text (pp. 354–375). Boston: Allyn & Bacon.
- Salomon, G. (1995). Reflections on the field of educational psychology by the outgoing journal editor. Educational Psychologist, 30, 105–108.
- Salomon, G., & Almog, T. (1998). Educational psychology and technology: A matter of reciprocal relations. Teachers College Record, 100, 222–241.
- Scriven, M. (1960). The philosophy of science in educational research. Review of Educational Research, 30, 422–429.
- Scriven, M. (1997). “The vision thing”: Educational research and AERA in the 21st century: Pt. 1. Competing visions of what educational researchers should do. Educational Researcher, 26(4), 19–21.
- Shadish, W. R., Cook, T. D., & Campbell, D. T. (2002). Experimental and quasi-experimental designs for generalized causal inference. Boston: Houghton Mifflin.
- Simon, H. A. (1955). A behavioral model of rational choice. Quarterly Journal of Economics, 69, 99–118.
- Slavin, R. E. (1997). Design competitions: A proposal for a new federal role in educational research and development. Educational Researcher, 26(1), 22–28.
- Slavin, R. E. (1999). Yes, control groups are essential in program evaluation:AresponsetoPogrow.EducationalResearcher,28(3), 36–38.
- Slavin, R. E., Madden, N. A., Dolan, L. J., & Wasik, B. A. (1996). Every child, every school: Success for All. Thousand Oaks, CA: Corwin.
- Sroufe, G. E. (1997). Improving the “awful reputation” of education research. Educational Researcher, 26(7), 26–28.
- Stanovich, K. (1998). How to think straight about psychology (5th ed.). New York: Longman.
- Stanovich, K. E. (1999). Educational research at a choice point. Issues in Education: Contributions from Educational Psychology, 5, 267–272.
- Steele, K. M., Bass, K. E., & Crook, M. D. (1999). The mystery of the Mozart effect: Failure to replicate. Psychological Science, 10, 366–369.
- Stevens, R. J., Slavin, R. E., & Farnish, A. M. (1991). The effects of cooperative learning and direct instruction in reading comprehension strategies on main idea identification. Journal of Educational Psychology, 83, 8–16.
- Stoiber, K. C., & Kratochwill, T. R. (2000). Empirically supported interventions in schools: Rationale and methodological issues. School Psychology Quarterly, 15, 75–115.
- Suter, L. (1999, April). Research methods in mathematics and science research: A report of a workshop. Symposium presented at the annual meeting of the American Educational Research Association, Montreal, Quebec, Canada.
- Thu, K. M. (1999). Anthropologists should return to the roots of their discipline. Chronicle of Higher Education, 45(34), A56.
- Torgesen, J. K., Morgan, S. T., & Davis, C. (1992). Effects of two types of phonological awareness training on word learning in kindergarten children. Journal of Educational Psychology, 84, 364–370.
- Townsend, M. A. R., Hicks, L., Thompson, J. D. M., Wilton, K. M., Tuck, B. F., & Moore, D. W. (1993). Effects of introductions and conclusions in assessment of student essays. Journal of Educational Psychology, 85, 670–678.
- Uchitelle, L. (1999, April 20). A real-world economist: Krueger and the empiricists challenge the theorists. New York Times, C1, C10.
- S. Department of Education. (1986). What works. Washington, DC: Author.
- S. Government Accounting Office. (1997). Head Start: Research provides little information on impact of current program. Washington, DC: Author.
- Walberg, H. J., & Welch, W. W. (1972). A national experiment in curriculum evaluation. American Educational Research Journal, 9, 373–384.
- Walker, V. S. [Speaker]. (1999, April). Research training in education:Whataretheessentialsandcanweagree?(CassetteRecording No. 2.39). Washington, DC:American Educational Research Association.
- Wampold, B. E., Mondin, G. W., Moody, M., Stich, F., Benson, K., & Ahn, H. (1997). A meta-analysis of outcome studies comparing bona fide psychotherapies: Empirically, “All must have prizes.” Psychological Bulletin, 122, 203–215.
- Wampold, B. E., & Worsham, N. L. (1986). Randomization tests for multiple-baseline designs. Behavioral Assessment, 8, 135–143.
- Weisz, J. R., & Hawley, K. (2001, June). Procedural and coding manualforidentificationofbeneficialtreatments.Draftdocument of the Committee on Science and Practice Society for Clinical Psychology, Division 12, American Psychological Association, Washington, DC.
- Whitehurst, G. J., Epstein, J. N., Angell, A. L., Payne, A. C., Crone, D. A., & Fischel, J. E. (1994). Outcomes of an emergent literacy intervention in Head Start. Journal of Educational Psychology, 86, 542–555.
- Winner, E., & Hetland, L. (1999, March 4). Mozart and the S.A.T.’s. New York Times, A25.
- Wittrock, M. C. (1994). An empowering conception of educational psychology. Educational Psychologist, 27, 129–141.
- Wong, L. Y.-S. (1995). Research on teaching: Process-product research findings and the feeling of obviousness. Journal of Educational Psychology, 87, 504–511.
ORDER HIGH QUALITY CUSTOM PAPER

Always on-time

Plagiarism-Free

100% Confidentiality